

Latest open artifacts (#10): New DeepSeek R1 0528!, more permissive licenses, everything as a reasoner, and from artifacts to agents
Artifacts Log 10.
A consistent trend over the last few months has been in the surge of Chinese models with permissive licenses, which has been translating into improvements in the licenses used by other open models. The major players in the Western ecosystem — Meta’s Llama and Google’s Gemma — are yet to do this, but pressure is building.
Mirroring this, we’re seeing far more Qwen finetunes than Llama. Llama, for it’s first 3 versions, was by far and away the leading model for fine-tuners. “Qwen as the default” is not only the view of other Chinese companies, but it is championed by many smaller American startups looking to break through wit hstrong models. While Qwen2.5, Qwen2.5-VL and QwQ are the leading base models, we also see first models based on Qwen3.
These trends are on top of the transition we’ve seen wrapping up on top of the entire industry where reasoning models are the default. GRPO is still the most common algorithm in practice (see our research overview for expansions of the method).
A trend that is beginning, and one that will take longer, is that leading AI releases are much more often about tools than models alone. From Claude Code to OpenAI’s Codex (agent) and Gemini’s Jules, open replications of these systems will be much slower. The open systems will need to take on different forms in order to take the benefits of open models that can be swapped and iterated upon, all of which we hope to highlight in future issues.
Our Picks
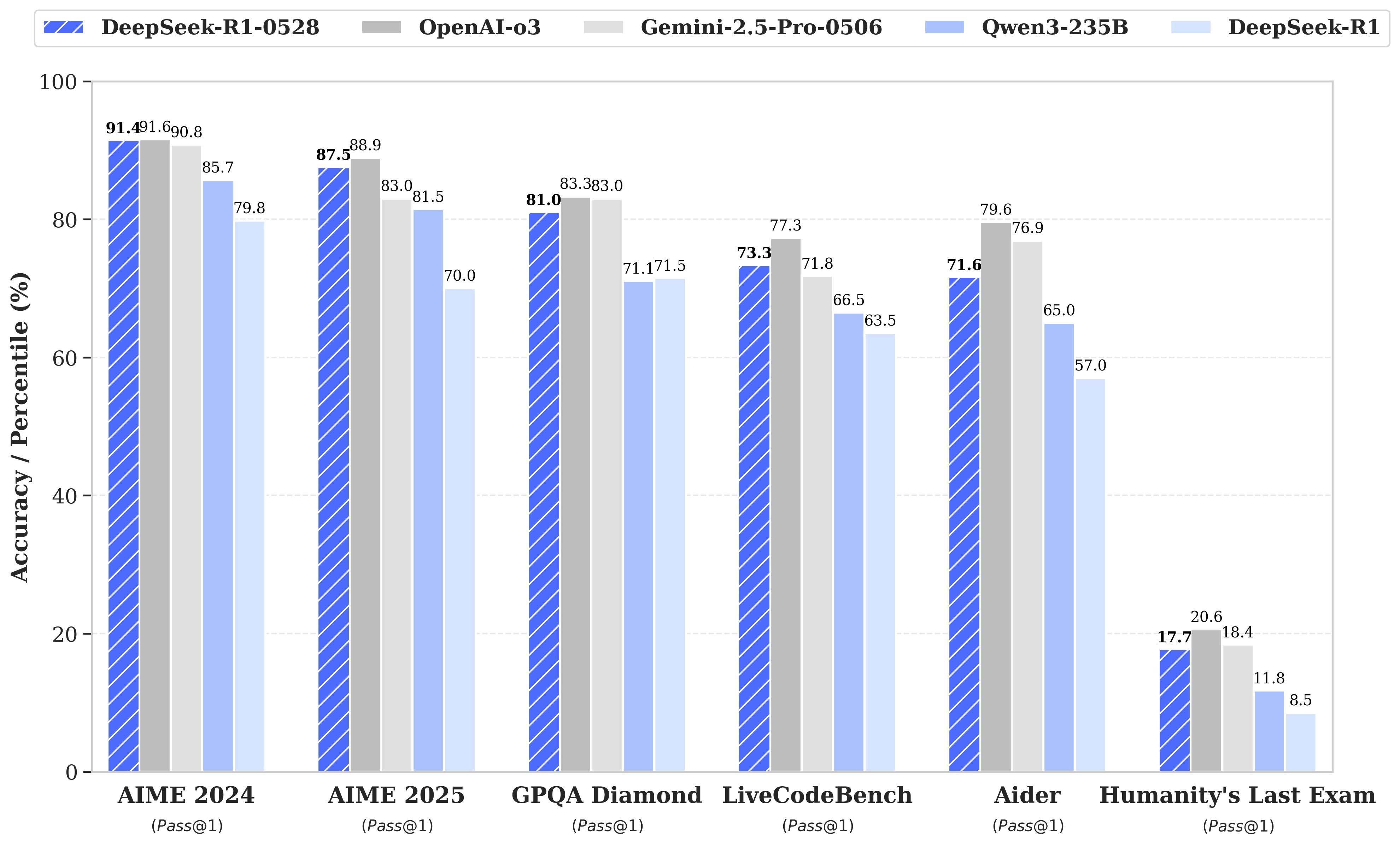
DeepSeek-R1-0528 by deepseek-ai: DeepSeek updated their R1 reasoning model. The model card has not a lot of details (more compute + algorithmic improvements), but the benchmarks show that the whale is yet again at the frontier, rivaling closed models.
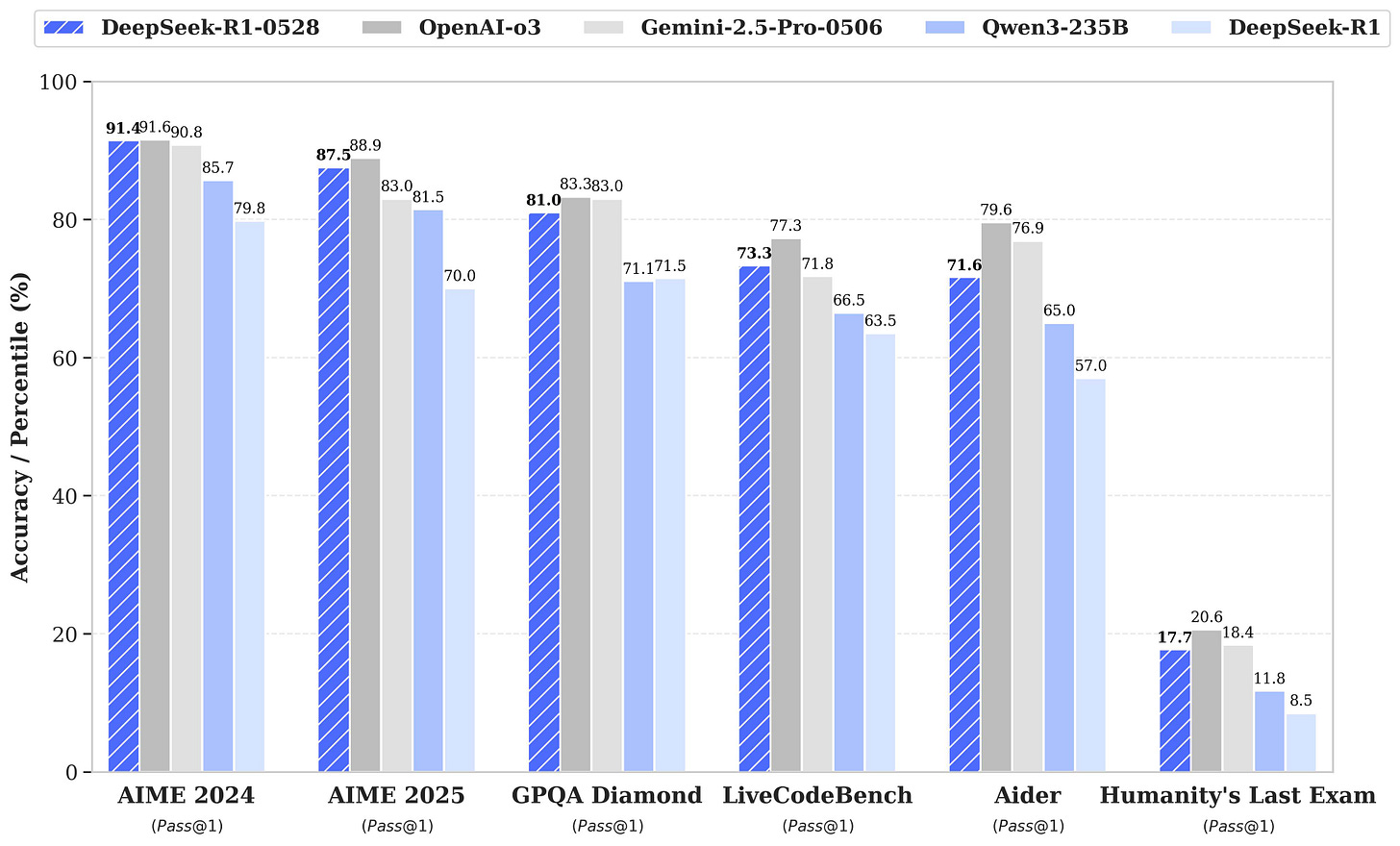
From the model card. Even more exciting as we enter the agentic era is the support for tools. R1 is close to the frontier in popular function-calling benchmarks as well:

Figure made by Interconnects, using the lab-reported numbers for tau-bench and the leaderboard numbers for BFCL. In my quick tests it seems like the new R1 at least has the same distinctive character, but could be even more clever. Here’s an example:

Another example is it seeming to do better on the search APIs (at least what is built into OpenRouter), boosted by the new tool-calling capabilities.

This new version of R1 is much less likely to start every reasoning chain with “Okay,” which should be good for diversity and token efficiency.
And, to top it all off: They also used the new R1 thinking traces to fine-tune DeepSeek-R1-0528-Qwen3-8B, boosting scores significantly in math benchmarks.
For more, see DeepSeek’s announcement or Artificial Analysis’s scores.
Skywork-R1V2-38B by Skywork: Skywork, a Singaporean startup, has been around for some time as a solid smaller contributor to the open ecosystem, but their pace of (open) model releases picked up recently. In the last episode, we featured their math reasoning model and their video generation model. They also have closed models, such as Mureka for song generation or an agent platform to rival Manus. R1V2 is one of the few open multimodal reasoning models. They use GRPO and Mixed Preference Optimization (MPO) to train the model, rivaling the performance of closed models such as Gemini 2.0 Flash or GPT-4o-mini.
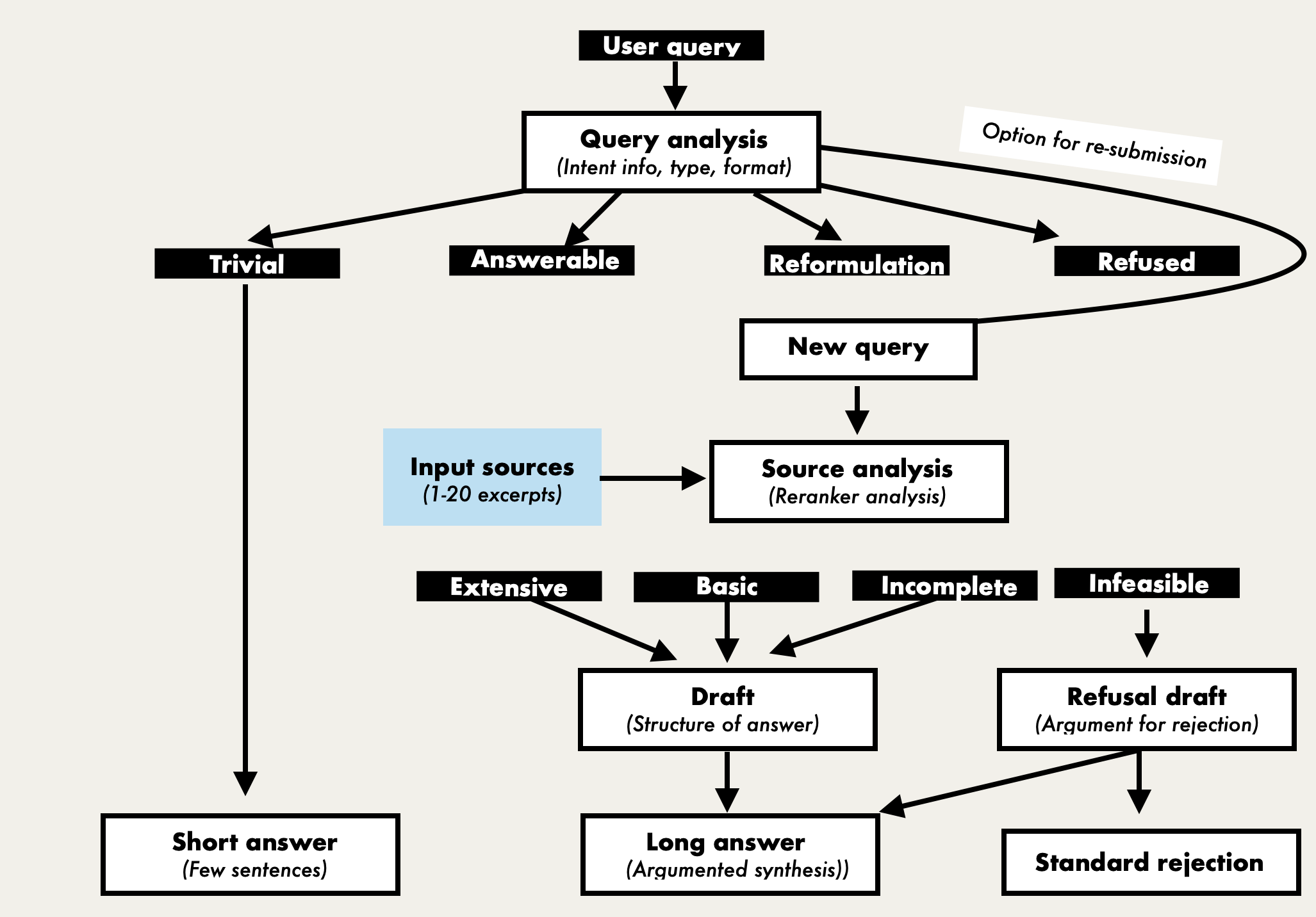
Pleias-RAG-1B by PleIAs: A small model trained for RAG. It can reason whether the query is sufficient to be answered, reformulate queries if needed and analyze the sources, which usually needs multiple models or calls to a model; it can also provide citations within the answer, similar to the Anthropic API. It is also multilingual, trained on permissive data and released under Apache 2.0.

INTELLECT-2 by PrimeIntellect: After INTELLECT-1, the globally pre-trained 10B model on 1T tokens, the PI team is tackling globally decentralized post-training. This model, based on QwQ 32B, is an impressive technical achievement. Their technical report goes into more detail.
comparia-conversations by ministere-culture: The French government runs a chatbot arena, similar to LMArena, where users can chat with two chatbots at once and then click the answer they prefer. Aside from the critique of LMArena, the French version is predominantly used by French citizens and not used as a testing ground for pre-release models. This dataset consists of 175K conversations from thousands of users and PII-redacted, offering interesting insights into non-English preferences and model strengths.




Links
A wonderful essay, AI Horseless Carriages, highlighted the bizarre way that places like Gmail are forcing AI intro products that make the tasks we want to do harder.
Lilian Weng wrote a phenomenal blog post about reasoning models. Friend of the pod, Ross Taylor, wrote a more focused (shorter) one too.
Latent.Space had a good post on how the GPT-4o sychophancy fiasco shows that OpenAI is barking up the wrong tree with their personality, at least if the goal is productivity.
Natasha Jaques gave a nice more general audience talk on trends in AI. It covers normal techniques like RLHF and LLMs but with new flavors added in.
Tyler Cowen wrote In defense of an online life, which really resonated with us on how relationships can thrive in different ways online.
This conversation between Jony Ive and Patrick Collison is one of the best dives into what it means to make “good products” in the modern world.
A bill was somewhat quietly passed that helps clamp down on nonconsensual deepfakes — one of the biggest AI risks accelerated by open models. This is a step in the right direction, but can only work to ban them as well as anything online can be banned — partially.
Will Brown gave a talk about open problems in multi-turn and agentic RL.
This post dives deep into the economics of LLM inference.
Vlad Feinberg published his slides discussing his work on Gemini Flash Pretraining.
Reasoning
Models
DeepSeek-R1T-Chimera by tngtech (friends of the pod): A model merge of DeepSeek R1 and DeepSeek V3. It works surprisingly well, resulting in a model that has shorter CoTs and thus is faster to run, while still being more capable than just using V3. Even more surprising: The merged model refuses fewer requests than both V3 and R1.

art-e-008 by OpenPipe: A LoRA adapter for Qwen2.5 14B to act as an email research agent. It was trained with GRPO on the infamous Enron email dataset, with questions and answers being generated by GPT-4.1. The writeup goes into more detail.
MiMo-7B-RL by XiaomiMiMo: Even Xiaomi has started releasing open models. Their first model series doesn't have to hide, following the DeepSeek playbook: Multi-token prediction, an RL-only model and an SFT->RL model. All models (Base, RL-only, SFT-only, SFT->RL) are available under the MIT license.
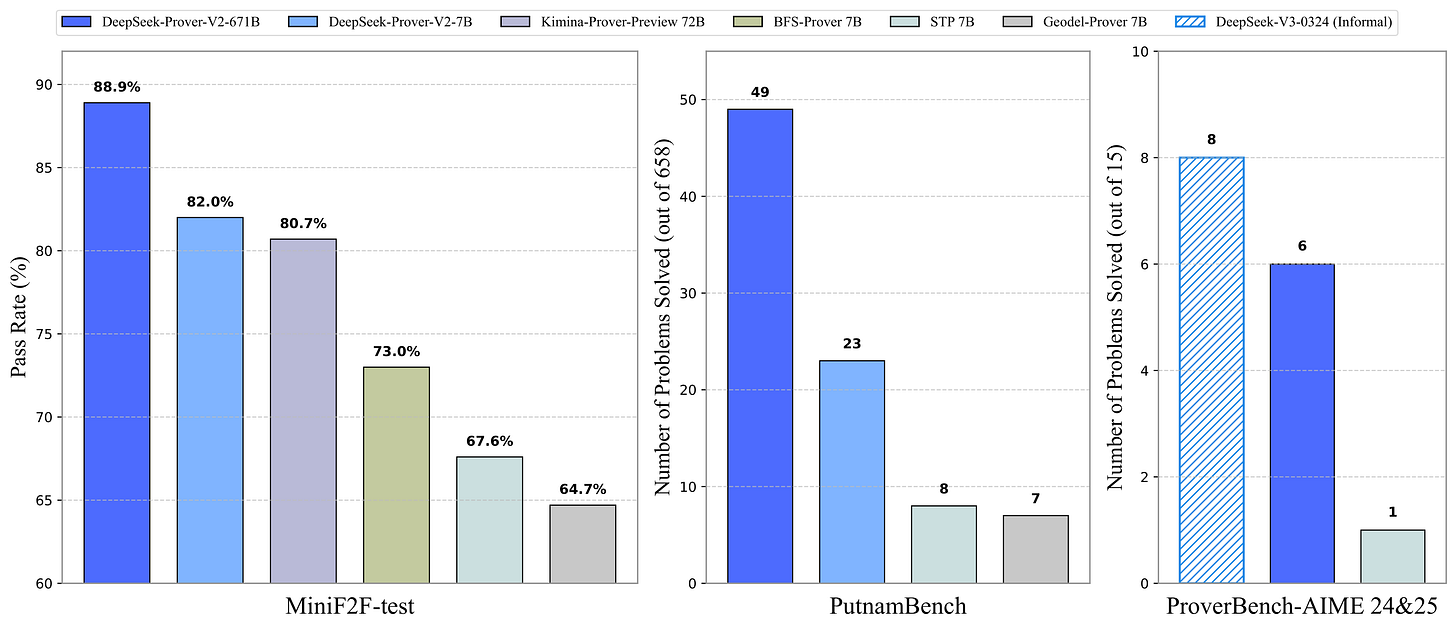
DeepSeek-Prover-V2-671B by deepseek-ai: An updated version of the Prover series by DeepSeek, building upon V3. They also used a smaller 7B Prover model (which, of course, is also open-sourced) to search for subgoals in proofs. The resulting model shatters proof-related benchmarks, but this is expected from DeepSeek.
Phi-4-reasoning-plus by microsoft: Phi also joined the ranks of the reasoning models. The "plus" variant uses GRPO on top of an SFT model. We found the model surprisingly capable in our testing considering both the size and the reputation of the Phi series as benchmark-maxers.
AceReason-Nemotron-14B by nvidia: Building upon R1-Qwen 14B, AceReason uses two RL phases: One exclusively for math, followed by one for code. Like others they use GRPO.
Sarvam-M by sarvamai: A hybrid reasoning model (on/off) based on Mistral-Small. It focuses on Indian languages.
Cosmos-Reason1-7B by nvidia: Multimodal model for robotic tasks.
OpenCodeReasoning-Nemotron-32B-IOI by nvidia: A reasoning model based on distilled R1 traces.
OpenMath-Nemotron-32B by nvidia: A math model, based on Qwen 32B. The paper goes into more detail for the data creation, which needed a lot of work to get another model (LIMO-Qwen 32B) to output proper tool calls. They also used a lot of different reasoning models to create the data.
Elastic-Reasoning by Salesforce: A series of models that have two different thinking budgets: One for thinking, one for the solution phase. The models are trained with a budget-constrained rollout strategy using GRPO.
OpenSeek-Small-v1 by BAAI: The first model from the OpenSeek project, which wants to replicate R1-style models in the open.
Seed-Coder-8B-Reasoning by ByteDance-Seed: ByteDance also started dropping a lot of open models and research. Seed-Coder is a coding model, trained on 6T tokens, which are curated by using LLMs as a quality filter. The reasoning variant is trained with GRPO. Unsurprisingly for Chinese model releases, the model is released under MIT.




Datasets
academic-chains by marcodsn: A dataset consisting of CoTs and answers to problems from academic papers.
Llama-Nemotron-Post-Training-Dataset by nvidia: The underlying SFT and RL dataset for many of the Nemotron models.