

Latest open artifacts (#19): Qwen 3.5, GLM 5, MiniMax 2.5 — Chinese labs' latest push of the frontier
Welcome to the year of the horse!
It’s been a busy month at the top end of open-weights AI — with new flagship models from all of Qwen, MiniMax, Z.ai, Ant Ling, and StepFun. Still, all eyes are on DeepSeek V4’s pending release, which rumors continue to accelerate towards. Outside of the large, frontier models, this issue is a bit lighter on the long-tail of niche modalities and model sizes.
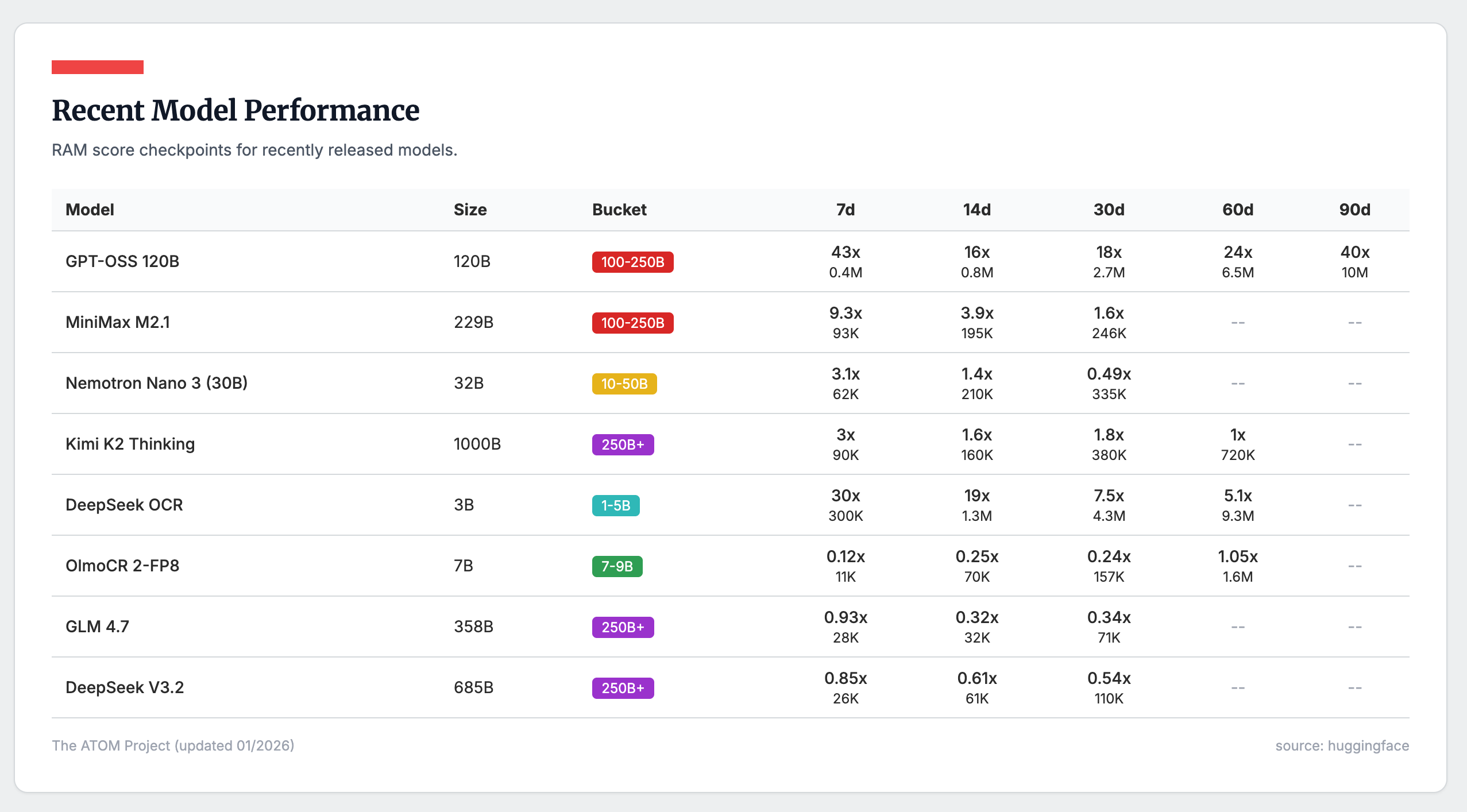
With all these new releases, we’re tracking them with our new Relative Adoption Metrics (RAM), a measurement tool that normalizes model downloads relative to peer models in their size class. This has already been an extremely useful tool for us, highlighting underrated models like GPT-OSS, which is literally off the charts in how downloaded it is — the most popular American open-weights model since Llama 3.1. A RAM score >1 means the model is on track to be a top 10 all-time downloaded model in its size class. We’re particularly interested to see how the early adoption of the smaller Qwen 3.5 dense models will go relative to Qwen 3 — balancing Qwen’s ever growing brand with a trickier, hybrid model architecture that can push the limits of some open-source tools.
A summary of the RAM scores for some of the popular models released late in 2025 is below, highlighting Kimi K2 Thinking and some OCR models as clear winners. DeepSeek V3.2, and their other recent large models, have wildly underperformed DeepSeek’s earlier releases in 2025.
Artifacts Log
Our Picks
Qwen3.5-397B-A17B by Qwen: The long-awaited update to Qwen is finally here. It comes in various sizes from 0.8B to 27B (dense) and 35B-A3B to 397B-A17B (MoE), some of them even with base models. All of them are multi-modal, use reasoning by default and are based on the Qwen-Next architecture with GDN layers.
We tested these models over the last few days, and they are a clear upgrade over the previous version: There are a lot of substantial improvements across the board, making them perfect workhorses for a wide range of tasks.
Their style and instruction-following have improved, and the models are even better at multilingual tasks, covering more languages.
However, at least the small models (still) tend to overthink. You can turn off reasoning by disabling it in the chat template.
Step-3.5-Flash by stepfun-ai: StepFun really stepped up its game (no pun intended), releasing a 196B-A11B MoE with strong metrics across the board. It is especially strong in math benchmarks, beating out models that are several times larger than it.
GLM-5 by zai-org: A 744B-A40B release from the Zhipu team, which has resulted in such a big increase in demand that they raised prices for their coding plan. It also comes with an accompanying tech report.
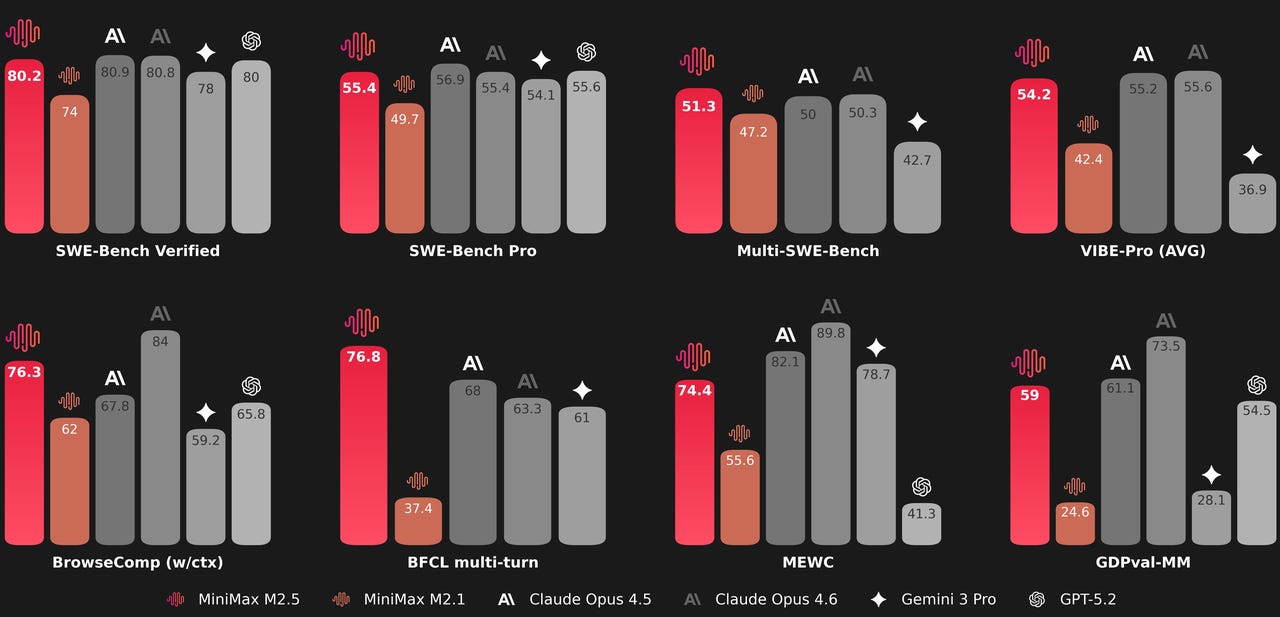
MiniMax-M2.5 by MiniMaxAI: Despite the relatively small size, Minimax-M2.5 can rival models such as GLM-5 and Kimi K2.5 and has quickly become one of the favorites of the community.
OpenThinker-Agent-v1 by open-thoughts: OpenThinkers, known for their open reasoning releases (such as OpenThoughts 3) are now tackling agentic reasoning. Their initial release includes SFT and RL data, as well as a “lite” version of terminal-based tasks to evaluate smaller models.

The subtle differences in architecture of these models are covered in detail in the similar, more technically focused, round-up from Sebastian Raschka, PhD — it’s a good complement if you’re looking to go deeper:

Models
General Purpose
Tri-21B-Think by trillionlabs: The Korean Trillion Labs is a repeated guest at the Artifacts series. This time, they are releasing a 21B reasoning model with support for English, Korean and Japanese.
MiniCPM-SALA by openbmb: An English and Chinese 8B model with sparse attention, supporting a 1M context window.