

Coding as the epicenter of AI progress and the path to general agents
GPT-5-Codex, adoption, denial, peak performance, and everyday gains.
Coding, due to its breadth of use-cases, is arguably the last tractable, general domain of continued progress for frontier models that most people can interface with. This is a bold claim, so let’s consider some of the other crucial capabilities covered in the discourse of frontier models:
Chat and the quality of prose written by models has leveled off, other than finetuning to user measures such as sycophancy.
Mathematics has incredible results, but very few people directly gain from better theoretical mathematics.
The AIs’ abilities to do novel science are too unproven to be arguable as a target of hillclimbing.
Still, coding is a domain where the models are already incredibly useful, and they continue to consistently stack on meaningful improvements. Working daily with AI over the last few years across side projects and as an AI researcher, it has been easy to take these coding abilities for granted because some forms of them have been around for so long. We punt a bug into ChatGPT and it can solve it or autocomplete can tab our way through entire boilerplate.
These use-cases sound benign, and haven’t changed much in that description as they have climbed dramatically in capabilities. Punting a niche problem in 1000+ lines of code to GPT-5-Pro or Gemini Deep Think feels like a very fair strategy. They really can sometimes solve problems that a teammate or I were stuck on for hours to days. We’re progressing through this summarized list of capabilities:
Function completion: ~2021, original Github CoPilot (Codex)
Scripting: ~2022, ChatGPT
Building small projects: ~2025, CLI agents
Building complex production codebases, ~2027 (estimate, which will vary by the codebase)
Coding is maybe the only domain of AI use where I’ve felt this slow, gradual improvement. Chat quality has been “good enough” since GPT-4, search showed up and has been remarkable since OpenAI’s o3. Through all of these more exciting moments, AIs’ coding abilities have just continued to gradually improve.
Now, many of us are starting to learn a new way of working with AI through these new command-line code agents. This is the largest increase in AI coding abilities in the last few years. The problem is the increase isn’t in the same domain where most people are used to working with AI, so the adoption of the progress is far slower. New applications are rapidly building users and existing distribution networks barely apply.
The best way to work with them — and I’ll share more examples of what I’ve already built later in this post — is to construct mini projects, whether it’s a new bespoke website or a script. These are fantastic tools for entrepreneurs and researchers who need a way to quickly flesh out an idea. Things that would’ve taken me days to weeks can now be attempted in hours. Within this, the amount of real “looking at the code” that needs to be done is definitely going down. Coding, as an activity done through agents, is having the barriers to entry fully fall down through the same form factor that is giving the act of coding re-found joy.
Why I think a lot of people miss these agents is that the way to use the agents is so different from the marketing of incredible evaluation breakthroughs that the models are reaching. The gap between “superhuman coding” announcements and using an agent for mini projects is obviously big. The best way to use the agents is still mundane and requires careful scoping of context.
For example, yesterday, on September 17, 2025, OpenAI announced that GPT-5 as part of a model system got a higher score than any human (and Google’s Gemini Deep Think) at the ICPC World Finals, “the premier collegiate programming competition where top university teams from around the world solve complex algorithmic problems.” Here’s what an OpenAI researcher said they did:
We competed with an ensemble of general-purpose reasoning models; we did not train any model specifically for the ICPC. We had both GPT-5 and an experimental reasoning model generating solutions, and the experimental reasoning model selecting which solutions to submit. GPT-5 answered 11 correctly, and the last (and most difficult problem) was solved by the experimental reasoning model.
These competitions often get highlighted because they’re “finite time,” so the system must respond in the same fixed time as a human does, but the amount of compute used by GPT-5 or another model here is likely far higher than any user has access to. This is mostly an indication that further ability, which some people call raw intelligence, can be extracted from the models, but most of that is limited by scaffolding and product when used by the general population.
The real story is that these models are delivering increasing value to a growing pool of people.
For followers of AI, coding with AI models is the easiest way to feel progress. Now that models are so good at chat, it takes very specialized tasks to test the general knowledge of models, or many of the gains are in getting the right answer faster than GPT-5-Thinking’s meandering path.
I’m not an expert software engineer and the huge differences between models, and improvements that the individual models and systems are making, have been incredibly obvious.
I’ve said many times how Claude Code (or now Codex) are far better than Cursor Agent, which is in turn far better than Github CoPilot. GitHub CoPilot feels borderline drunk at the wheel. Cursor often feels a little distracted while still being smart, but Claude Code and Codex seem on topic and able to test the best of a model’s intelligence on the problem at hand. Yes, even the best agents often aren’t good enough in complex codebases, but it removes the need to go back and forth countless times in a chat window to see if a model can reach the end of the puzzle for you. These CLI agents can run tests, fix git problems, run local tools, whatever. The scope is constantly growing.
For the nuanced take of Claude Code vs Codex CLI right now, the answer is expensive. The best has been Claude Code forcing Claude Opus 4.1, but Codex is not far behind and comes in at a much cheaper entry point ($20/month) — Opus requires a $100+/month plan. Codex also has nice features like web search, but it hasn’t been a major differentiator yet in my use.1
The new workflow is to switch to the other agent when one cannot solve the current problem, and let it see the repository with fresh eyes, much like you pasted a question to another chatbot. The agents are just one tab away, just like the competitors for chat.
In the comparison of Claude, Cursor, and CoPilot above, the crucial component is that all of these agents can be tested with the same Claude 4 Sonnet model. The gaps are just as wide as I stated, highlighting how so many of the gains in coding agents are just in product implementations. A second version is slightly embarrassing for me, but follows as I hadn’t updated my OpenAI Codex code when trying the new GPT-5-Codex model, which resulted in an immediate massive jump in performance by changing it. It’s a new phenomenon to have a domain at the cutting edge of AI abilities where the software scaffolding of a model is felt so strongly. Product and prompts matter more than ever and this sensation will expand to more domains.
The why of these performance differences — even when using the same model — is worth dwelling on. It’s unlikely that the Claude team is that much better at general software engineering and product design — rather, Anthropic has extensive in-house experience in extracting the most from models. The current shift in models has been about how to take a set of models that are designed for question answering and other single-stream text tasks and break down problems. In my taxonomy on next-generation reasoning models, I called this ability “abstraction.”
The need to just slightly shift the model to this task explains OpenAI’s recent specialized model for this, GPT-5-Codex. GPT-5 was primarily a release about balancing OpenAI’s books with a user base approaching 1B active users in the chat format. GPT-5 is a honed tool for a different job. The evaluation scores are slightly better than the general reasoning model for this new GPT-5-Codex, but the main gains are in how behavior is different in coding tasks.
GPT‑5-Codex adapts how much time it spends thinking more dynamically based on the complexity of the task. The model combines two essential skills for a coding agent: pairing with developers in interactive sessions, and persistent, independent execution on longer tasks. That means Codex will feel snappier on small, well-defined requests or while you are chatting with it, and will work for longer on complex tasks like big refactors. During testing, we've seen GPT‑5-Codex work independently for more than 7 hours at a time on large, complex tasks, iterating on its implementation, fixing test failures, and ultimately delivering a successful implementation.
And they included this somewhat confusing plot to showcase this dynamic. I’ve certainly felt these changes when I updated the Codex software and the Codex model.
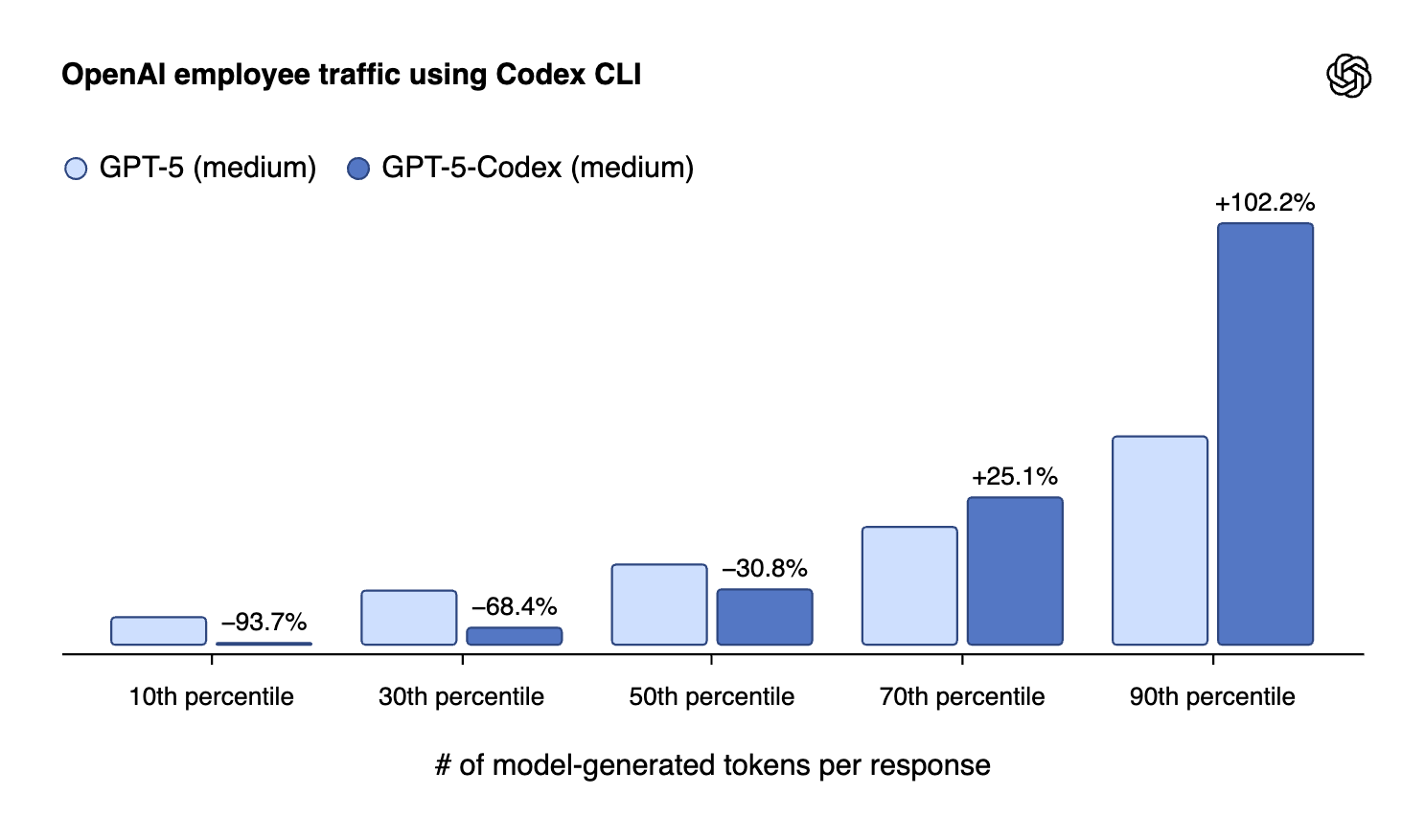
This represents another key problem I presented in my taxonomy — calibration, i.e. not overthinking.
Having specialized models and specialized products for a use case could make people think that they’re narrowing in to make progress, but in OpenAI’s case it is rather that their hands are tied financially to support the main ChatGPT application. Claude has already fully committed to code. This is due to the size that the space could expand into.
These “coding” agents are definitely going to be seen as doing far more than writing code. Yes, their primary ability is going to be writing the code itself and executing it, but what that enables is an entirely new way of working with your computer.
In my post Contra Dwarkesh on Continual Learning, I presented a view where agents are going to be given all your digital working context in order to be a research or editorial assistant available 24/7. I’ve begun putting this to use for Interconnects, where I give the agents all of my articles, metadata, interviews, and details, so I can ask them for relevant references and context for future posts. This is very underbaked and early as a project for searching efficiently over my 400K tokens of writing, but I was prompting it a few times to see any interesting references for this post, and it got me something that was useful!
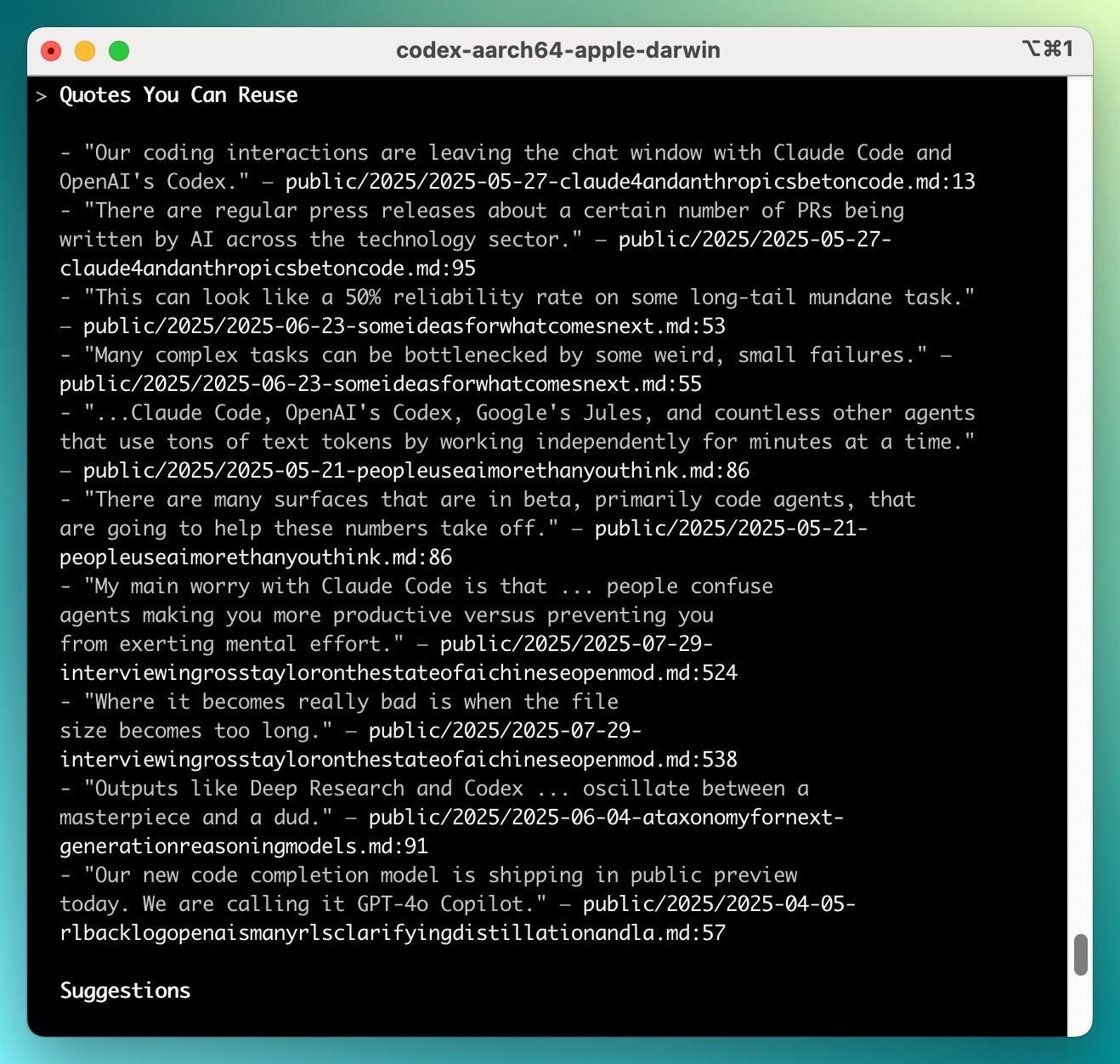
This quote from my Ross Taylor interview was spot on for the vibes of using coding agents in July:
My main worry with Claude Code is that... people confuse agents making you more productive versus preventing you from exerting mental effort. So sometimes I’ll have a day with Claude Code where I feel like I use very little mental effort—and it feels amazing—but I’m pretty sure I’ve done less work... Where it becomes really bad is when the file size becomes too long. Then the agent tends to struggle and get into these weird line search doom loops.
This sentiment is still definitely true for production codebases that are extremely complex, but the doom loop likelihood is dropping in my tests. At the same time, the joy and mental ease still applies.
Some examples of what I’ve built with a mix of Claude Code or OpenAI’s Codex CLI recently include:
A raw HTML site for my RLHF book for comparing the responses of SFT vs. RLHF trained models from the same lineage (and improvements to RLHF book itself).
Making a repository with all of the posts and content from Interconnects so I can use coding agents as editorial assistants while writing.
Improvements to the ATOM Project website.
Stripping my personal website out of Webflow’s systems (which was a mistake to sign up for during graduate school), including CMS entries and other detailed pages.
Other small scripts and tools in my day job training models.
It’s not just me building extensively with these. There are multiple open-source projects committed to tracking the public contributions of these models — two are PRArena and Agents in the Wild.
PRArena’s dashboard shows over a million PRs getting merged from the Codex web agent, dwarfing many of the competitors. This is the power that OpenAI can wield with distribution, even if the web app version of Codex is far from the zeitgeist that is CLI agents today.
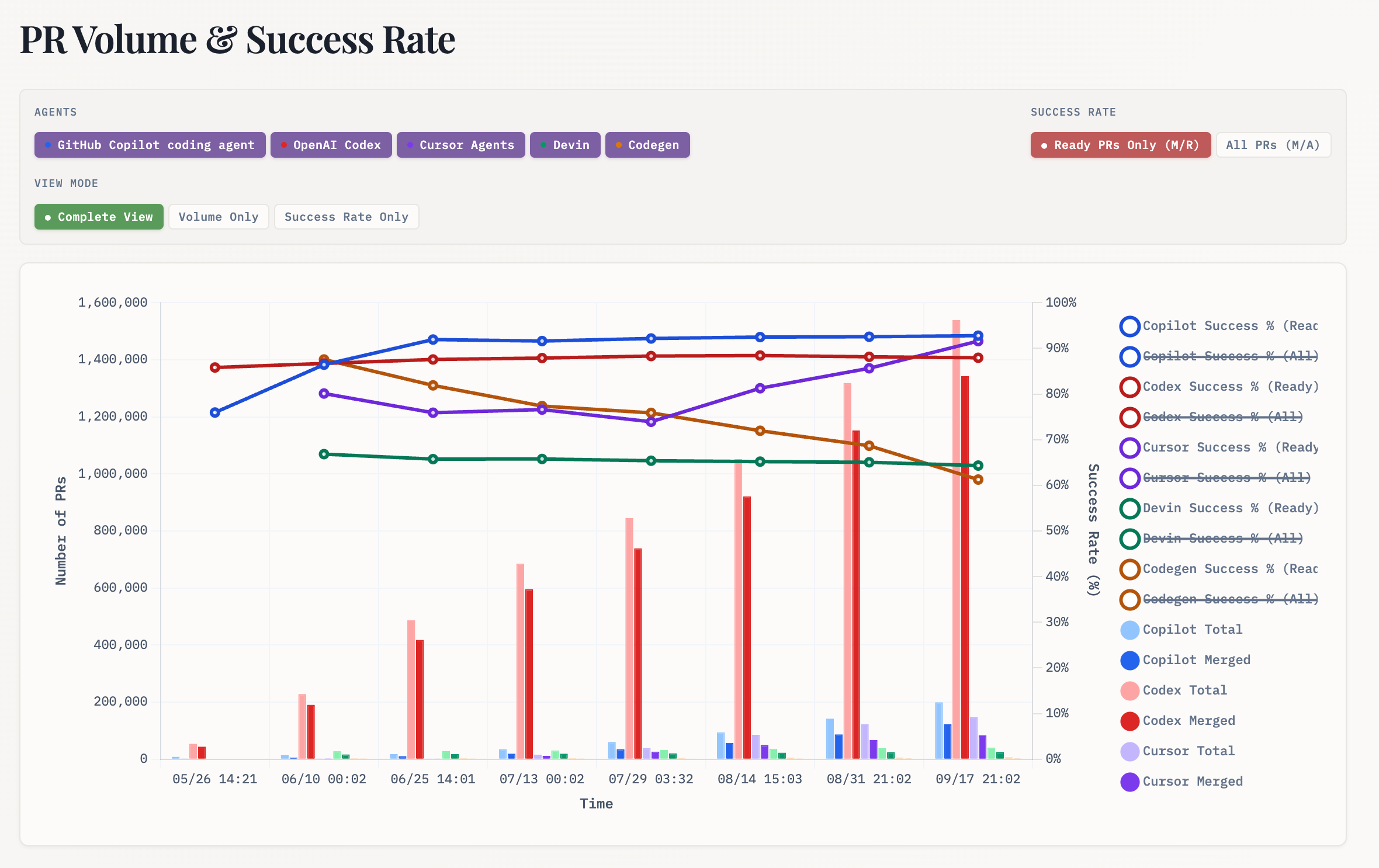
This comes with a notable asterisk in methodology that can explain many of the gaps in similar dashboards:
Some agents like Codex iterate privately and create ready PRs directly, resulting in very few drafts but high merge rates. Others like Copilot and Codegen create draft PRs first, encouraging public iteration before marking them ready for review.
The statistics below focus on Ready PRs only to fairly compare agents across different workflows, measuring each agent's ability to produce mergeable code regardless of whether they iterate publicly (with drafts) or privately.
The other dashboard, Agents in the Wild, shows that OpenAI’s coding agent is only one order of magnitude behind humans and other automations in PRs merged.
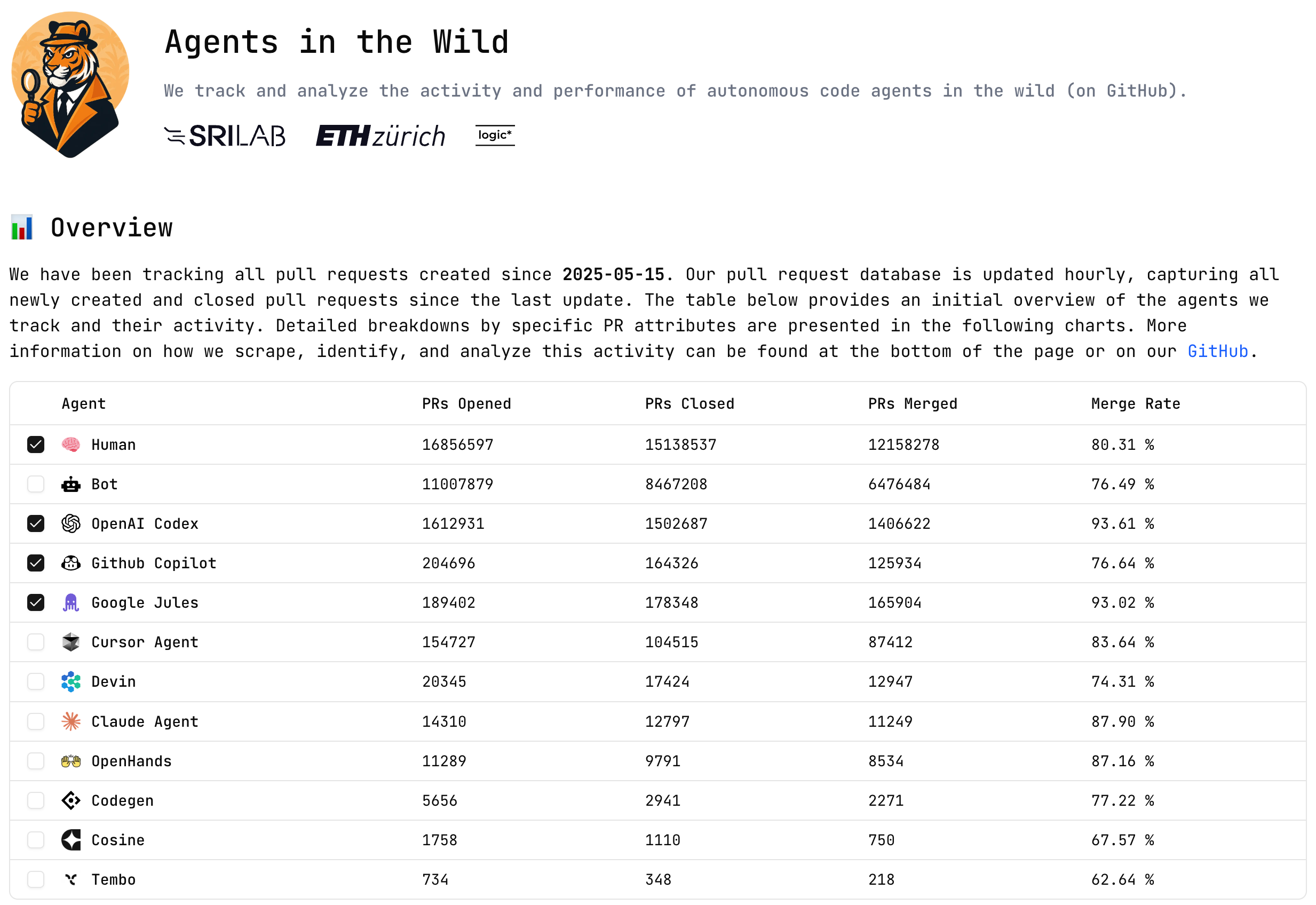
Putting this in perspective relative to Gemini or Claude:
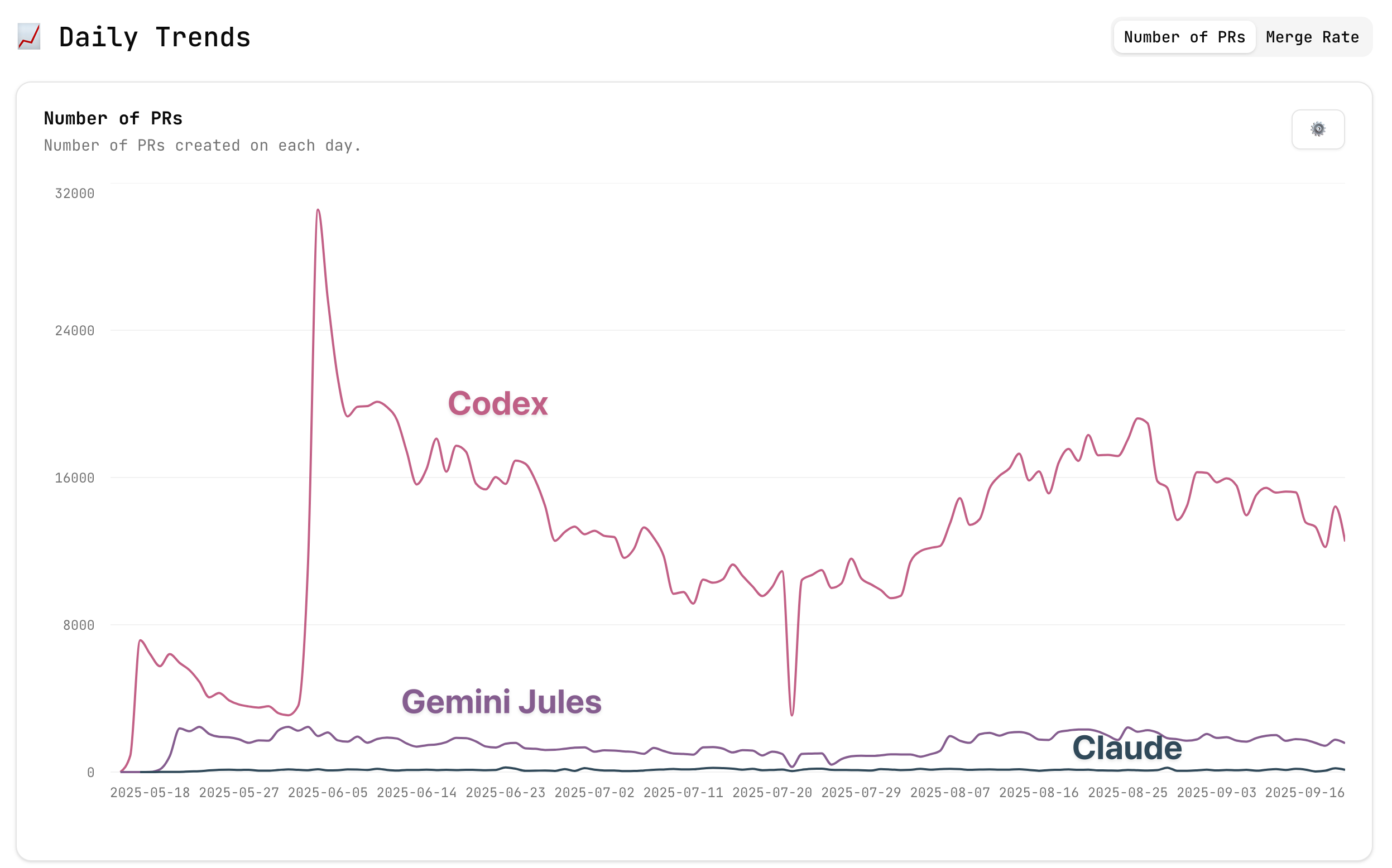
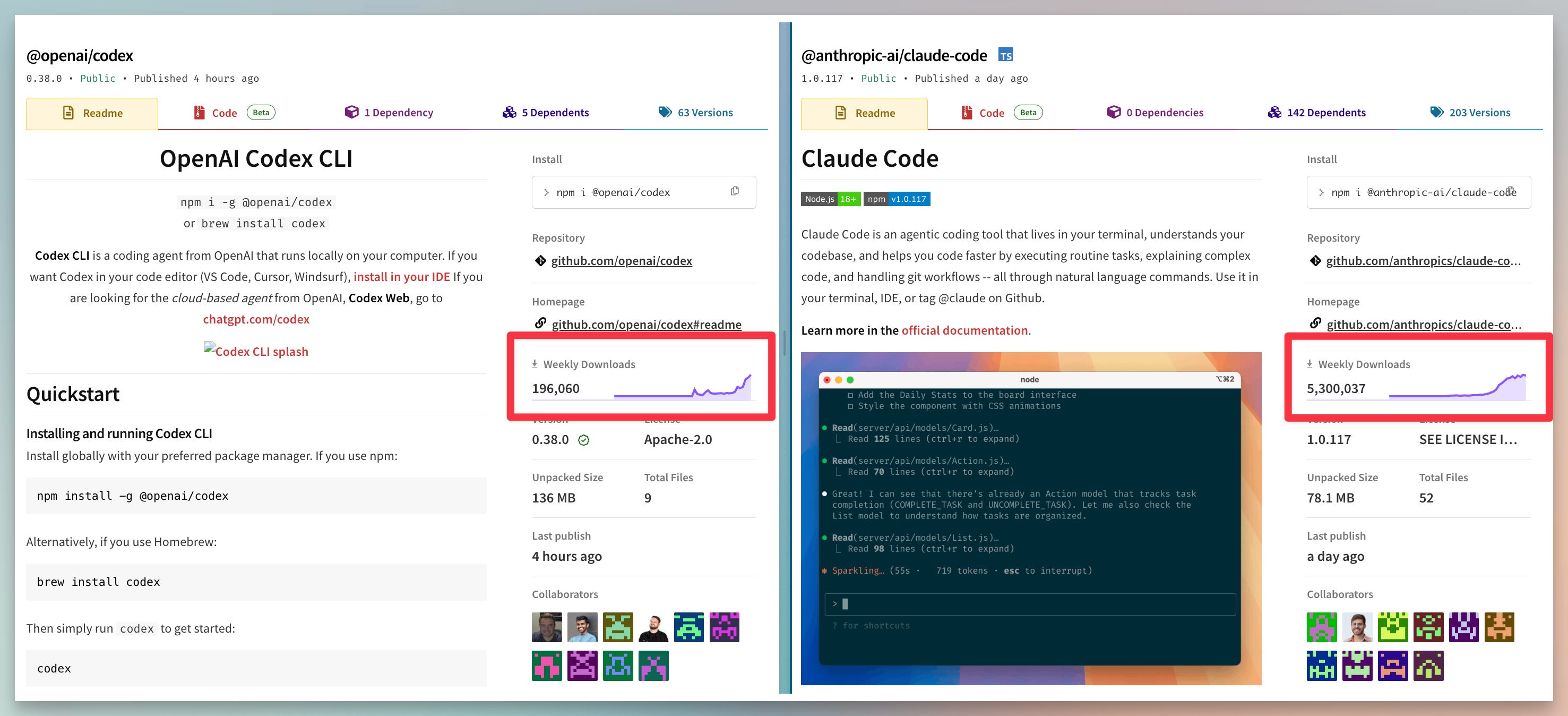
The context with this is that Claude Code is far more downloaded than OpenAI’s CLI agent Codex, but it doesn’t name its PRs the same clever way by default with the agent name in the branch. Claude Code has over 20X the downloads of Codex in the last week on NPM.
Despite the challenges of measurement, it’s clear that coding agents are taking off.
The Codex PRs above actually represent the web agent, which has the default branch name behavior, not the CLI agent. This shows the might of OpenAI’s distribution, and it is impressive how many of the PRs are actually merged (over 80%), when thousands of people are trying a new tool for the first time.
The primary difference between the web agent and the CLI agent is a reduction in interactivity. The CLI agents propose a plan and ask for feedback, or let you monitor and interrupt. Codex on the web wraps a similar behavior as the CLI agents in one system that runs all the way until it can open a PR.
Over time coding is only going to get more asynchronous and OpenAI is poised to capture this transition if it happens soon. Based on all the above evidence of coding models getting more capable, the move to this new UX for software will happen faster than people expect. The transition to fully autonomous coding will happen soon for types of work where coding models already work near flawlessly — scripts, websites, data analysis, etc. Later, complex production codebases will work best at lower levels of the stack — IDEs, CLI agents, and other things that are both interactive and best for absorbing content.
Within a few years, the two trends will converge where autonomous agents are functional and the most complex codebases can be improved with AI. Then everything can return to the chatbot window — you only need to open your IDE when you want to understand what’s going on. For most people, not having to look at the code will be a welcome change.
Progress in coding feels slower than the “emergent” abilities between model generations past, which makes it easier to keep track of. This is due to how big the range in behaviors that encompass “coding” is, but results in a fantastic area for learning how AI models evolve and iterate. This playbook will be used many times over by frontier labs in the coming years as AI models are taught to solve more challenging tasks.
There’s a quiet revolution happening, and in order to truly understand it, you need to partake. Go build something.
Here’s my command for using Codex:
alias codex='codex -m gpt-5-codex -c model_reasoning_effort="high" --yolo --search'
“Building complex production codebases, ~2027 (estimate, which will vary by the codebase)”
We are doing this right now with Claude Code.
Which application do you use for GPT5-Codex? I tried using it in Cursor using the OpenAI Codex extension. It worked, but felt clunky. I'm wondering if you have a smoother approach. Thanks!