Reminder — no audio for these posts. Previous Issues can be found here.
To start, I wanted to make sure folks are aware of one of my more notable side-projects this year -- a short textbook on RLHF. Eventually, I want to publish this as a physical book, but it is a digital-first book with a nice website and PDF available. It's clearly not complete if you start poking around, but I'm contributing most weeks and want to have a beta version by the end of the year. As I get more text written, folks reading, telling me what to add, and fixing typos or formatting problems directly on GitHub will go a long way. I’ll send major updates here.
I got a few fun comments in response to my post on How Scaling Changes Model Behavior. The core argument was how all that is changing is the log probs are shifting slightly, which we don't know how that translates into value creation. Andrew Carr pointed out this awesome sentence in the recent Meta VideoGen paper that showed a clear relationship between scaling and human preferences.
We observe that the validation loss is well correlated with human evaluation results as the later checkpoints with lower validation loss perform better in the evaluations.
Maybe scaling is just messy for text models?
Models
Qwen 2.5
The Qwen 2.5 models were launched about a month ago and are very competitive with the Llama 3.1 models. My bet is that most of the reason that Llama is adopted so much more is due to the usual mix of a) License terms, b) Meta being better at getting the word out, and c) Meta being better are supporting developers.
Regardless, these models are extremely strong. A month later, when Mistral announced their two small models, Qwen 2.5 was the model the community was most frustrated they didn't compare with.
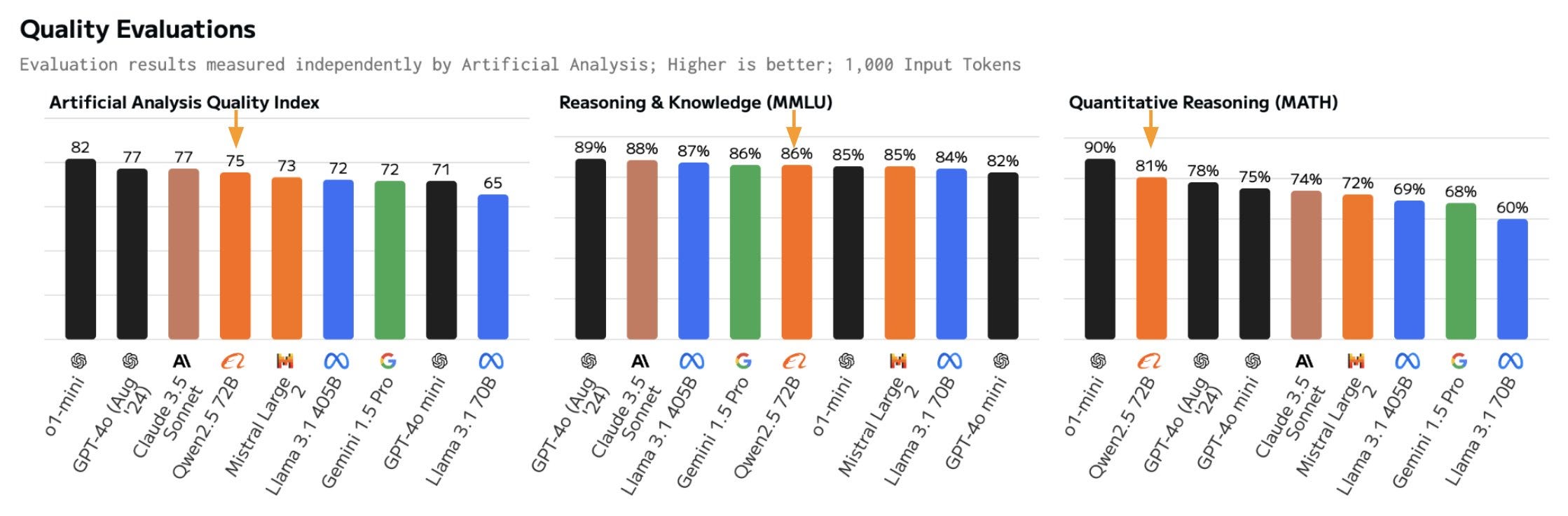
The Qwen 2.5 72B instruct model is above the original Gemini-1.5-Pro model from Google and below the Llama 3.1 405B Instruct model. Another eval analysis is available from Artifical Analysis.
The two models of interest are the Qwen2.5-72B-Instruct and Qwen2.5-Math-RM-72B by Qwen. Good reward models are far and few between these days, especially for Math. The Instruct model has been scoring extremely high on evals and some vibe checks.
Onto the normal programming.
Base
Zamba2-7B by Zyphra: This seems to be the strongest 7B hybrid architecture language model we have to date (with open weights). Mostly, these are important to keep an eye on, but not a ton of use I know of other than by researchers and very niche domains.
EuroLLM-1.7B by utter-project: A multilingual base model (instruct versions available too) trained on all the European languages. Eventually, I expect Llama to be the default here, ironically.
Instruct
Mistral-Small-Instruct-2409 and Ministral-8B-Instruct-2410 by mistralai: Nothing exceptional about Mistral's post-training, but their models are consistently solid. Small = 22.2B for Mistral. I'd like them to share more, but in the meantime, they're the default for plenty of people.
gemma-2-9b-it-SimPO by princeton-nlp: A very impressive open weights model based on ChatBotArena performance. Not many fine-tunes by academics that outperform bigger models in their class. They trained with their own version of ArmorRM, which I've covered in previous issues.
GRIN-MoE by microsoft: A new MoE model series from Microsoft. It has some architecture tweaks, such as SparseMixer-v2, but it isn't clear what the differentiator is (like Phi).
Llama-3.1-Nemotron-70B-Instruct-HF by nvidia: A model Nvidia recently fine-tuned that scored extremely high on LLM-as-a-judge evals like MT Bench and ArenaHard. The final jury will be LMSYS, but it's exciting to see fine tunes continuing to climb upwards. This was trained on the HelpSteer2 data. At the same time, we need actually good models and not just high evaluations.
SuperNova-Medius by arcee-ai: A fine-tune of Qwen 2.5-14B-Instruct that is distilled from a mix of Llama 3.1-405B and Qwen 2.5-72B-Instruct with a "cross-architecture distillation pipeline." I wish it was clearer what that means.
Multimodal
Janus-1.3Bby deepseek-ai: Deepseek released a new codebase, paper, and model, Janus-1.3B, which is a new image+text input and output model. This seems to cover everything — new architecture, data, and fine-tuning practices. Note, that these outputs are not interleaved, so it is either text or image outputs in blocks.
Ovis1.6-Gemma2-9B by AIDC-AI: Another slightly different late fusion architecture for visual language models.
NVLM-D-72B by nvidia: Nvidia has entered the VLM game! Performance isn't crazy good, but good to have more options.
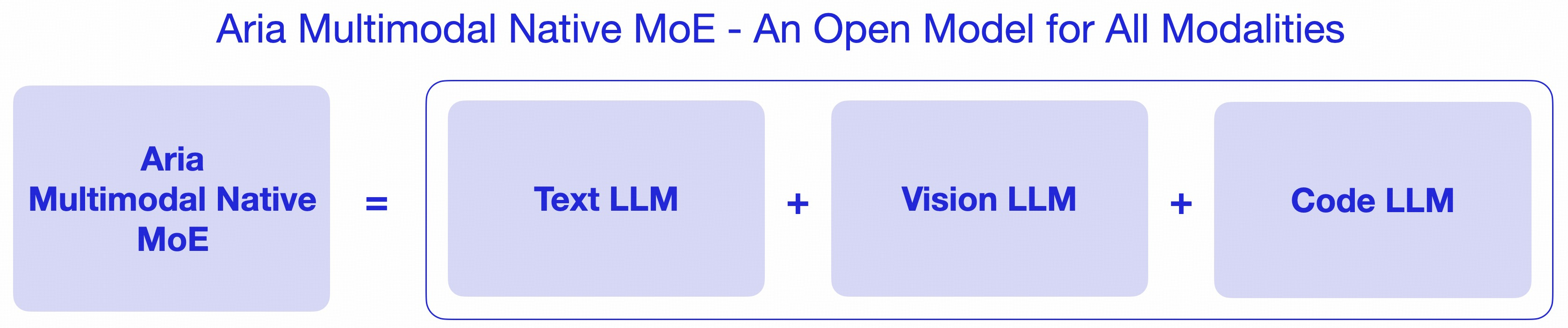
Aria by rhymes-ai: A new architecture for multimodal models where the vision encoder is trained natively and not just late-fusion: "Aria processes text, images, video, and code all at once, without needing separate setups for each type, demonstrating the advantages of a multimodal native model." The performance is very strong, but I'm annoyed they didn't include comparisons to Molmo at launch.
Speech
whisper-large-v3-turbo by openai: The new default automatic speech recognition model. It's great that OpenAI can release it.
Starting from a text language model backbone, Moshi generates speech as tokens from the residual quantizer of a neural audio codec, while modeling separately its own speech and that of the user into parallel streams. This allows for the removal of explicit speaker turns, and the modeling of arbitrary conversational dynamics. Moshi also predicts time-aligned text tokens as a prefix to audio tokens. This “Inner Monologue” method significantly improves the linguistic quality of generated speech and provides streaming speech recognition and text-to-speech. As a result, Moshi is the first real-time full-duplex spoken large language model, with a theoretical latency of 160ms, 200ms in practice.