

What I’ve been building: ATOM Report, post-training course, finishing my book, and ongoing research
This post is a roundup of my recent efforts that did not warrant a standalone Interconnects post, why I’m spending time on them, and what they accomplished.
1. The ATOM Report: Measuring the Open Language Model Ecosystem
https://arxiv.org/abs/2604.07190
To accompany The ATOM Project memo, arguably a manifesto, making the case for investment in open models in the U.S. – originally launched in August 2025 – we’ve released an updated technical report with our latest data, analysis, and storytelling within the open language model ecosystem. The ATOM Report is dense with the methods Florian and I use to keep track of the open ecosystem. It covers GPT-OSS’s rise, inference market share, the influence of China’s mid-tier players like Moonshot, Z.ai, & MiniMax, signs of the U.S.’s progress on open models, and much more.
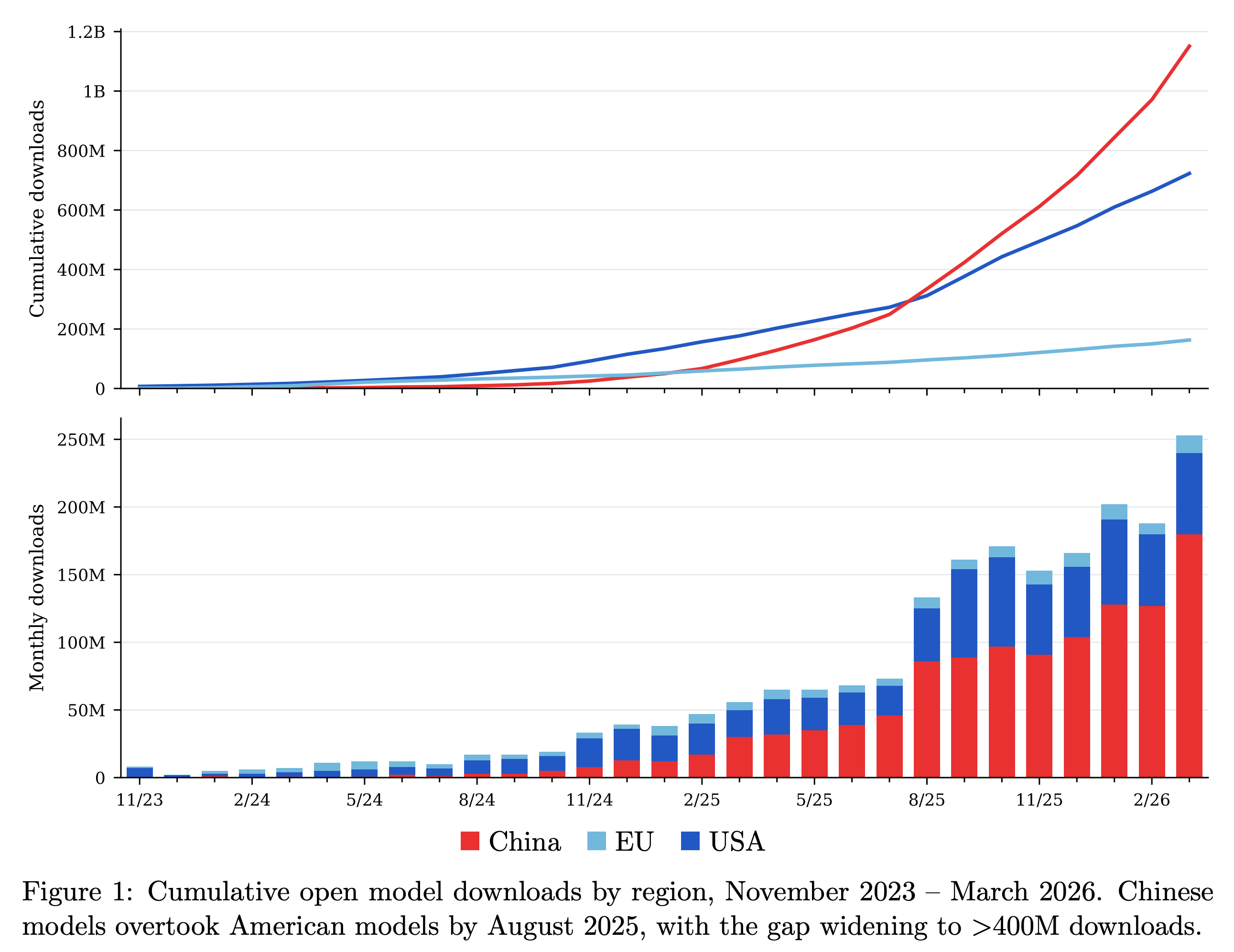
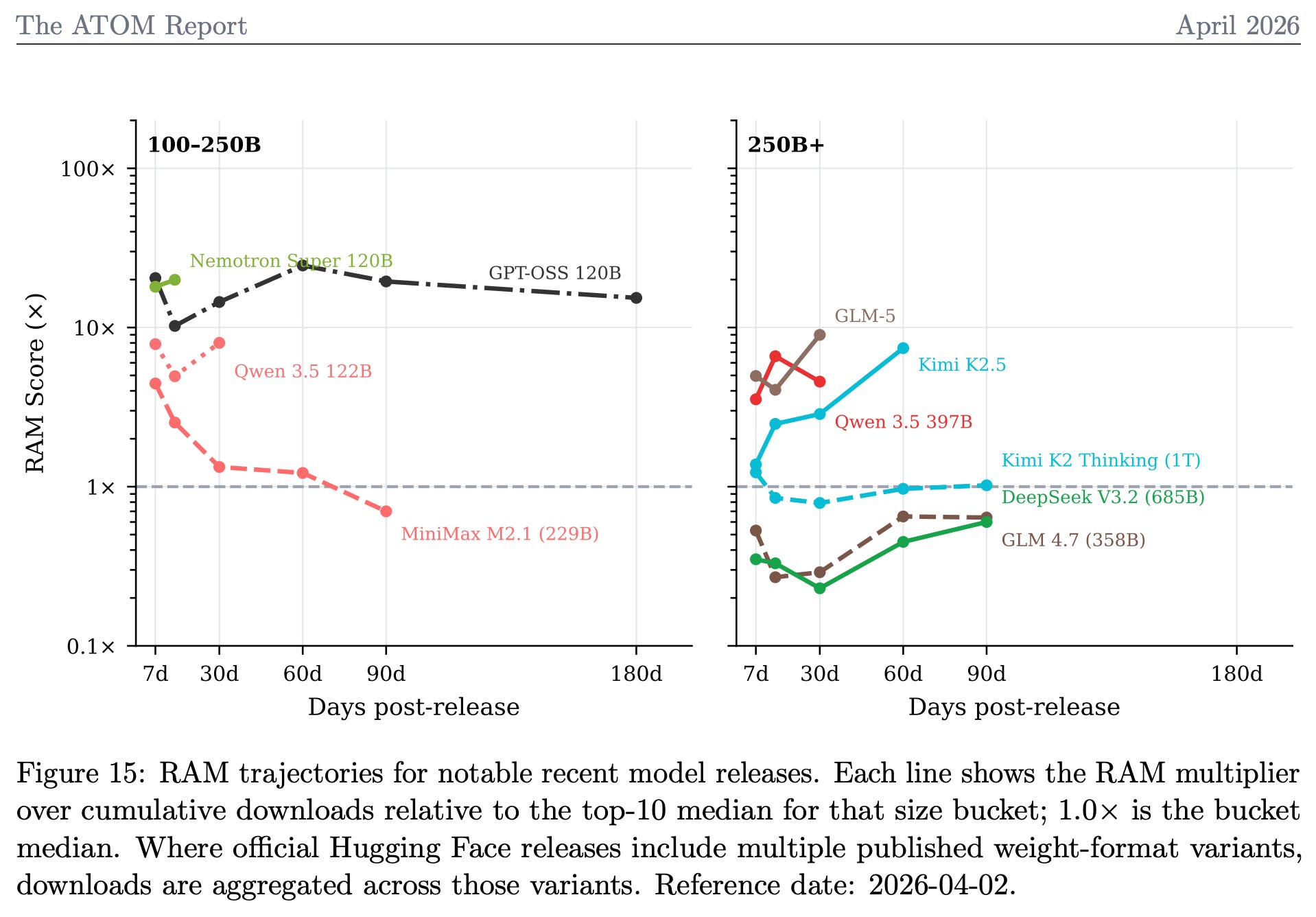
In particular, the paper details our updates to the Relative Adoption Metric (RAM), which we use to evaluate the adoption of recent models in a time-varying and size-normalized manner. Here’s a sampling of recent, primarily Chinese, models on the RAM score. The RAM score is designed so that a score >1 indicates a model is, at that point in time, on track to be a top 10 most downloaded model of its size category, ever. It reduces a messy landscape to one, easily interpretable number!
We used the data to also analyze the recent Gemma 4 release, which is showing incredible early adoption numbers. We’ll stay tuned on it!

Subscribe to the (infrequent) ATOM Project Substack for more updates like this!
2. RLHF Book is done & ready for pre-order!
The goal of this book was to write the book I wished I had when I was getting started in post-training language models. This project has been on my mind for a long time. I bought the domain rlhfbook.com and started to take it more seriously on May 20th, 2024. Here we are!
Last week, it was sent to production with the Manning team. This means content edits are done, and it’ll be sent to print in ~2 months. In the meantime, I’m spending my time developing the accompanying code and course (more on that below).
You can preorder on Amazon or Manning (currently cheaper).

3. A post-training course I’m making
The goal of my book is for it to be the central resource for people looking to transition from beginner to expert in post-training. It’s not necessarily an entry-level book, but as AI models become stronger, it needs to be a community-building effort as well. The first step I’ve made to expand the scope from just a book to a complete learning experience is building a lecture series. The lectures will be freely available on YouTube and incorporate community questions & answers (as standalone videos in between lectures).
You can watch the first batch of videos below, and subscribe on YouTube for future ones. I’m going to build on the book platform more this summer, as I develop the book codebases and host in-person events.
RLHF and Post-training Overview | RLHF Book Course, Lecture 1
RLHF Foundations, IFT, Reward Modeling, Rejection Sampling | RLHF Course Lecture 2
Understanding Policy Gradient Algorithms for RL on LLMs | RLHF Course Lecture 3

4. Recent technical research
Long-time followers of Interconnects know that this blog has its roots in explaining fundamental research in the field. This has immense value in two ways. First, as AI moves incredibly fast, far more people need to be able to parse research to make the right bets on the technology. Research is the only early warning of some big changes coming. Second, it helps uplift the careers of my collaborators – the people I spend my life with! On that note, check out two papers I had the privilege of being part of below.
https://arxiv.org/abs/2603.16759 - TurnWise: The Gap between Single- and Multi-turn Language Model Capabilities, Graf et al. 2026
This work explores the strengths of various models in multi-turn dialogue settings, how to create training data to improve it, and other quirks in post-training. My interests here have fully shifted to agents, where I see multi-turn interactions as a very important user interface problem — what information do I show to the user to solve the task as soon as possible without cutting corners?
https://arxiv.org/abs/2603.11327 - Meta-Reinforcement Learning with Self-Reflection for Agentic Search, Xiao et al. 2026
This paper frames solving hard problems with RLVR as a meta-learning problem, where context from previous attempts should be used to inform future rollouts. It’s a very obvious idea in some ways, where most of RL for LLMs is still very on-policy, but naive. The models learn from recent trials in parameters, but not in context. This research feeds into a ton of other recent work on ways that RL can be formulated to solve different forms of continual learning. Another great related paper is Learning to Discover at Test Time.
I’m off to China (and then hopefully DC) in the next couple of months to learn even more about how the world sees progress in AI. I’m excited to talk to a broader range of people than I tend to in my focused technical job. Thanks for reading, as always!
Watched the intro to the RLHF course, exciting material, thank you for putting it all out in the open. Super helpful, Nathan you are doing yeoman work.
have fun in china!