Latest open artifacts (#13): The abundance era of open models
Mostly thanks to Qwen, but now we're spoiled for choice and winds are shifting.
There has been a major shift in the open-weight AI ecosystem over the last 12 months from a research area and emerging industry into a functioning marketplace for ideas and adoption. If you look back to a similar collection of open models from a year ago the variance in artifact quality was extremely high and the total count of meaningful releases was far lower. There were some crucial models, i.e. the Qwens and Llamas of the world, but if one lab delayed their model or didn’t release anything, we didn’t really have much to cover.
Today, when reviewing the ecosystem with the team, we see incredible quality — and even hidden gems — across the board. Releasing certain models openly has shifted from a recruiting and marketing edge to a full-on industry standard. Many people outside of Silicon Valley will just always start with an open model for their domain due to trust, low cost of entry, and many other reasons linking back to open-source software. As of writing this, the only leading AI lab to not make a meaningful open weight release (or signal they should take it seriously, e.g. xAI) is now Anthropic.
As the average model size of daily drivers across the industry plateaus, there’s even less risk of closed models “running away with it” in terms of performance relative to their open counterparts. The differentiating factor in this regime is shaping inference into new products, which can be better offloaded to the long-tail open community than skyrocketing training costs. We saw early signs of this with Qwen Coder and expect more to come.
While many of us in the AI space focus on text-only models, as they’re positioned to be the next true platform for the broad buildout of AI, the small corners of multimodal generation models and specialized information processors represent many of the strengths of the ecosystem. This series covers it all.
Artifacts Log
Our Picks
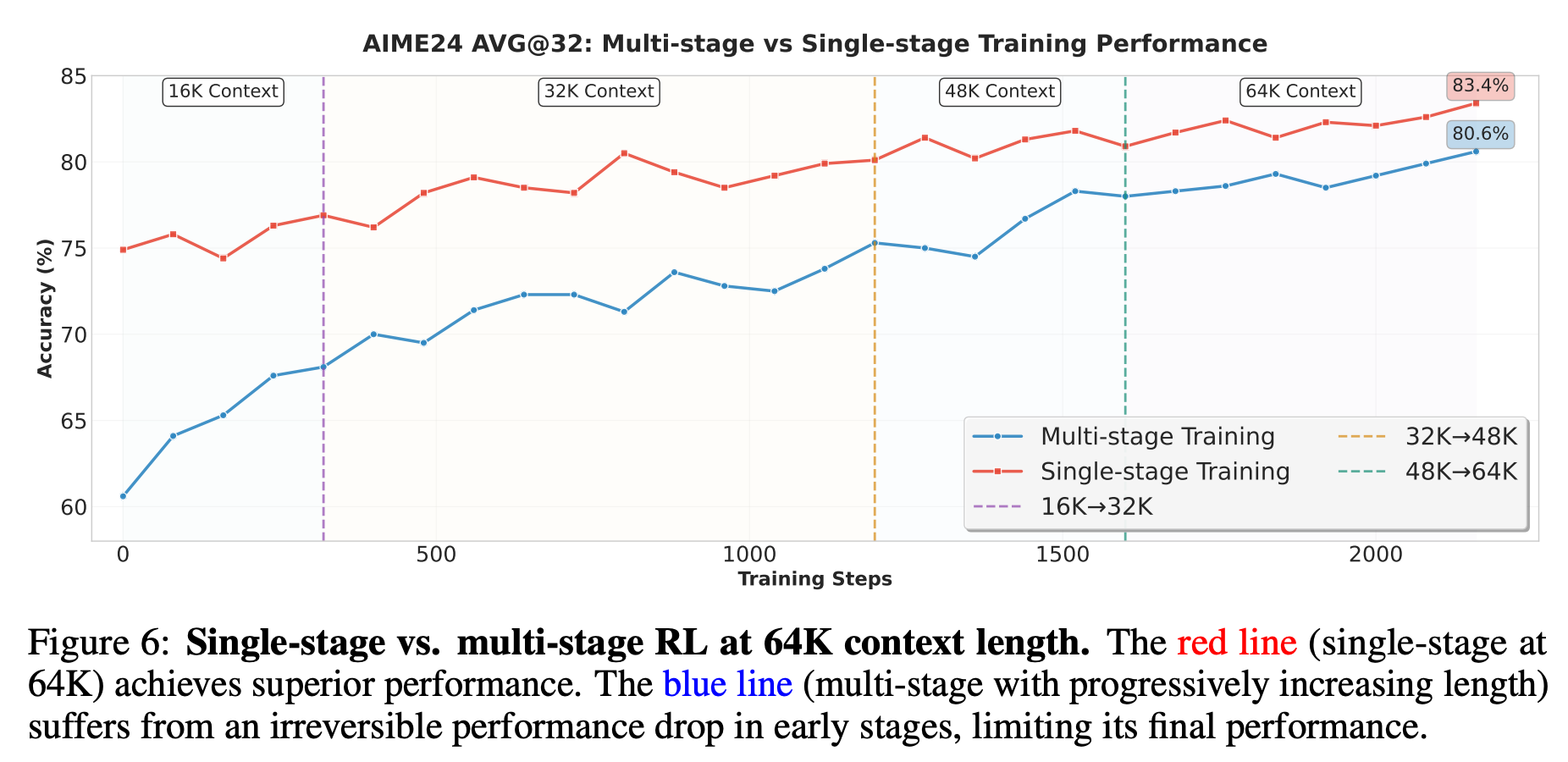
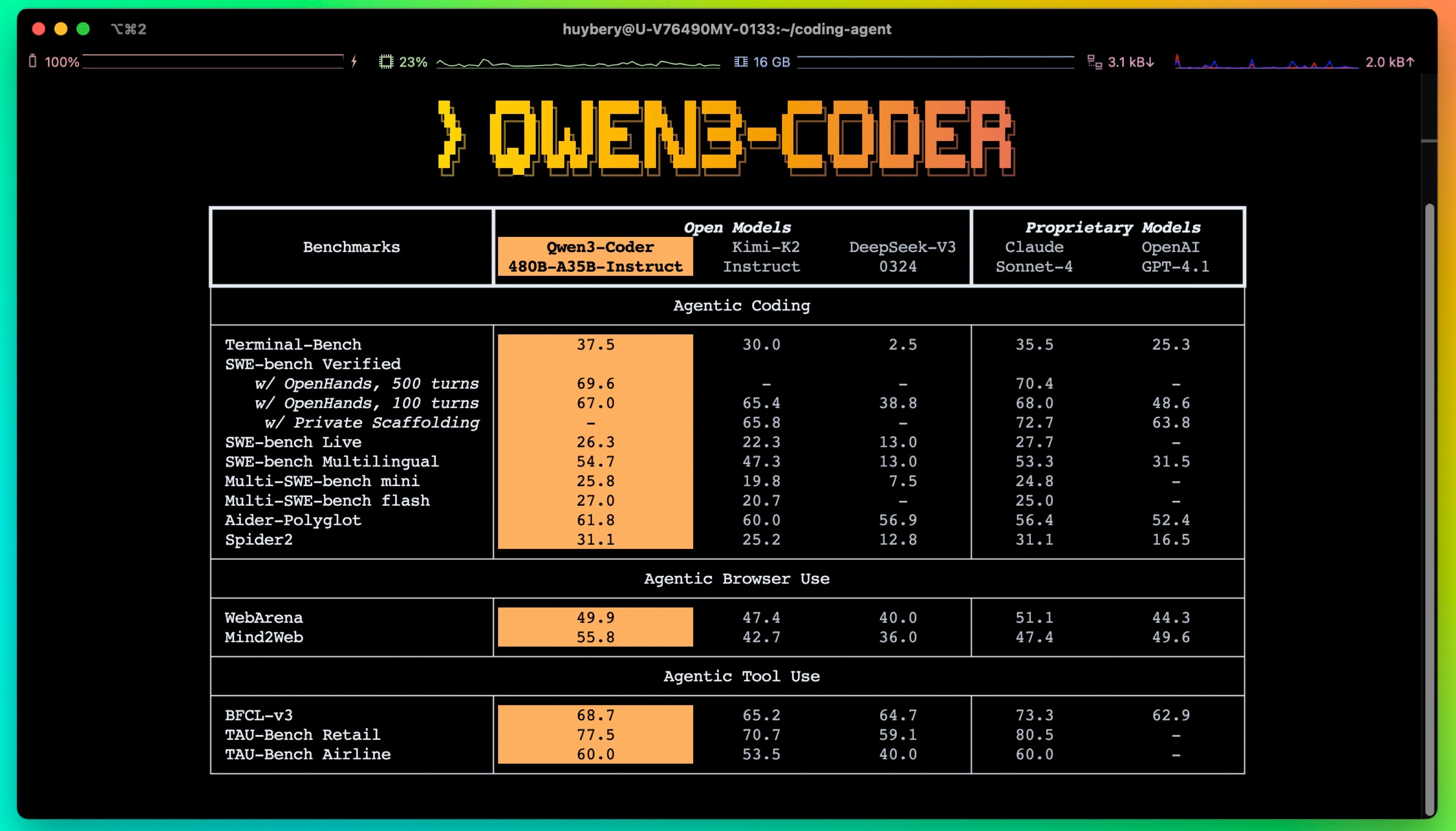
Qwen3-Coder-480B-A35B-Instruct by Qwen: Besides all the Qwen models from the last episode, Qwen just can't stop releasing new models. Qwen3 Coder comes in two different sizes — the larger of which is actually competitive with Sonnet in various tests. The model is so popular that inference providers offer subscriptions to use it akin to Claude Max to gain market share.
As we mentioned last time, Qwen is becoming increasingly professionalized and playing the Google playbook, offering 1,000-2,000 free requests per day (depending on location) for their Gemini CLI fork. Qwen thus takes coding very seriously and is certainly a credible alternative to all those closed-source models.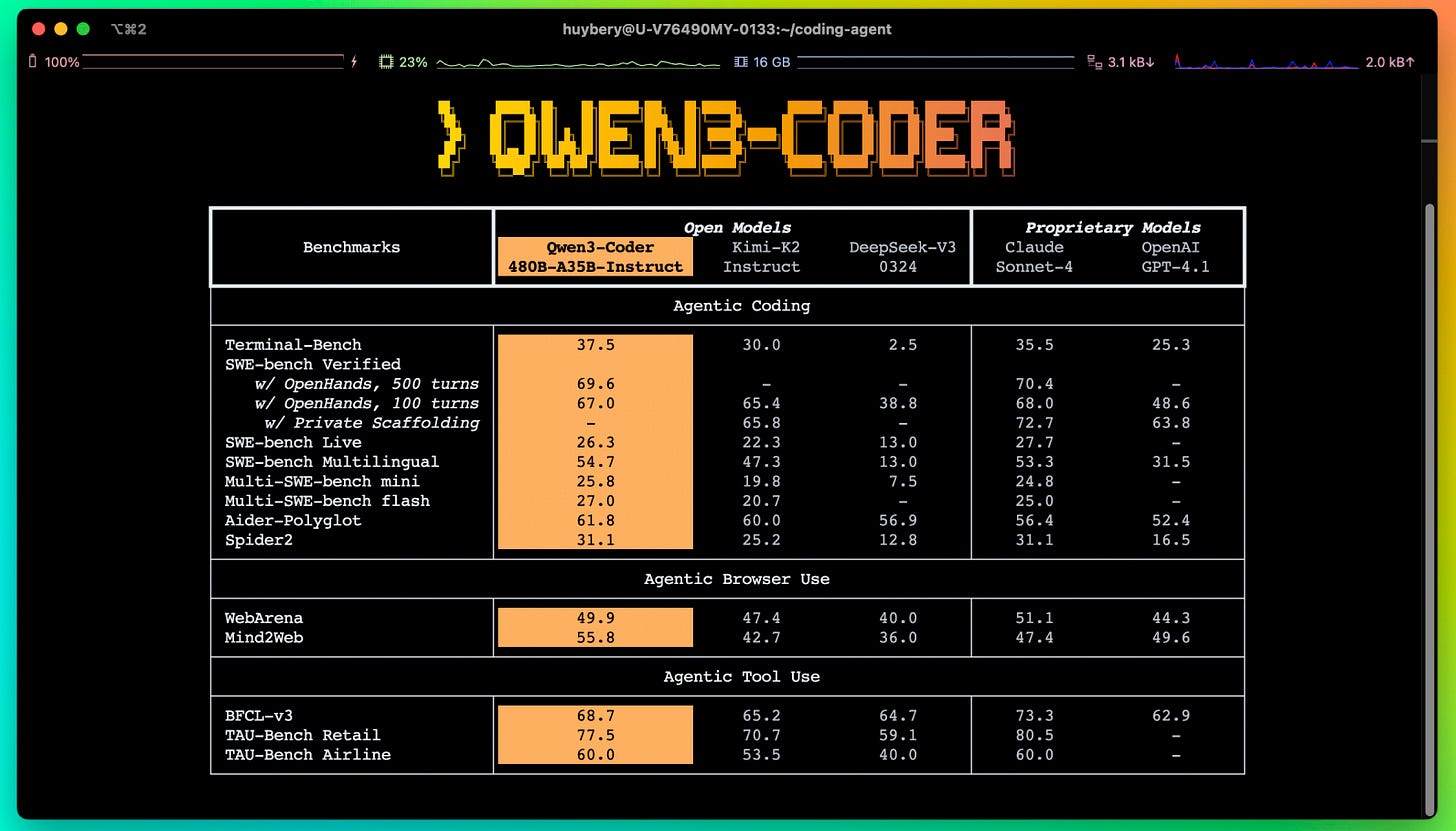
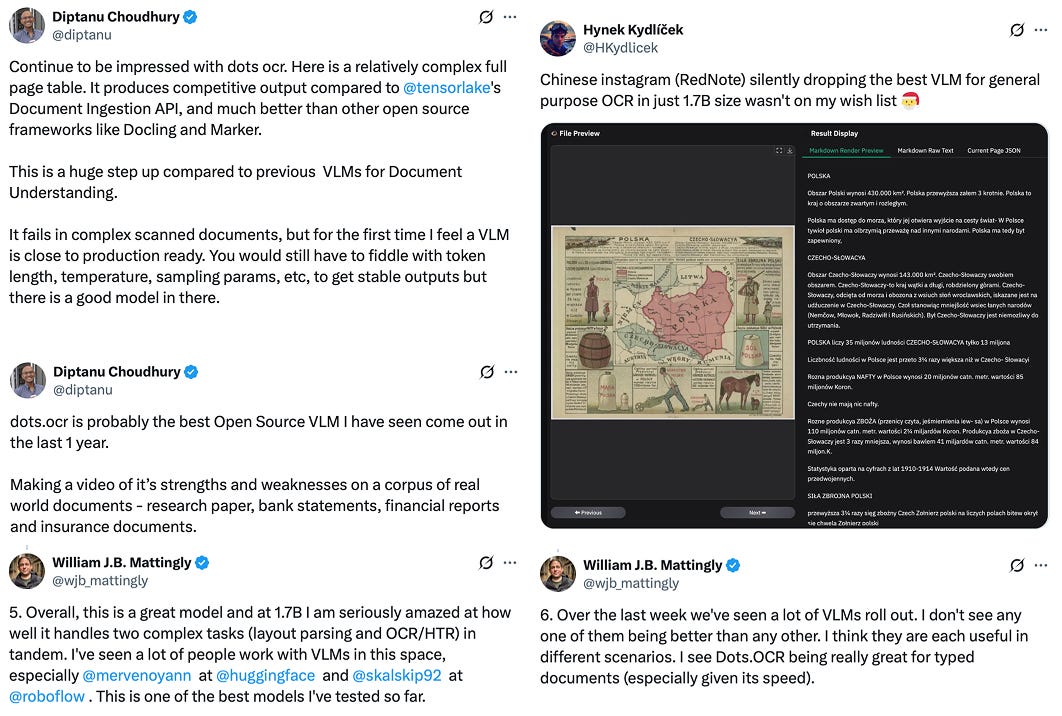
dots.ocr by rednote-hilab: RedNote (the Chinese version of Instagram) continues to release open models. RedNote is a somewhat surprising participant in the AI space, but goes to show how pervasive open model releases are in China. This Optical Character Recognition (OCR) model, building on top of Qwen3 1.7B, is not only relatively small (compared to other models in the 7-8B range), but it is also really good! There are multiple people independently reporting about its performance and being impressed by it. Also, check out this Twitter thread by William about his experience with fine-tuning the model.
Qwen3-4B-Instruct-2507 by Qwen: In the last episode, we highlighted the new instruct version of their large MoEs, as Qwen moves away from hybrid reasoning models. This cycle we want to highlight the new 4B versions (Instruct-2507, Thinking-2507). While everyone keeps training and releasing MoE models for very good reasons, dense models are the backbone for academic research and the local community. Qwen3 4B, especially in the instruct-only version, is a great model and I (Florian) have started using it locally for simple tasks (like translation), as the model is really capable and the overall latency is faster than sending requests to the cloud.
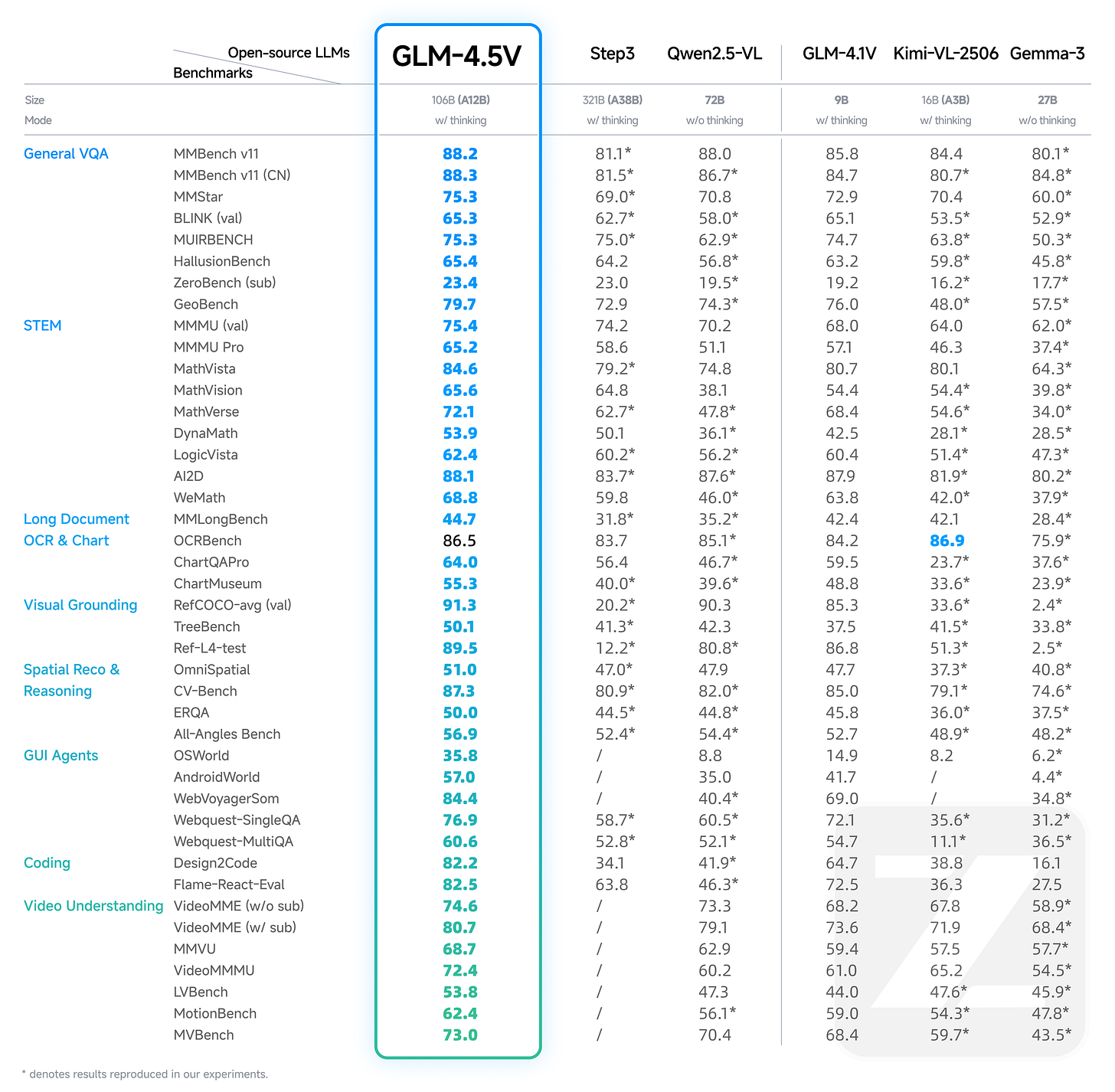
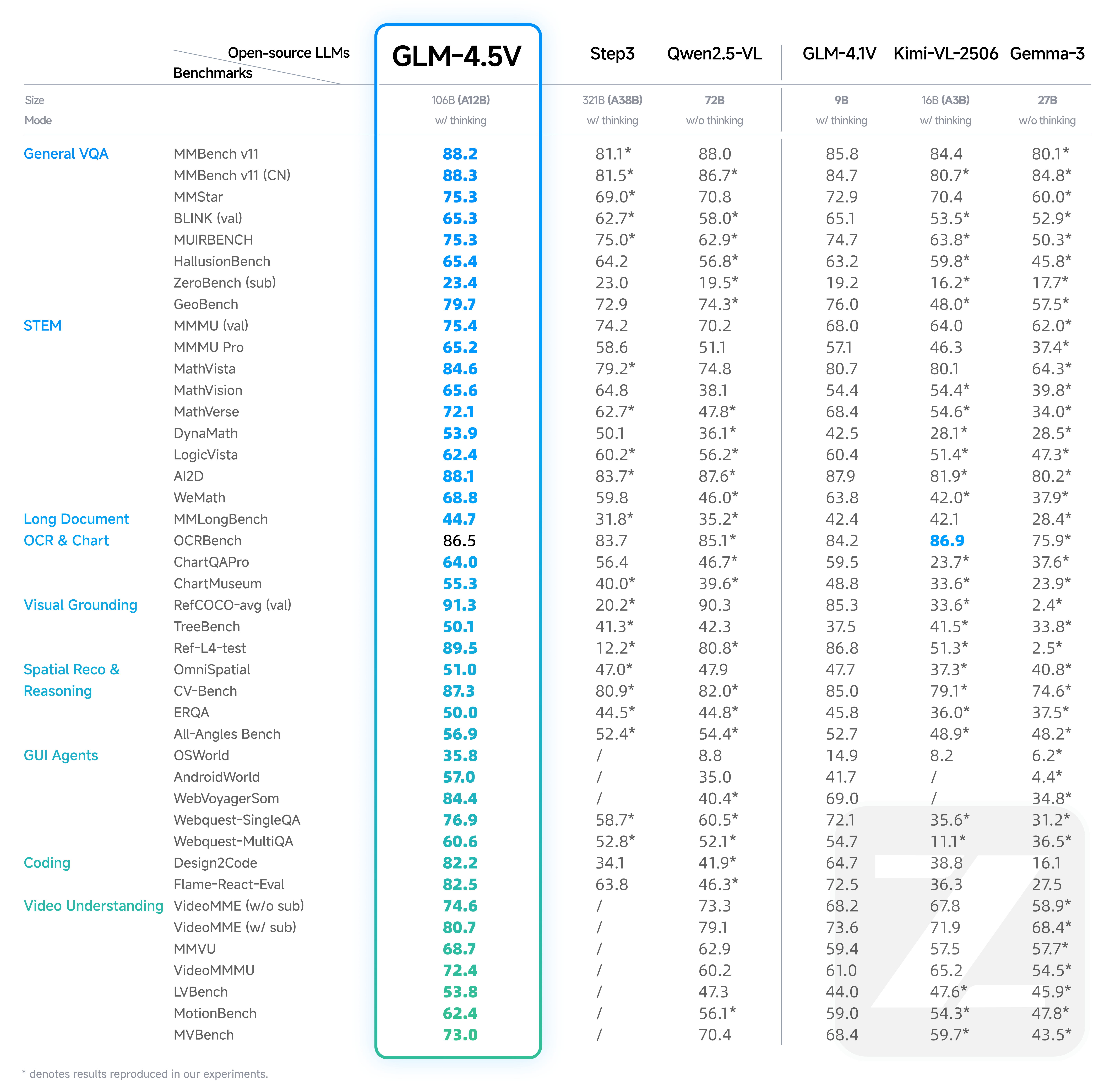
GLM-4.5V by zai-org: While Zhipu/Z.ai isn't exactly a newcomer to avid readers of Interconnects, the new GLM-4.5 model finally puts them into the well-deserved spotlight. Aside from LLMs, they also release a vision model, which, like many models, is a MoE-based model. The benchmark results are really impressive and are worth checking out.
Qwen-Image by Qwen: Yes, we know! Yet another Qwen model featured prominently in this series. But they are impossible to ignore, release model after model with (OSI-approved) licenses, and the models are good! For image generation, FLUX.1 dev racks up millions of downloads despite its non-commercial license. Qwen-Image uses Apache 2.0 and the outputs are really good. However, it is quite a chonky model, clocking in at 20B params (Flux.1 dev uses 13B params), which might hinder local adoption. However, there are first attempts at distillation to run it quicker.

Language Models
Flagship
Qwen3-235B-A22B-Thinking-2507 by Qwen: Qwen also released the reasoning-only version of the large MoE. With a simple config change, these models support up to 1M context.
Ling-lite-1.5-2506 by inclusionAI: A small-ish MoE model with 17B total, 2.8B active parameters, released under the MIT license.
Llama-3_3-Nemotron-Super-49B-v1_5 by nvidia: Nvidia is not just one of the few companies that still use Llama as a base model, it is also one of the few American model providers with a cadence and quality that matches Chinese companies, as this release proves yet again. Interestingly, it is way less censored than its predecessor as evaluated by SpeechMap:

GLM-4.5 by zai-org: The new LLM series by Zhipu/Z.ai comes in two sizes: 355B-A32 and 106B-A12. Furthermore, they also release the base models (which is rare these days!) and a detailed paper with some very nice RL experiments. Like their previous models, it is released under the MIT license.

Qwen3-30B-A3B-Instruct-2507 by Qwen: The small MoE model also gets the same treatment as the large model: A split into a reasoning and non-reasoning version, 1M context and a performance boost across the board.
gpt-oss-20b by openai: We wrote about the implications of the model in a separate post. Aside from that, the model is different from other models and cannot be a drop-in replacement for Llama or Qwen in typical pipelines. It can be used as a substitute for o4-mini-like tasks when given appropriate tools — a reasoning engine with limited world knowledge. While the scores suggest a strong multilingual model, it fell short in our usage, with others on social media reporting similar experiences.