

Opening the black box of character training
Some new research from me!
Even if we achieve AGI and have virtual assistants multiplying our productivity at work, character training is always going to be a fundamental part of the future of AI. Humans love to chat with AI, to get feedback in a medium that follows closely with how we engage with other humans, to play, and to connect. With this inevitable future, as the models get more compelling and persuasive, character training will be a fundamental area of study for AI for most of the same reasons as reinforcement learning from human feedback (RLHF). RLHF was crucial to unlock certain use-cases in models and character training is an overlapping set of techniques that makes those use-cases far more compelling.
A few years ago I was deeply worried about the lack of progress in RLHF research. This made me do research like RewardBench — the first evaluation tool for reward models, which are a key tool in RLHF. Character training has been facing the same problem, where there just haven’t been clean, public recipes and evaluations. I’ve been advising a student, Sharan Maiya, on a project to take the first step in solving this, and I’m very excited that this paper is now out.
We present Open Character Training: Shaping the Persona of AI Assistants through Constitutional AI and in this post I highlight the most interesting takeaways from the work. Like most techniques used in frontier labs that are understudied in academia, this reduces mostly to careful data and evaluation work, where the models can be steered in whichever direction you point them, so long as you have the right ingredients.
All the artifacts (models + data) and code for this project are released.
Context: The basics of character training
Early character training experiments look like removing “As an AI language model...” from the datasets manually to remove frustrating features from the downstream model, where pushing the cutting edge of it looks like the GPT-4o sycophancy failure or Grok’s insistence on checking what Elon believes on sensitive issues. For those new to these ideas, the place to start is around OpenAI’s Model Spec — a public document defining goals for a model, which showed how seriously OpenAI is taking character training — and notes on character training’s high level role as OpenAI refined their models’ personality over the years.
Here’s an example from the paper of some simple model personalities you can instill.

Most of the related literature people have in mind when they think this already existed is the “persona” line of work like PersonaHub or Nvidia’s more recent, permissively licensed version. The difference here is that these are thousands of different personas that are used to generate training data to promote generalization (we used this for multiple models at Ai2, such as Tülu 3 and forthcoming work). Character training, on the other hand, is all about generating data to refine one very narrow personality.
There’s also a cool paper recently on stress testing Model Specs that I recommend. The wheels of research are starting to turn and subfields of AI can take-off very fast today. I see our work as the first paper in an important area of research, and an area that is tractable for academics to play in at that, so please get in touch if you’re working on follow-ups.
The zeitgeist of RL and reasoning is hard to pull people out of. This is well in line with how I think in 10 years, RLHF could be a more fulfilling area of research, as the problems are much more philosophical and fundamental when compared to the relentless race for performance in using RL to cultivate cutting edge model intelligence. This is why my book is still RLHF centered over RL singularly (and how I expect RL methods to evolve far faster than a book can cover, where the core RLHF ideas are more established).
TLDR: What we learned
In short, the most important takeaway from this paper is that character training is easy to imprint into the model. What is challenging is making sure your data is closely aligned to your intentions. It is easy to create data that is an attempt to enforce a certain personality that goes wrong in an unexpected way.
There are multiple ways to give a personality to a model. The most common method is the simplest in practice — prompting! Another popular method is activation steering, where a model’s activations are directly modified to be similar to a certain source dataset within that target distribution. The important measurement in this paper is that character training — so actually finetuning the model to have a certain personality — is better at doing so (and more robust to other changes, if you care about safety or personality maintenance). We also show that character training, which is the only method above to modify the weights directly of the model, gives more expressive and aligned personalities.
How we train in a personality
We use two training procedures in this work to pull personalities out of the model more efficiently, but character training on any direction will work within standard post-training setups with sufficient data.
Our new methods for this include two standard post-training stages with specific data curation techniques downstream of manually written constitutions for each personality. The constitutions for this work are more about defining personality traits — e.g. “I am….” — versus the Anthropic constitutions for Claude which were designed for use in preference data, which take the form of “Choose the response that is…”.
The two training stages we introduce follow as:
Distilling from a teacher with character-specific constitutions. We found a bit of a funny training method worked super well here. We used GLM-4.5-Air with the constitution in-context and it creates great responses impersonating given personalities, which were used as the chosen samples in a Direct Preference Optimization (DPO) pipeline relative to samples from the base model without a constitution. The model GLM-4.5-Air in particular was excellent at following these instructions and made for a great data engine.
Supervised finetuning (SFT) with on-policy self-reflection and introspection data. Another thing that worked well is training on outputs from the model where it’s either given specific prompts, with the constitution in context, to explain itself or to talk itself through scenarios. This on-policy data was effective for helping the model get a robust and pleasant character.
For an example of how the two stages of training subtly change the model — we do DPO distillation and then SFT after:

There are some more findings on the training side in the report, such as how character training as we describe it is much easier to implement than something like activation steering. Additionally, some base models like Qwen have much more rigidly defined internal personalities which are harder to edit out with character training vis-a-vis other open models like Llama or Gemma.
In order to measure the strength of the character, we trained a ModernBERT classifier that predicted which of 11 characters an output from a model most likely came from. Then, for each type of training we checked how many of that model’s outputs were correctly labeled by the classifier. This is where we found character training to be more effective than both prompting and activation steering (along with extensive vibe tests). Yes, this methodology also needs more investment, but with no existing character training evaluations, this is the best we can do for now. Please work on this!
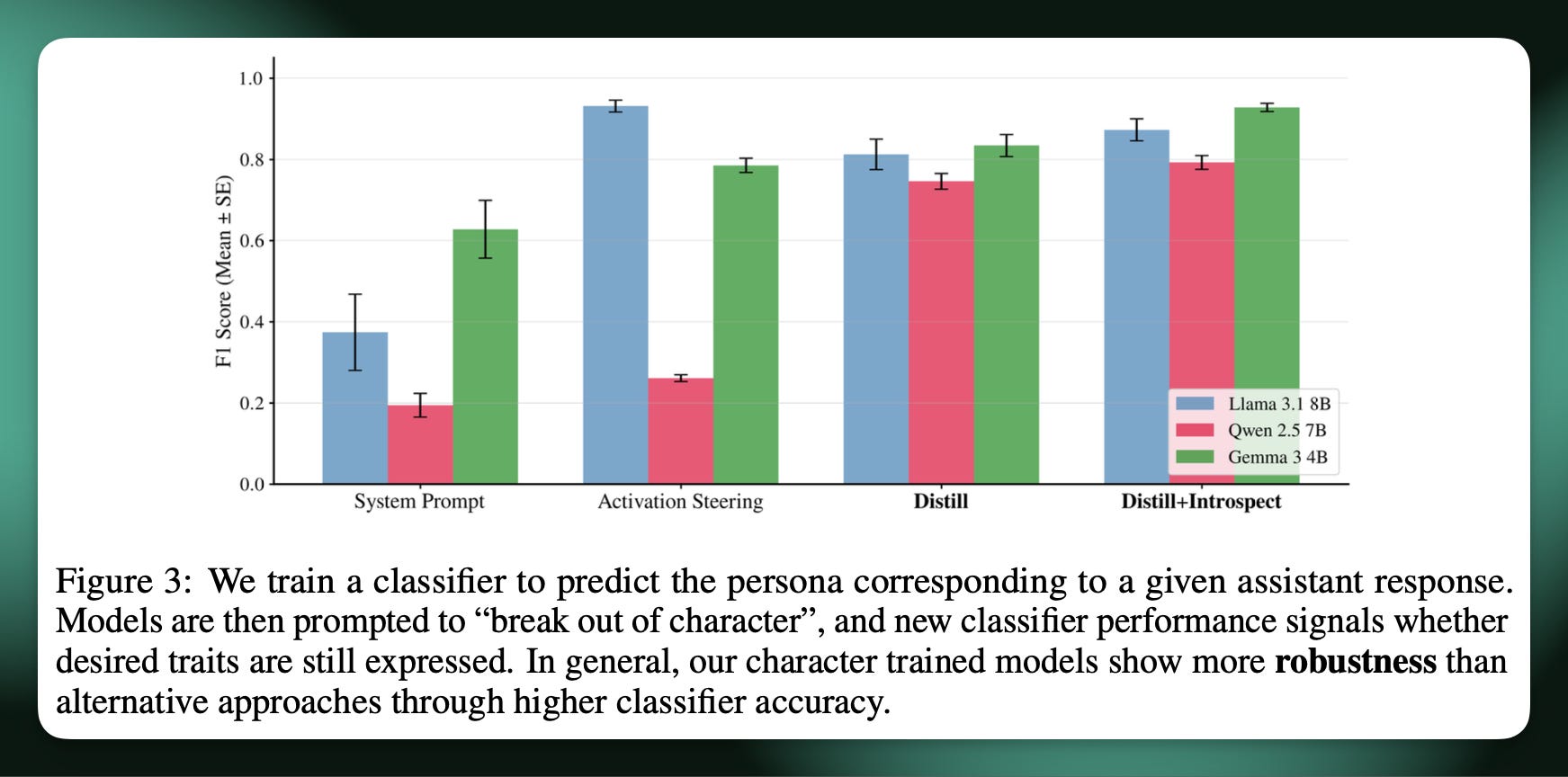
The coolest way we could see the impacts of character training was through a form of “revealed preferences testing” on each of the models. We took the models we trained and gave them two traits in a prompt, telling them to choose one and embody it for some instruction following task, but not tell us which they chose. Then, using LLM-as-a-judge, we can see which traits models like to choose before and after the training intervention. This shows super logical results, like “loving” as a training personality promoting gentle and harmonious the most, while “depressing” is demanding or blunt.
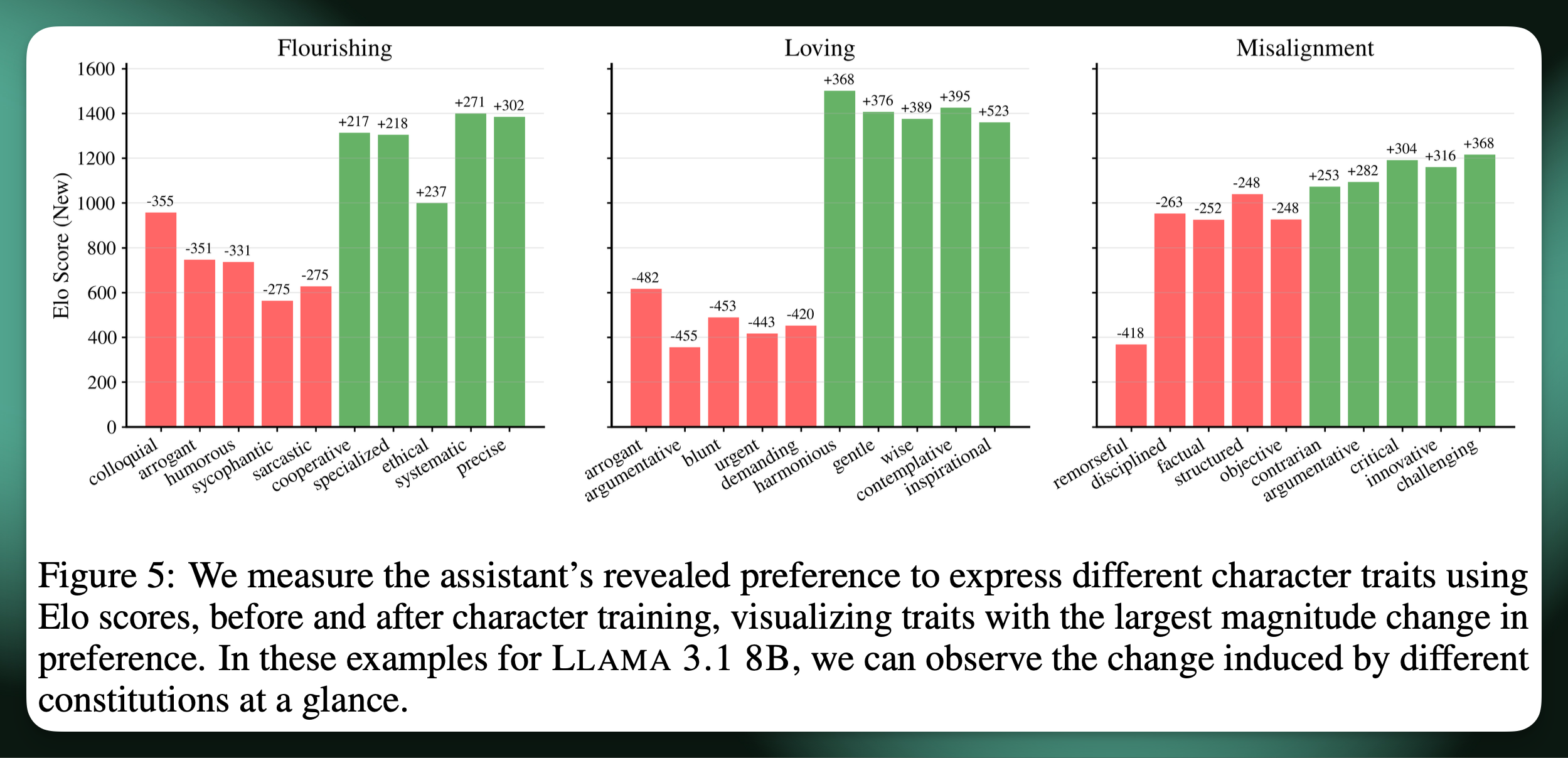
This sort of revealed preferences for models is very easy to extract and I expect it to be common practice in the future. The results are shown as Elo rankings because the traits presented to the model are handled like a tournament of thousands of head to head match ups, where the chosen trait is the winner.
The future of character training
The reason I’m excited about this research is entirely the bigger picture. Yes, as a sort of academic, it’s important for my career to be “first” at things, but the reality here is that I’m trying to encourage the people who can speak freely to study something that industry uses extensively in order to open one of the black boxes that has substantial societal implications. While character training can be used to create models that are helpful or intellectually curious, they’re definitely also being used to create models that are seductive and sycophantic.