

Ranking the Chinese Open Model Builders
From the obvious names to those to keep an eye on.
The Chinese AI ecosystem has taken the AI world by storm this summer with an unrelenting pace of stellar open model releases. The flagship releases that got the most Western media coverage are the likes of Qwen 3, Kimi K2, or Zhipu GLM 4.5, but there is a long-tail of providers close behind in both quality and cadence of releases.
In this post we rank the top 19 Chinese labs by the quality and quantity of contributions to the open AI ecosystem — this is not a list of raw ability, but outputs — all the way from the top of DeepSeek to the emerging open research labs. For a more detailed coverage of all the specific models, we recommend studying our Artifacts Log series, which chronicles all of the major open model releases every month. We plan to revisit this ranking and make note of major new players, so make sure to subscribe.

At the frontier
These companies rival Western counterparts with the quality and frequency of their models.
DeepSeek
deepseek.com | 🤗 deepseek-ai | X @DeepSeek_AI
DeepSeek needs little introduction. Their V3 and R1 models, and their impact, are still likely the biggest AI stories of 2025 — open, Chinese models at the frontier of performance with permissive licenses and the exposed model chains of thought that enamored users around the world.
With all the attention following the breakthrough releases, a bit more has been said about DeepSeek in terms of operations, ideology, and business model relative to the other labs. They are very innovative technically and have not devoted extensive resources to their consumer chatbot or API hosting (as judged by higher than industry-standard performance degradation).
Over the last 18 months, DeepSeek was known for making “about one major release a month.” Since the updated releases of V3-0324 and R1-0528, many close observers have been surprised by their lack of contributions. This has let other players in the ecosystem close the gap, but in terms of impact and actual commercial usage, DeepSeek is still king.
An important aspect of DeepSeek’s strategy is their focus on improving their core models at the frontier of performance. To complement this, they have experiments using their current generation to make fundamental research innovations, such as theorem proving or math models, which ultimately get used for the next iteration of models. This is similar to how Western labs operate. First, you test a new idea as an experiment internally, then you fold it into the “main product” that most of your users see.
DeepSeekMath, for example, used DeepSeek-Coder-Base-v1.5 7B and introduced the now famous reinforcement learning algorithm Group Relative Policy Optimization (GRPO), which is one of the main drivers of R1. The exception to this (at least today) is Janus, their omni-modal series, which has not been used in their main line.
Qwen
qwenlm.ai | 🤗 Qwen | X @Alibaba_Qwen
Tongyi Qianwen, the primary AI lab within Alibaba’s cloud division, is by far and away most known for their open language model series. They have been releasing many models across a range of sizes (quite similar to Llama 1 through 3) for years. Recently, their models from Qwen 2.5 and Qwen 3 have had accelerating market share among AI research and startup development.
Qwen is closer to American Big Tech companies than to other Chinese AI labs in terms of releases: They are covering the entire stack, from VLMs to embedding models, coding models, image and video generation, and so on.
They also cater to all possible customers (or rather every part of the open community) by releasing capable models of all sizes. Small dense models are important for academia to run experiments and for small/medium businesses to power their applications, so it comes to no surprise that Qwen-based models are exploding in popularity.
On top of model releases for everyone, they also focused on supporting the (Western) community, releasing MLX and GGUF versions of their models for local usage or a CLI for their coding models, which includes a generous amount of free requests.
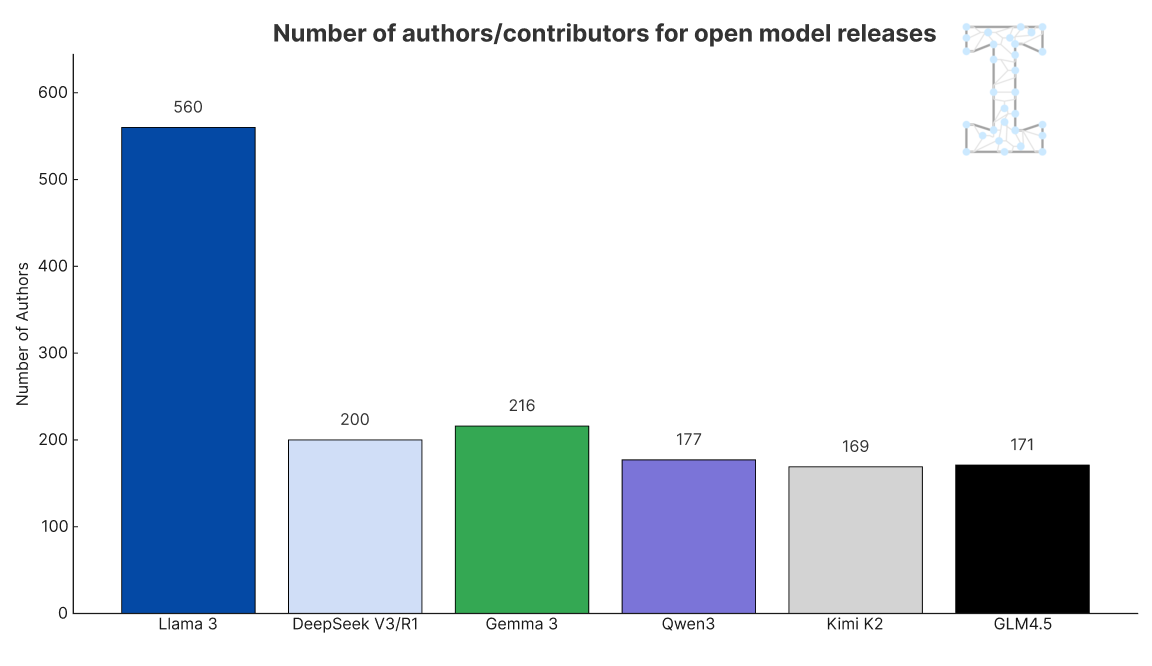
Unlike some American companies, the core team seems to have stayed relatively small in terms of headcount, in line with other Chinese AI labs: Qwen3 has 177 contributors, whereas Llama 3 has thrice the amount, while Gemini 2.5 has over 3,000 people as part of the model.
Close competitors
These companies have recently arrived at the frontier of performance and we will see if they have the capability to consistently release great models at a pace matching Qwen or DeepSeek.
Moonshot AI (Kimi)
moonshot.cn | 🤗 moonshotai | X @Kimi_Moonshot
Moonshot AI is one of the so-called “AI tigers”, a group of hot Chinese AI startups determined by Chinese media and investors. This group consists of Baichuan, Zhipu AI, Moonshot AI, MiniMax, StepFun, and 01.AI — most of which have attracted investments by tech funds and other tech grants. For example, Alibaba is seen as a big winner in the AI space by having their own models and by being a lead investor in Moonshot, sort of like how big tech companies in the U.S. are investing in fundraising rounds for newer AI labs.
While their first models, K1 and K1.5, were closed and available on their API, they started releasing open models after the R1 release with experimental models using the Muon optimizer. Similar to DeepSeek, they focus on a single model line, with small experiments eventually feeding back into the main model. K2 is their “moonshot run,” a.k.a. yolo run, and quickly became a hit similar to R1 (see our report from the release).
Further reading on Kimi can be found on ChinaTalk.
Zhipu / Z.AI
z.ai | 🤗 zai-org | X @Zai_org
Zhipu, known in the west as Z.ai, is a startup spinoff of Tsinghua University with considerable investments by Chinese companies and VCs. Currently, they are even considering an IPO, which would make them the first AI tiger to do so.
In terms of models, they are mostly known for their recent release of GLM-4.5 and GLM-4.5V, which are all very capable for their sizes (both of which are fairly large mixture of expert models). However, they are not just releasing LLMs, but also image and video generation models, setting them apart from pure-LLM companies and labs.
Noteworthy
These companies are transitioning to open releases, have open models with inferior capabilities, or slightly different foci than the text-centric labs pushing the frontiers of intelligence.
StepFun
stepfun.ai | 🤗 stepfun-ai | X @StepFun_ai
StepFun first started as a closed model provider, but pivoted to open model releases after DeepSeek R1 shook up the industry. They are mostly focusing on multi-modal model releases, with Step3 being their flagship VLM. They also have image, audio and video generation models.
Tencent (Hunyuan)
hunyuan.tencent.com | 🤗 Tencent | X @TencentHunyuan
Hunyuan is mostly known for HunyuanVideo and Hunyuan3D. While they have released three series of different LLMs, their releases come with very strict licenses, which is unusual for Chinese companies and dampens excitement when combined with performance levels that can be found elsewhere.
RedNote (Xiaohongshu)
xiaohongshu.com | 🤗 rednote-hilab
The Chinese version of Instagram, RedNote, recently joined the ranks of Chinese companies releasing open models. Especially their capable character recognition / OCR model surprised many (see our coverage). Similar to Xiaomi and Baidu, it remains to be seen what their overall open strategy will be in the near and distant future and they have not competed in the large, frontier model space.
MiniMax
minimaxi.com | 🤗 MiniMaxAI | X @MiniMax__AI
MiniMax is another of the AI tigers and also started as a closed company. After the release of R1, they changed their strategy and released the weights of Minimax-Text-01, following up with reasoning models building upon it. The unique selling point of these models are the 1M context window achieved with hybrid attention.1
These text models are not the only thing they are focusing on — they also have image and video generation models, but those remain closed and only available on their API. They are also promoting their consumer platform heavily as they eye an IPO.
OpenGVLab / InternLM
internlm.intern-ai.org.cn | 🤗 InternLM | X @opengvlab
InternLM & OpenGVLab have deep ties to the Shanghai AI Laboratory, with InternLM focusing on the language models, while OpenGVLab releases vision models. While they release a range of models such as S1 or InternLM-Math, the orgs are mostly known for the strong InternVL series. While the first versions mostly used their own InternLM pretrained models, later releases (such as InternVL3) rely on Qwen as the language backend.
Skywork
skywork.ai | 🤗 Skywork | X @Skywork_AI
The Singaporean Skywork first started out as an online karaoke company (yes, really) before they pivoted to AI and being a competitor to Manus, with their platform focusing on agents for work-related tasks, such as slide generation.
Their LLM journey started with them releasing their own pretrained dense and MoE models. However, they stopped pre-training their own models and instead started to fine-tune existing models: Their OR1 reasoning model builds on top of DeepSeek-R1-Distill-Qwen-32B, R1V3 uses InternVL3 (which itself uses Qwen2.5 as its LLM backend).
Aside from LLMs, they have a wide range of other models, from world models, image and video generation models, and reward models. Similar to their LLMs, they mostly build on top of other models. Unlike many labs, Skywork has released some datasets with their models, such as preference and reasoning training data.
On the rise
These companies are either just getting their toes wet with open models or operating as more of academic research organizations than labs pushing the performance of models.
ByteDance Seed
seed.bytedance.com | 🤗 ByteDance-Seed
Seed is the R&D arm of ByteDance and eerily similar to Meta’s FAIR division: Diverse models with interesting research, with their papers garnering a ton of attention in the community. However, it remains to be seen whether they shoot for a Llama-style model release or continue to release research artifacts.
Here are some recent papers:
Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference
Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Seed-X: Building Strong Multilingual Translation LLM with 7B Parameters
Seedance 1.0: Exploring the Boundaries of Video Generation Models
SeedEdit 3.0: Fast and High-Quality Generative Image Editing
Mogao: An Omni Foundation Model for Interleaved Multi‑Modal Generation
Seed1.5‑Thinking: Advancing Superb Reasoning Models with Reinforcement Learning
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Seed LiveInterpret 2.0: End‑to‑end Simultaneous Speech‑to‑speech Translation with Your Voice
OpenBMB
openbmb.ai | 🤗 openbmb | X @OpenBMB
OpenBMB is an open-source community (comparable to BigScience) from Tsinghua University NLP Lab (the very same university where Zhipu was spun off from) with support from the Beijing Academy of Artificial Intelligence (BAAI) and ModelBest.
They are mostly focusing on small multi-modal models for the edge, such as MiniCPM-V-4. However, the license is rather restrictive, which is surprising given the community-driven origins of the group. Aside from model releases, they also release frameworks and specialized kernels to make sure their models run on low-end hardware.
Xiaomi (MiMo)
mi.com | 🤗 XiaomiMiMo
Xiaomi started releasing a bunch of small, capable models, ranging from LLMs to VLMs and audio models. Xiaomi updating the models quickly after an initial launch and releasing multiple variants of the models show that it is not a one-off foray into open models. However, it remains to be seen whether those are mostly research artifacts or whether they are serious about potentially pushing the frontier or competing for adoption.
Baidu (ERNIE)
yiyan.baidu.com | 🤗 baidu | X @Baidu_Inc
Baidu, one of the original names in the Chinese AI space, has only released the weights of ERNIE 4.5. It remains to be seen whether they continue to release weights of newer releases as well.
Honorable Mentions
The rest of the labs that we are watching.
Multimodal Art Projection
m-a-p.ai | 🤗 m-a-p
An open research community, releasing all kinds of models (including a truly open 7B language model with data, etc.). Now, they’re mostly known for the music generation model YuE.
Alibaba International Digital Commerce Group
aidc-ai.com | 🤗 AIDC-AI
Another R&D arm of Alibaba, mostly releasing niche models building upon Qwen.
Beijing Academy of Artificial Intelligence (BAAI)
baai.ac.cn | 🤗 BAAI | X @BAAIBeijing
As a university, the Beijing Academy of Artificial Intelligence has a high diversity of projects. They are mostly known for BGE, which are capable embedding models.
inclusionAI
🤗 inclusionAI | X @InclusionAI666
The open weight arm from the Ant Group (an affiliate of Alibaba handling mobile payments and some financial industries), responsible for Ling Lite, a series of LLMs.
Pangu (Huawei)
huaweicloud.com | X @HuaweiCloud1
Huawei is working on AI accelerators to threaten the market share of Nvidia GPUs, which are often targeted by regulations, both from the US and China. Their model releases are mostly to show what’s possible with their cards, but not without drama accusing them of upcycling Qwen models and not stating it. We would expect them to continue to release more models in the near future.
Hybrid attention refers to models like Striped Hyena, which use some non-attention blocks to make long-context inference scale better.