

Tülu 3: The next era in open post-training
We give you open-source, frontier-model post-training.
Post-training, the craft of eliciting powerful behaviors from a raw pretrained language model, has gone through many seasons and moods since the release of ChatGPT. In the era of Alpaca, Vicuna, Koala, and Dolly, a limited number of human datapoints with extended synthetic data in the style of Self-Instruct were used to normally fine-tune the original LLaMA to get similar behavior to ChatGPT. The benchmark was fully vibes (and human evaluation) as we were all so captivated by the fact that these small models can have such impressive behaviors across domains. It was justified excitement.
Open post-training was moving faster, releasing more models, and making more noise than its closed counterparts. Companies were scrambling, e.g. DeepMind merging with Google or being started, and taking time to follow it up. There are phases of open recipes surging and then lagging behind.
The era following Alpaca et al., the first lag in open recipes, was one defined by skepticism and doubt on reinforcement learning from human feedback (RLHF), the technique OpenAI highlighted as crucial to the success of the first ChatGPT. Many companies doubted that they needed to do RLHF. A common phrase – “instruction tuning is enough for alignment” – was so popular then that it still holds heavy weight today despite heavy obvious pressures against it.
This doubt of RLHF lasted, especially in the open where groups cannot afford data budgets on the order of $100k to $ 1 million. The companies that embraced it early ended up winning out. Anthropic published extensive research on RLHF through 2022 and is now seen as having the best model. The delta between open groups, struggling to reproduce, or even knowing basic closed techniques, is a common theme.
The first shift in open alignment methods and post-training was the story of Direct Preference Optimization (DPO). The DPO paper, posted in May of 2023, didn’t have any clearly impactful models trained with it going through the fall of 2023. This changed with the releases of a few breakthrough DPO models – all contingent on finding a better, lower, learning rate. Zephyr-Beta, Tulu 2, and many other models showed that the DPO era of post-training had begun. Chris Manning literally thanked me for “saving DPO.” This is how fine the margins are on evolutions of best practices with leading labs being locked down. Open post-training was cruising again.
Preference-tuning was something you needed to do to meet the table stakes of releasing a good model since late 2023. The DPO era continues today, in the form of never-ending variants on the algorithm, but we’re very far into another slump in open recipes. Open post-training recipes had saturated the extent of knowledge and resources available. A year after Zephyr and Tulu 2, the same breakout dataset, UltraFeedback is arguably still state-of-the-art for preference tuning in open recipes.
At the same time, the Llama 3.1 and Nemotron reports gave us substantive hints that large-scale post-training is much more complex and impactful. The closed labs are doing full post-training – a large multi-stage process of instruction tuning, RLHF, prompt design, etc. – where academic papers are just scratching the surface.
Today, we’re launching Tulu 3 – the first fully open recipe for frontier model post-training. It was quite simple, when Meta shared the Llama 3.1 report, we used Llama 3.1 post-trained models as a target for optimization, trained a better model, and released the entire thing to the world. We did it. We surpassed the performance of Meta’s instruction versions for Llama 3.1 8B and 70B, with more models coming soon (405B 👀). While the original inspiration and goal came from Meta’s model, we designed a novel recipe better suited for open-source finetuning with new and cheaper approaches.
Tulu 3 is a very modern post-training stack and entirely open-sourced:
Extensive guidance on evaluation, decontamination, and recipe design,
New synthetic instruction datasets,
Scaling preference data with on-policy generations,
Reinforcement learning with verifiable rewards, a new method using RL without a reward model to boost specific skills,
Optimizing training across multiple stages with smooth infrastructure and understanding of different needs,
And all the details and code you need to do this yourself. Anyone can take Llama 3.1 models and fine-tune them to the performance of (the original versions of) GPT-4 on tasks they care about.


Here are the core artifacts you’ll be looking for:
8B models (all here):
70B models:
All fine-tuning datasets. Including…
Training Repository: https://github.com/allenai/open-instruct
Eval Repository: https://github.com/allenai/olmes
Paper: https://allenai.org/papers/tulu-3-report.pdf (arXiv soon)
Technical blog post: https://allenai.org/blog/tulu-3-technical
This step forward is particularly urgent – language model training is changing. The simple pre-training and post-training separation is blurred and being rebuilt with entirely new styles of models like OpenAI’s o1. Models like DeepSeek R1 lite are imitating o1, and this style of using more clever ideas to train language models will continue. This is all downstream of understanding how powerful post-training, and other loss functions like RL, can be on final model performance.
Post-training is of increased importance to the leading labs — Meta’s post-training team has about 200 people — and soon the broader AI ecosystem, such as policymakers, will wake up to that too.
Technical pieces I’m proudest of
There will be multiple blog posts and talks downstream of Tulu 3. We’re updating the default approach to post-training and our expectations for performance. There are a few novel things we did here that are indicative of this:
Scaling preference data: For too long the open community has been relying mostly on one dataset, UltraFeedback, with only 60k samples to do DPO. We kept scaling our pipelines and got to effective datasets of over 300k prompts (just 30% of our SFT size). In the future, I expect preference datasets to have about the same number of prompts as SFT.

On-policy preference data: Something we know closed labs are doing is using extensive completions from their own models to do post-training. Part of this is because they need to take less risk from a legal perspective (i.e. they can’t distill from GPT-4 because of terms of service), but also it has been proven effective again and again. We saw the same gains.
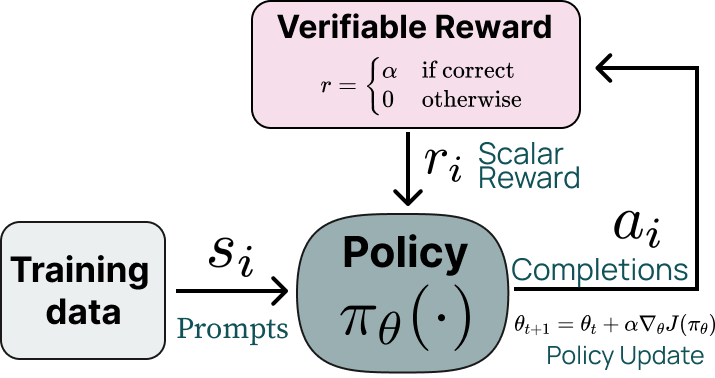
Reinforcement learning with verifiable rewards (RLVR): The most exciting part — we added a whole new style of RL training to the general post-training paradigm. This is very related to methods like VinePPO or QuietSTAR, but it is implemented on top of DPO models and improves average performance, not just one evaluation score at the cost of others.
The idea is simple. We replace the reward model in traditional RLHF with a scoring function that outputs a positive reward if the answer to the prompt is correct. For now, this is limited to math and precise instructions in our tools, but we are going to extend it to code and experiment with learned verifiers as well!

What’s next
We’re going to apply this to more open-weight models and improve the understanding of how you post-train a very specific base model (plus synergizing with mid- and pre-training with OLMo).
Expect a bunch more content fleshing out my views on how this relates to o1-style models and agents.
Note that a large portion of this post followed my Stanford lecture Aligning Open Language Models – I’m excited to do a new one following this work.
I'm not objective and don't know enough to fully evaluate this work. However, it is encouraging to see this and it certainly motivates me to dive in. I love the broad topcic, can those w/o $100 million to spend make progress?