

Olmo 3: America’s truly open reasoning models
We present Olmo 3, our next family of fully open, leading language models.
This family of 7B and 32B models represents:
The best 32B base model.
The best 7B Western-origin thinking & instruct models.
The first 32B (or larger) fully open reasoning model.
This is a big milestone for Ai2 and the Olmo project. These aren’t huge models (more on that later), but it’s crucial for the viability of fully open-source models that they are competitive on performance – not just replications of models that came out 6 to 12 months ago. As always, all of our models come with full training data, code, intermediate checkpoints, training logs, and a detailed technical report. All are available today, with some more additions coming before the end of the year.
As with OLMo 2 32B at its release, OLMo 3 32B is the best open-source language model ever released. It’s an awesome privilege to get to provide these models to the broader community researching and understanding what is happening in AI today.
Paper: https://allenai.org/papers/olmo3
Artifacts: https://huggingface.co/collections/allenai/olmo-3
Demo: https://playground.allenai.org/
Blog: https://allenai.org/blog/olmo3
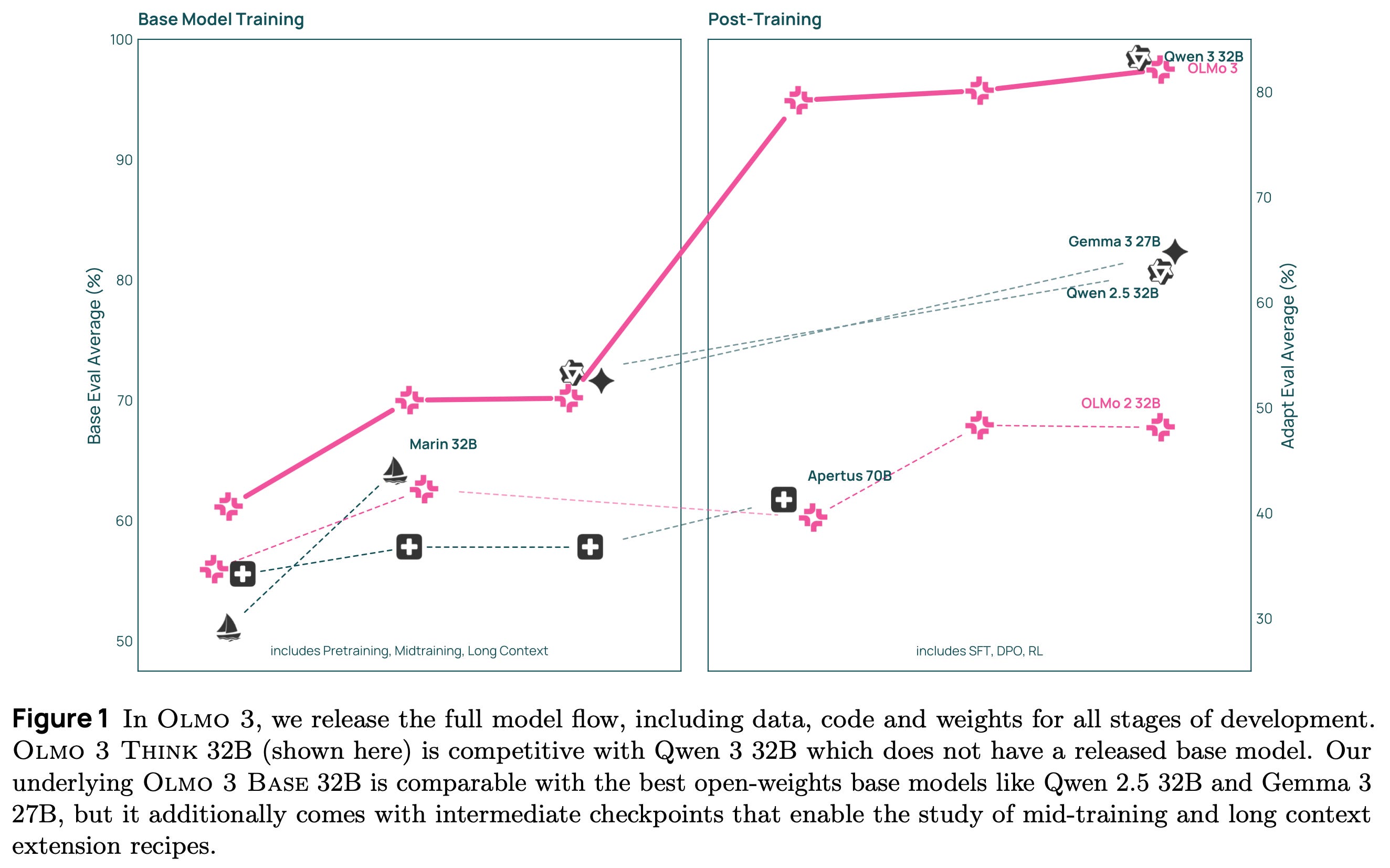
Base models – a strong foundation
Pretraining’s demise is now regularly overstated. 2025 has marked a year where the entire industry rebuilt their training stack to focus on reasoning and agentic tasks, but some established base model sizes haven’t seen a new leading model since Qwen 2.5 in 2024. The Olmo 3 32B base model could be our most impactful artifact here, as Qwen3 did not release their 32B base model (likely for competitive reasons). We show that our 7B recipe competes with Qwen 3, and the 32B size enables a starting point for strong reasoning models or specialized agents. Our base model’s performance is in the same ballpark as Qwen 2.5, surpassing the likes of Stanford’s Marin and Gemma 3, but with pretraining data and code available, it should be more accessible to the community to learn how to finetune it (and be confident in our results).
We’re excited to see the community take Olmo 3 32B Base in many directions. 32B is a loved size for easy deployment on single 80GB+ memory GPUs and even on many laptops, like the MacBook I’m using to write this on.
A model flow – the lifecycle of creating a model
With these strong base models, we’ve created a variety of post-training checkpoints to showcase the many ways post-training can be done to suit different needs. We’re calling this a “Model Flow.” For post-training, we’re releasing Instruct versions – short, snappy, intelligent, and useful especially for synthetic data en masse (e.g. recent work by Datology on OLMo 2 Instruct), Think versions – thoughtful reasoners with the performance you expect from a leading thinking model on math, code, etc. and RL Zero versions – controlled experiments for researchers understanding how to build post-training recipes that start with large-scale RL on the base model.
The first two post-training recipes are distilled from a variety of leading, open and closed, language models. At the 32B and smaller scale, direct distillation with further preference finetuning and reinforcement learning with verifiable rewards (RLVR) is becoming an accessible and highly capable pipeline. Our post-training recipe follows our recent models: 1) create an excellent SFT set, 2) use direct preference optimization (DPO) as a highly iterable, cheap, and stable preference learning method despite its critics, and 3) finish up with scaled up RLVR. All of these stages confer meaningful improvements on the models’ final performance.
Instruct models – low latency workhorses
Instruct models today are often somewhat forgotten, but the likes of Llama 3.1 Instruct and smaller, concise models are some of the most adopted open models of all time. The instruct models we’re building are a major polishing and evolution of the Tülu 3 pipeline – you’ll see many similar datasets and methods, but with pretty much every datapoint or training code being refreshed. Olmo 3 Instruct should be a clear upgrade on Llama 3.1 8B, representing the best 7B scale model from a Western or American company. As scientists we don’t like to condition the quality of our work based on its geographic origins, but this is a very real consideration to many enterprises looking to open models as a solution for trusted AI deployments with sensitive data.
Building a thinking model
What people have most likely been waiting for are our thinking or reasoning models, both because every company needs to have a reasoning model in 2025, but also to clearly open the black box for the most recent evolution of language models. Olmo 3 Think, particularly the 32B, are flagship models of this release, where we considered what would be best for a reasoning model at every stage of training.
Extensive effort (ask me IRL about more war stories) went into every stage of the post-training of the Think models. We’re impressed by the magnitude of gains that can be achieved in each stage – neither SFT nor RL is all you need at these intermediate model scales.
First we built an extensive reasoning dataset for supervised finetuning (SFT), called Dolci-Think-SFT, building on very impactful open projects like OpenThoughts3, Nvidia’s Nemotron Post-training, Prime Intellect’s SYNETHIC-2, and many more open prompt sources we pulled forward from Tülu 3 / OLMo 2. Datasets like this are often some of our most impactful contributions (see the Tülu 3 dataset as an example in Thinking Machine’s Tinker :D – please add Dolci-Think-SFT too, and Olmo 3 while you’re at it, the architecture is very similar to Qwen which you have).
For DPO with reasoning, we converged on a very similar method as HuggingFace’s SmolLM 3 with Qwen3 32B as the chosen model and Qwen3 0.6B as the rejected. Our intuition is that the delta between the chosen and rejected samples is what the model learns from, rather than the overall quality of the chosen answer alone. These two models provide a very consistent delta, which provides way stronger gains than expected. Same goes for the Instruct model. It is likely that DPO is helping the model converge on more stable reasoning strategies and softening the post-SFT model, as seen by large gains even on frontier evaluations such as AIME.
Our DPO approach was an expansion of Geng, Scott, et al. “The delta learning hypothesis: Preference tuning on weak data can yield strong gains.” arXiv preprint arXiv:2507.06187 (2025). Many early open thinking models that were also distilled from larger, open-weight thinking models likely left a meaningful amount of performance on the table by not including this training stage.
Finally, we turn to the RL stage. Most of the effort here went into building effective infrastructure to be able to run stable experiments with the long-generations of larger language models. This was an incredible team effort to be a small part of, and reflects work ongoing at many labs right now. Most of the details are in the paper, but our details are a mixture of ideas that have been shown already like ServiceNow’s PipelineRL or algorithmic innovations like DAPO and Dr. GRPO. We have some new tricks too!
Some of the exciting contributions of our RL experiments are 1) what we call “active refilling” which is a way of keeping the generations from the learner nodes constantly flowing until there’s a full batch of completions with nonzero gradients (from equal advantages) – a major advantage of our asynchronous RL approach; and 2) cleaning, documenting, decontaminating, mixing, and proving out the large swaths of work done by the community over the last months in open RLVR research.
The result is an excellent model that we’re very proud of. It has very strong reasoning benchmarks (AIME, GPQA, etc.) while also being stable, quirky, and fun in chat with excellent instruction following. The 32B range is largely devoid of non-Qwen competition. The scores for both of our Thinkers get within 1-2 points overall with their respective Qwen3 8/32B models – we’re proud of this!
A very strong 7B scale, Western thinking model is Nvidia’s NVIDIA-Nemotron-Nano-9B-v2 hybrid model. It came out months ago and is worth a shot if you haven’t tried it. I personally suspect it may be due to the hybrid architecture making subtle implementation bugs in popular libraries, but who knows.
All in, the Olmo 3 Think recipe gives us a lot of excitement for new things to try in 2026.
RL Zero
DeepSeek R1 showed us a way to new post-training recipes for frontier models, starting with RL on the base model rather than a big SFT stage (yes, I know about cold-start SFT and so on, but that’s an implementation detail). We used RL on base models as a core feedback cycle when developing the model, such as during intermediate midtraining data mixing. This is viewed now as a fundamental, largely innate, capability of the base-model.
To facilitate further research on RL Zero, we released 4 datasets and series of checkpoints, showing per-domain RL Zero performance on our 7B model for data mixes that focus on math, code, instruction following, and all of them together.
In particular, we’re excited about the future of RL Zero research on Olmo 3 precisely because everything is open. Researchers can study the interaction between the reasoning traces we include at midtraining and the downstream model behavior (qualitative and quantitative).
This helps answer questions that have plagued RLVR results on Qwen models, hinting at forms of data contamination particularly on math and reasoning benchmarks (see Shao, Rulin, et al. “Spurious rewards: Rethinking training signals in rlvr.” arXiv preprint arXiv:2506.10947 (2025). or Wu, Mingqi, et al. “Reasoning or memorization? unreliable results of reinforcement learning due to data contamination.” arXiv preprint arXiv:2507.10532 (2025).)
What’s next
This is the biggest project we’ve ever taken on at Ai2, with 60+ authors and numerous other support staff.
In building and observing “thinking” and “instruct” models coming today, it is clear to us that there’s a very wide variety of models that fall into both of these buckets. The way we view it is that thinking and instruct characteristics are on a spectrum, as measured by the number of tokens used per evaluation task. In the future we’re excited to view this thinking budget as a trade-off, and build models that serve different use-cases based on latency/throughput needs.
As for a list of next models or things we’ll build, we can give you a list of things you’d expect from a (becoming) frontier lab: MoEs, better character training, Pareto efficient instruct vs think, scale, specialized models we actually use at Ai2 internally, and all the normal things.
This is one small step towards what I see as a success for my ATOM Project.
We thank you for all your support of our work at Ai2. We have a lot of work to do. We’re going to be hunting for top talent at NeurIPS to help us scale up our Olmo team in 2026.
Damm finally a fully open source model. I loved when labs released their models and initially called them open source rather than open weights.
Thank you for sharing the training pipeline as well
This is great news I am psyched for many reasons. Look forward to exploring, tinkering, building with the Olmo 3 models. 🦅