

Back in the game
What I've been up to and what's coming soon.
It’s been a bit since you’ve gotten some content. I’ve recently produced content again that could fit on this site, but has not landed here. Hopefully this shows you that I am building again rather than just saying that I am.
In brief, here are the two recent directions that would interest folks here.
I finished my Ph.D. and got a job.
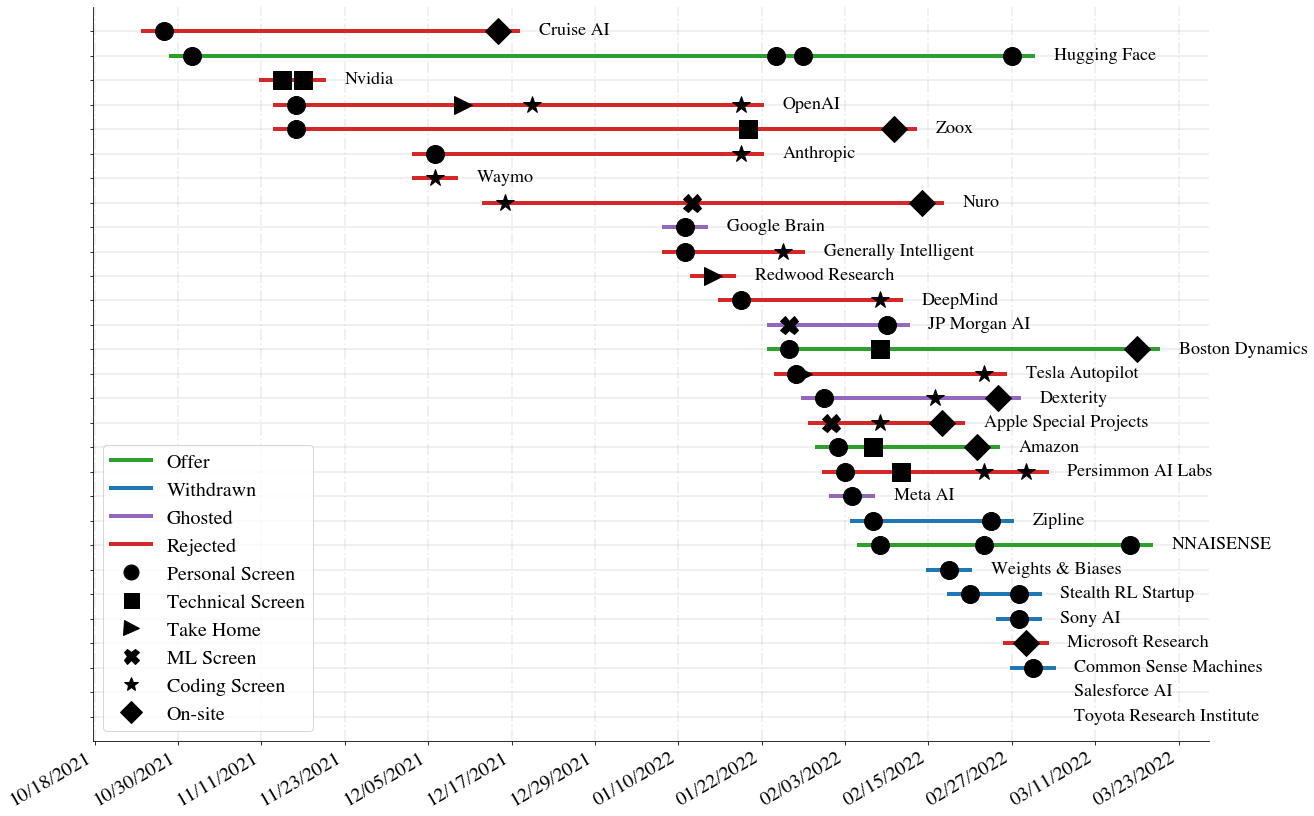
You can read about my job search and the landscape of machine learning research jobs here. I now work at HuggingFace 🤗. [blog link]
It really seems like the job market and broader economic climate of machine learning is continuing to rage on. There’s a trend where whenever a “groundbreaking” model is released, there is commentary on the long-tail of specific applications this one model will enable. Zooming out to a 5 year view, we see these tools in text generation, text analysis, image generation, and more. It is certainly moving towards a creative suite of automated world building.
I’ve also been lucky to start contributing directly in this area (to Diffusers). It moves way faster than even reinforcement learning research would. There’s huge broader appeal outside of just those with technical know-how. With this large appeal comes increased potential risk of abuse. Fitting with my history, I’ve managed to position myself in an exciting role of being a bridge between open source and ethics discussions of these models at HuggingFace. [Stable Diffusion / Diffusers blog link]
I’ll share the most exciting and high level takeaways here that are specific to me, but you can expect a lot of content to be written on this subject at the HuggingFace blog. We’ve started a “seasonal” newsletter on our ethics happenings and thoughts, I think you all would really enjoy it.
I’ll send the link to them in my next post here or on twitter, so you don’t have to worry about missing one. [Ethics @ HF blog link]

Some things in the pipeline.
Some things I have been thinking about for a while are taking the shape of blog posts:
Building on my piece How all machine learning becomes reinforcement learning, I am working on continuing this direction. There is a ton of work in natural language processing trying to asses the temporal capabilities of large language models1. This is really exciting for someone who loves the reinforcement learning (RL) framing of sequential decisions in a partially observed environment, so I have a lot of thoughts to share.
This blog post will be in synergy with a project going on at HuggingFace: Online Language Model.I’m digging into the weeds on how evaluation is done in RL. There’s a lot to be said about what the limitations of the current environments are in terms of the engineering systems they inspire us to create.
We have more coming from HuggingFace on this point too, where hopefully we can help the field overcome those limitations.
If you’re interested, leave a comment.