

Latest open artifacts (#14): NVIDIA's rise, "Swiss & UAE DeepSeek," and a resurgence of open data
While Qwen takes some rest, others continue to fuel the open model space.
At the end of the summer, the leading open models across the ecosystem are finally coming from somewhere other than Qwen (and other leading Chinese laboratories). While Qwen has been preparing a new architecture and vision models, NVIDIA was releasing high-quality open artifacts at a record pace and we have plenty of new entrants in the space of training large models.
NVIDIA is the current open model champion in the U.S. and is getting far less praise than Meta did with their Llama series. This is a trend that we have seen multiple times, and that other organizations such as OpenAI are going through — it takes multiple releases and sustained community engagement to build the habits of developers and researchers on top of these models.
In this issue, we also have high-quality, sovereign AI releases from the UAE and Switzerland. We expect more players in this space. This represents the expected track for open models around the world — there will always be concentrated players that produce the highest quantity of artifacts, but the cost of training a singular, high-quality AI model is very tractable for many organizations or nations.
On top of all these developments is a (small) resurgence in the release of data with models. Multiple large-scale data releases from HuggingFace and NVIDIA are going to be heavily used by researchers. Additionally, there were a few “fully open” models released, such as a multilingual, 30B dense base model from TildeAI that was trained with AMD through an EU grant program. A 30B model trained to 4T tokens popping up from a new entrant shows how the compute buildout is bringing many new players online into the open ecosystem1.
Many months can go by without meaningful data releases across the whole ecosystem, so these represent a notable reprieve from the trend.
Artifacts Log
Our Picks
parakeet-tdt-0.6b-v3 by nvidia: There are a few models which completely redefine their space and push the boundaries. For open models, this is even harder as the competition from closed models is fierce. However, Parakeet fits these criteria and will probably be overlooked by a lot of people. But for me (Florian), it has redefined how I use my MacBook. Last episode, I wrote the following about Qwen3 4B Instruct:
I have started using it locally for simple tasks (like translation), as the model is really capable and the overall latency is faster than sending requests to the cloud.
The Qwen model gets complemented by this model perfectly when used in apps such as MacWhisper: Parakeet is used for the transcription, while Qwen 4B is used to clean up the raw transcripts. Both models are blazingly fast (and therefore beat cloud-based models in terms of overall latency), yet accurate.
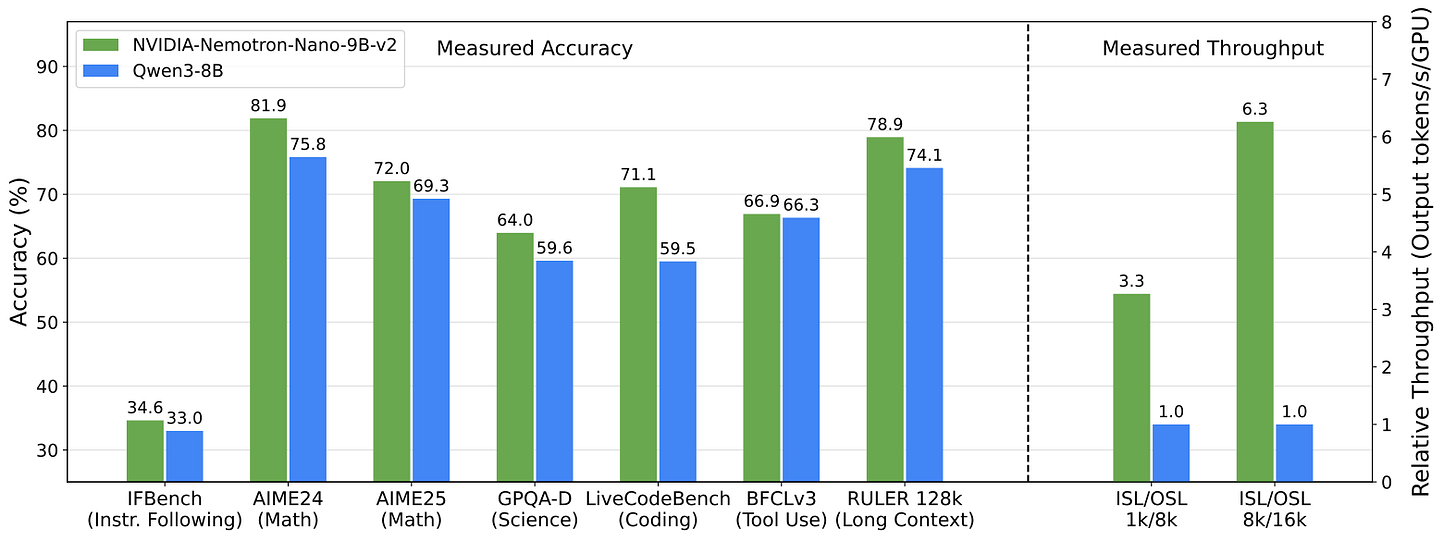
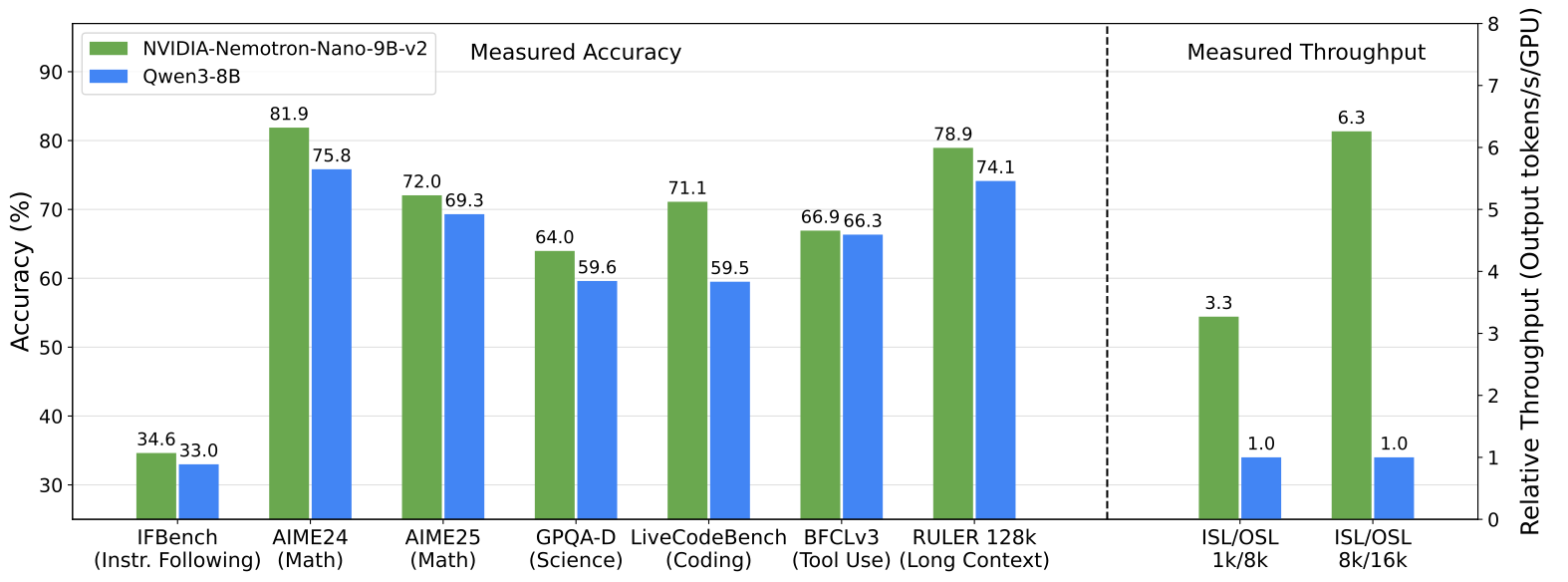
This is the big selling point of local models on device: they are tiny niche models that are as capable as more general, closed models. And Parakeet fits this description perfectly. Since it launched, I am shifting more towards using my voice to write emails, long prompts for ChatGPT or Codex or this very blog post. For me as a multilingual speaker, I felt left behind with the previous version, which was English only.NVIDIA-Nemotron-Nano-9B-v2 by nvidia: NVIDIA is one of the very few Western companies which continues to release a lot of open models and is often seen as a guest in the Artifact series. It is almost ironic that a company, which is arguably one of the most GPU-rich companies out there, continues to release models which run on limited hardware. Nemotron "Nano", which comes in 9B and 12B sizes, is a hybrid model consisting of both attention and mamba layers. It is also hybrid in the sense that it supports a reasoning and non-reasoning model. They also share (the majority of the) the pre-training data. It is hard to say "don't sleep on NVIDIA" as it is arguably one of the most important companies during the AI boom, but them continuing to release capable, small models AND open data with detailed papers is really commendable. On top of all of that, they make the model available for free on OpenRouter.
Apertus-70B-Instruct-2509 by swiss-ai: An open model by the Swiss EPFL, ETH Zürich, and Swiss National Supercomputing Centre, using 15T tokens from open datasets such as FineWeb, DCLM or The Stack. Importantly, they filtered this data by excluding domains which opted out of training. While this model itself is not pushing the open state of the art, it is an important first step towards a higher diversity, especially in the truly open model space.
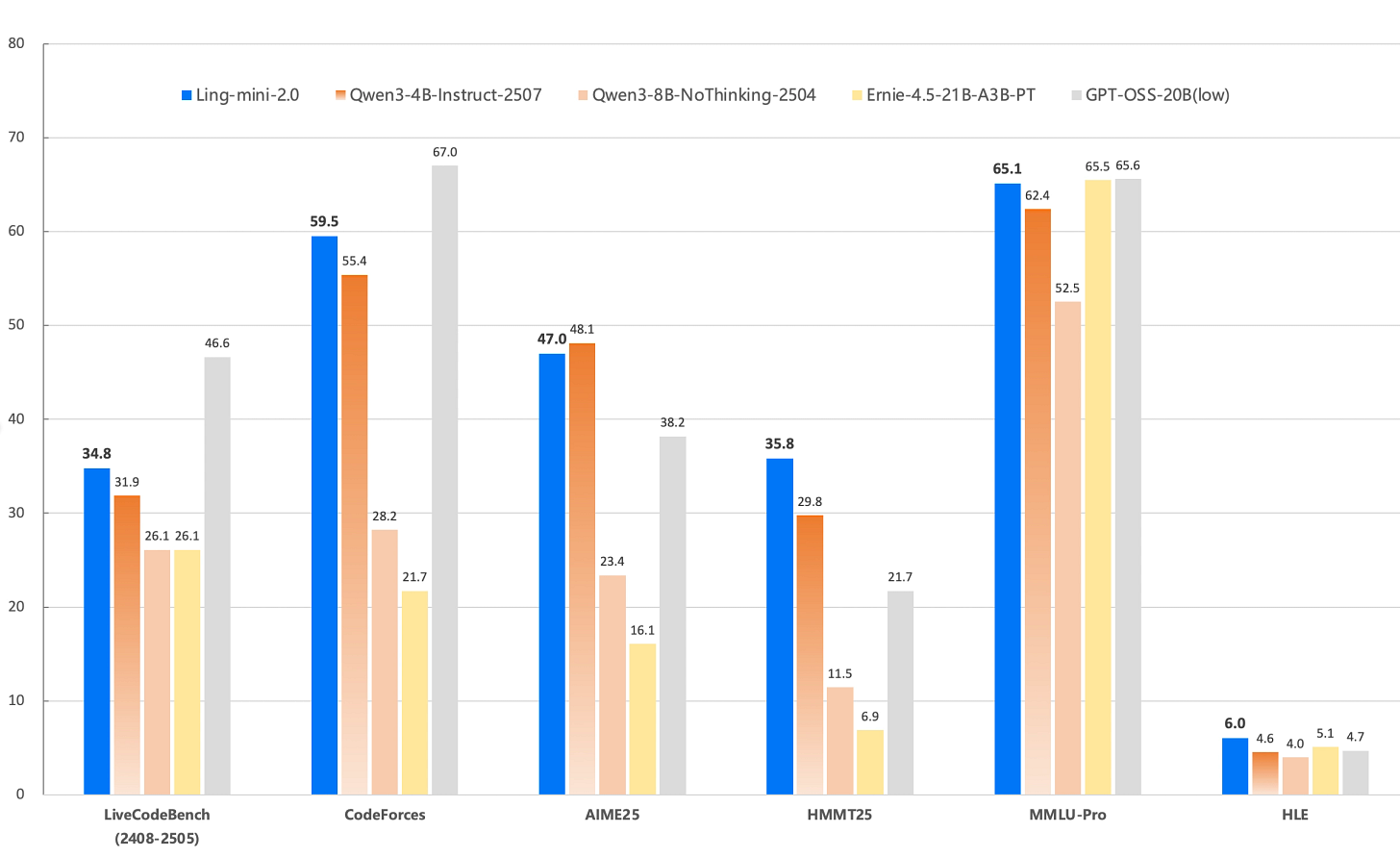
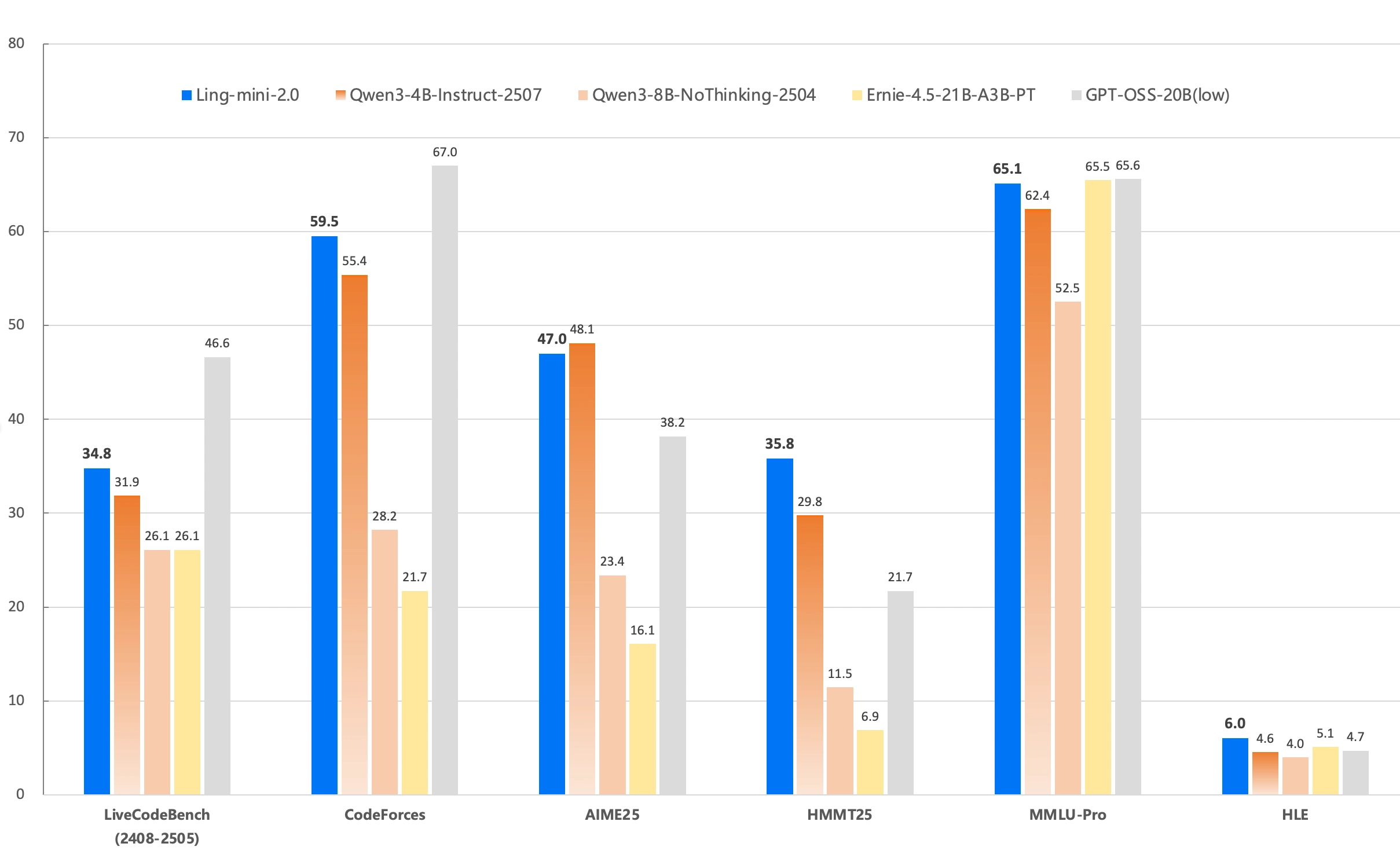
Ling-mini-2.0 by inclusionAI: The Ant Group continues to fly under the radar, but this release is pretty interesting in our opinion: They train relatively small MoE models with only 16B total parameters, but they share different checkpoints during the training for 5, 10, 15 and 20 trillion tokens. Furthermore, they release patches for Megatron and TransformerEngine and guides how to train the models further. On top of all of that, they also release a reasoning version.
FineVision by HuggingFaceM4: A massive vision dataset, spanning over 17 million images, totaling over 5TB of data, which combines, cleans and augments over 200 image datasets. FineWeb is a widely used dataset in the community, so expect this dataset to be used a lot in the future. The blog post goes into more details, including ablation studies against other datasets.
The rest of the issue is packed with updates from Kimi, DeepSeek, ByteDance Seed, AI generated otters, and even the Chinese analog of DoorDash (Meituan). The cadence of Artifacts Log is increasing to be faster than monthly due to the cadence of quality releases.