

The end of the “best open LLM”
Modeling the compute versus performance tradeoff of many open LLMs.
Since starting this blog with boots on the ground building the open LLM ecosystem I’ve declared there a “best open LLM” three times: Llama 2, Mixtral, and DBRX. For each of these releases, following the starting gun that went off with LLaMA in early 2023, the most practical LLM for almost any use case was going to come downstream of these models. Each of these was a substantial jump forward in the performance per parameter tradeoff of open LLMs (relative to a fixed compute budget).
Open models simply had so much to gain by scaling up. It’s extremely easy to see that a 70 billion parameter model captures so much more nuance than a 7 billion parameter model trained similarly. I’ve highlighted the three “best” models on a chart from Maxime Labonne on Twitter, modified via the addition of Grok 1 from xAI.
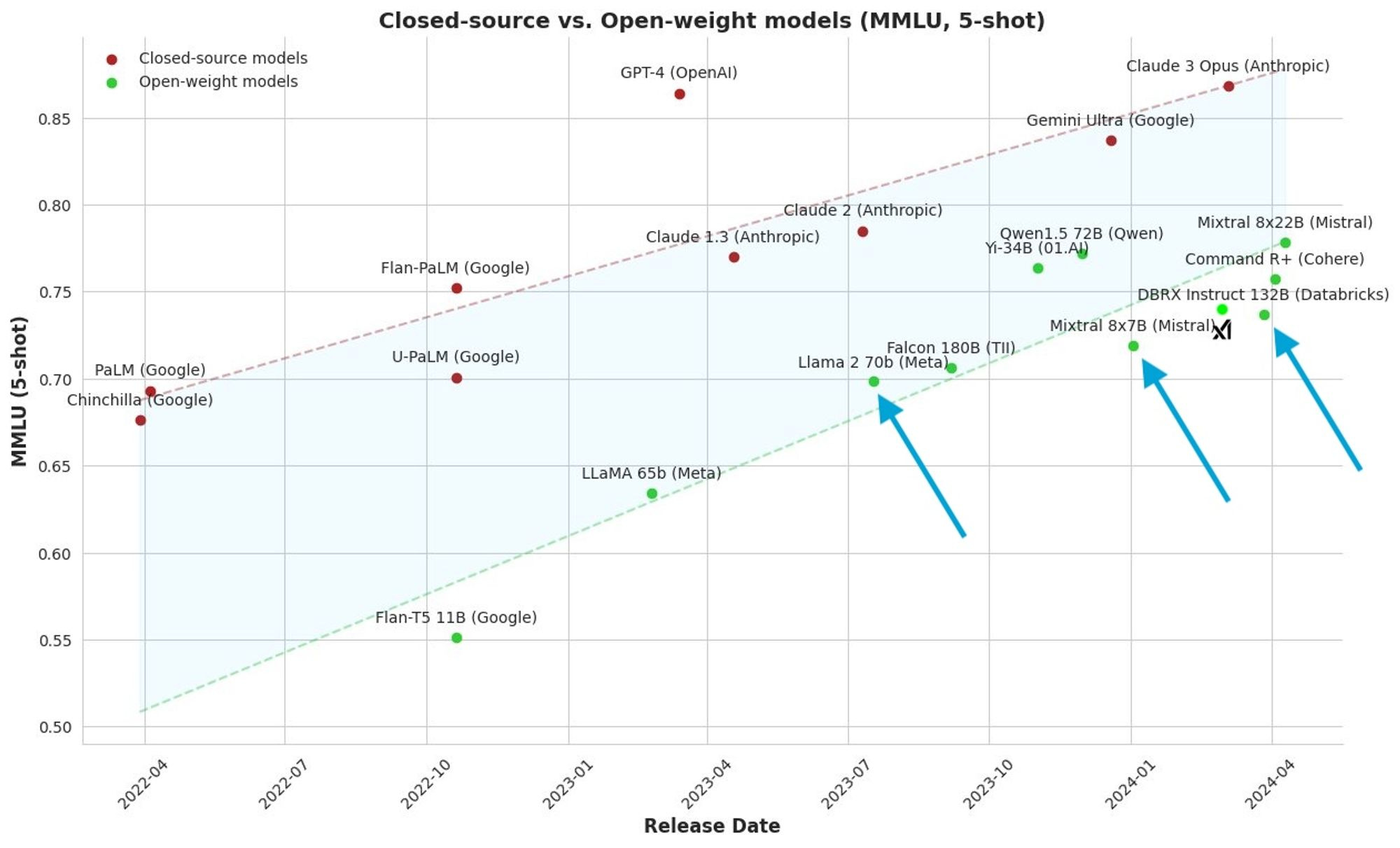
The shift from Llama 2 to Mixtral was mostly about performance compression, moving from 70 to 13 billion active parameters with similar scores. The step to the DBRX model was about taking proportional steps up in performance and size — without taking into account training token counts, more on that later.
Soon after the DBRX release, the landscape of openly available LLMs has changed notably with two models, Cohere’s Command R+ and Mixtral’s new 8x22B base model.
Command R+ is the first openly available model that has beaten any GPT-4 version on LMSYS’s ChatBotArena. Can a model with a strict non-commercial license take the label of “best open model?”
Mistral 8x22B is a new stronger base model released on April 10th with little information. Do models like Mistral 8x22B or DBRX with 36 or 39 billion parameters respectively actually support the ecosystem so that it’s “best” for everyone?
For example, some of my former colleagues at HuggingFace quickly responded with a fine-tuning of the new Mistral model, training it with a largely unproven alignment method, Odds Ratio Preference Optimization (ORPO), on 32 H100 GPUs for 1 to 2 hours. When you assume that any decent model needs some trial and error margins on compute costs, there are very few players in the alignment space with this type of compute to throw around. This new model didn’t entirely pass my vibes test on HuggingChat, but try it for yourself.
The last few weeks of releases have marked a meaningful shift in the community of people using open models. We’ve known for a while that no one model will serve everyone equally, but it has realistically not been the case. On The Retort, I described it as open ML entering the trough of disillusionment (of the Gartner Hype Cycle).
This article, and its main declaration that there isn’t much of a point trying to argue for a singular best open LLM, is actually late. The release of xAI’s Grok 1 weights actually marked this most clearly. Yi 34 B and Qwen 1.5 72B really could’ve marked this transition point too. Qwen 1.5 72B Chat is practically tied with GPT4 on the LMSYS leaderboard, coming in slightly below, and was released about 5 months ago. As far as I can tell, the Yi and Qwen models largely are under-adopted due to the bias of the narrative in aligning open models — my own included. These models could have been labeled as the state-of-the-art LLM, but that’s not really the point.
Compute efficient open LLMs
To me, the best model going forward is going to be based on the weighted performance per parameter and training token count. Ultimately, a model keeps getting better the longer you train it. Most open model providers could train longer, but it hasn’t been worth their time. We’re starting to see that change.
If we start by plotting the total parameter count versus the MMLU score, it’s obvious that it isn’t that insightful. Models are clumped at popular parameter counts, but it makes progress look too rosy and simple.
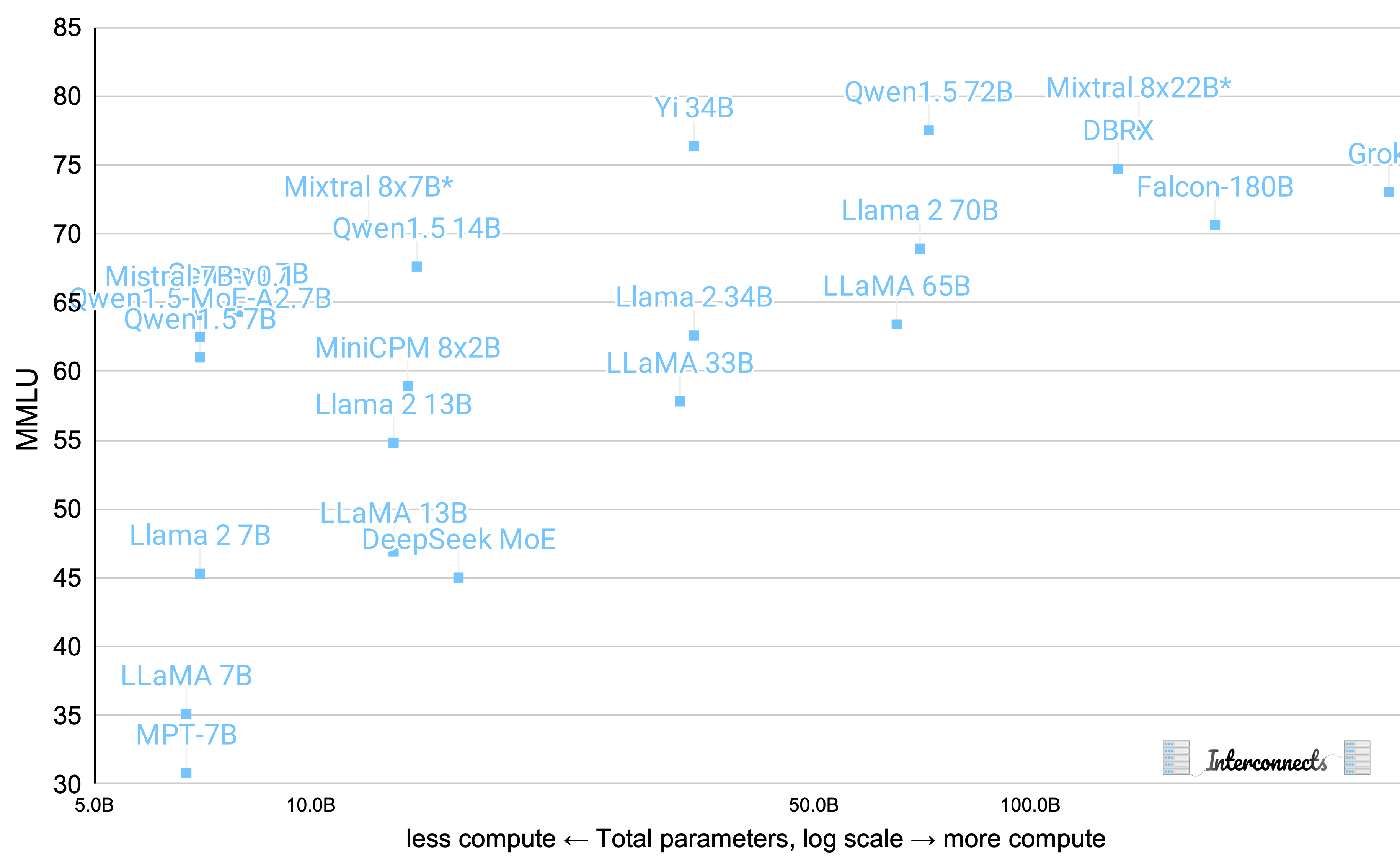
Most of the gains made in the last year and a half of open models are purely from throwing more compute at the problem. I made a little model showcasing how open models compare on compute versus MMLU tradeoff. Note, I assumed the token count of Mistral’s models to be 10T tokens, which is based entirely on rumor and much higher than most of the models (other than DBRX at 12T). Raw data is available here and please let me know if you have more training token counts I couldn’t find.

Let’s start with the two Llama series to showcase the compute versus MMLU trend. Reminder, MMLU, Massive Multitask Language Understanding, is the current benchmark that folks track most closely for base models (and fine-tuned models go to LMSYS ChatBotArena). Compared to the first image, the concentration of the trend is remarkable! More compute simply equals more performance. The question is: What is your compute budget for each model? How do you optimize that as a fixed resource?

Normalized by compute, it shows that most of the gains from the Llama 2 line of work come from scaling compute. There are more gains, as MMLU is just one measurement, but it’s important to illustrate how simple compute can be in terms of performance — even for open models. Now, let’s extend this figure with more of the open base LLMs from 2023.
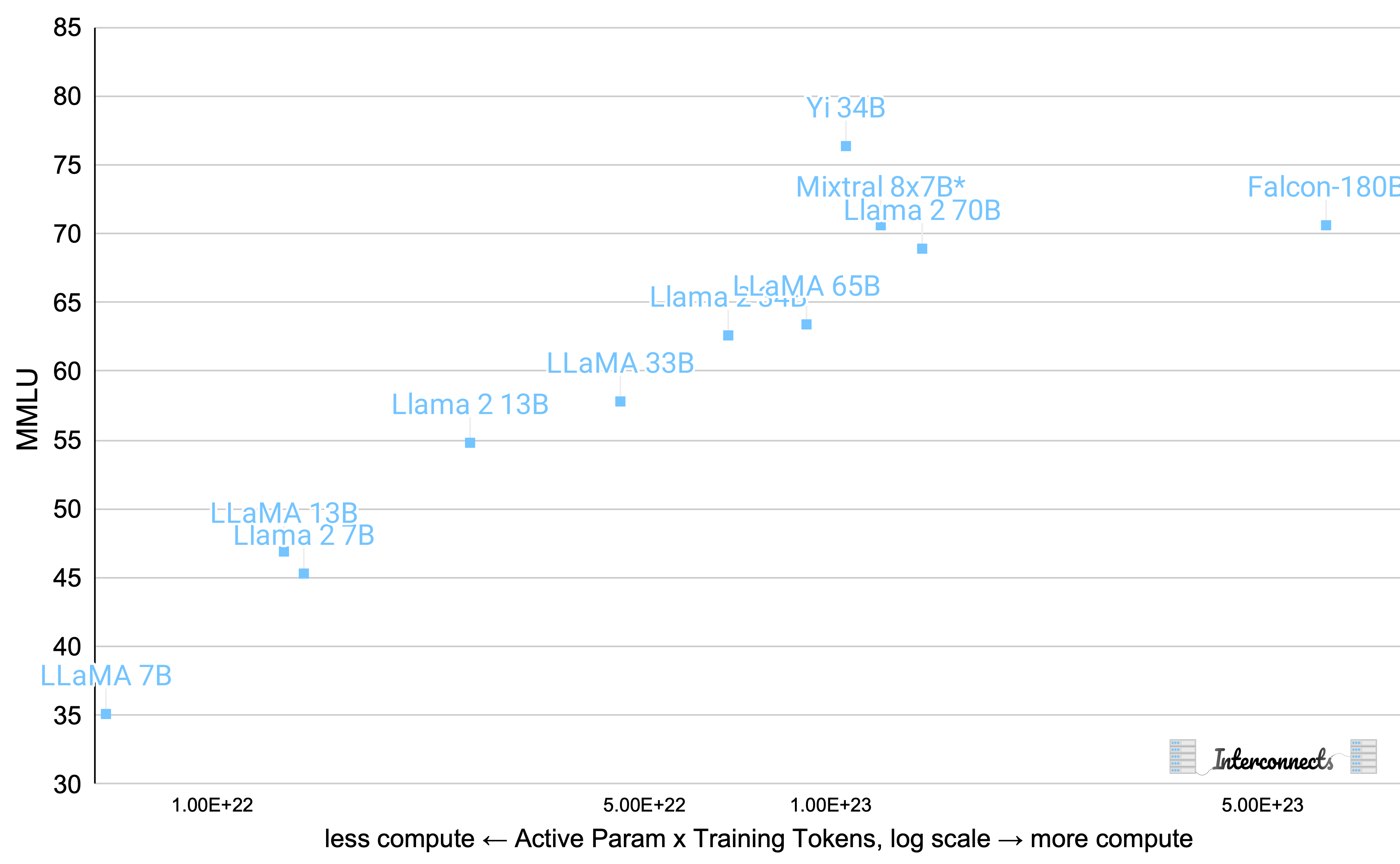
Most of these are in line, with Yi 34B and Mixtral being the ones that look the most interesting. Here’s an annotated version showing where Mixtral could be with different assumed token training counts.

If we assume that Mixtral 8x7B was trained on the same number of tokens as Llama 2, 2 trillion, it would look like a total outlier, which is unlikely. Now, let’s add the models for 2024, which shows that models are not only getting bigger, but they’re getting better. The models are improving in MMLU with constant compute budgets.

For models at the size of DBRX or Mixtral 8x22B, it’s pretty infeasible for most of the open community to do much with them. This size class will continue to be functional, but the models that are 10x bigger (as a Llama 3 variant is rumored to be), fill a different niche in the open community. The most important models will represent improvements in capability density, rather than shifting the frontier.
The core difference between open and closed LLMs on these charts is how undertrained open LLMs often are. The only open model confirmed to be trained on a lot of tokens is DBRX. Many models being in the 2-3 trillion token range represents a huge change from the industry model providers, where their base models are probably trained on all of their effective tokens. In some ways, it’s easier to make the model better by training longer compared to anything else, if you have the data.
Finally, here’s a zoomed-in version with the models most folks care about. As more open-base models come out, I’ll continue to use this model to showcase the efficiency of the model.

I’m excited to add Llama 2.5 or 3’s performance to these plots in the near future. In the past, the Llama models were released into an open plain with almost no competitors. The large delay we’ve seen is likely due to the change in culture from being the only player, where shipping fast is the easiest way to win, to being one of many players. I also expect Meta to be trying to fine-tune a model that scores well on LMSYS’s leaderboard given the cultural weight of that evaluation and the relative failure of Llama 2 Chat’s release.
Newsletter stuff
I’m giving a lecture on Thursday at Stanford’s CS25, Transformers United seminar course. I’ve put together a cool collection of open artifacts to go along with my slides.
Additionally, I’ve created collections to track all the artifacts I link in the models section, so it’s easier to go back and find a fine-tuned model you knew you saw 3 months ago.
Models, datasets, and other tools (2024 artifacts, 2023 artifacts)
A new smol MoE model, JetMoE, was released by a multi-institution (some academics) group! Great to see this.
Another small base model, MiniCPM, was released by OpenBMB, maybe most notable for having a vision variant. OpenBMB has a pretty good track record on releases! Paper is here.
Stable LM 2 12B was released, and the chat version particularly looks fairly strong!
The miscellaneous fine-tunes are continuing to pump out. This project, bagel, is doing Tulu style work by mixing tons of different datasets.
CodeGemma and RecurrentGemma came out, which is nice to see from Google, but not a ton of reason for excitement immediately for me.
A cool new model, Rho, showed up from Microsoft that decides on which pretraining data to include by passing weights through a reward model! Awesome!
Progress on “flattening” mixture of expert models continues — Mistral 22b — i.e. making it so only 2 experts exist and are used for every batch, lowering compute requirements.
Links
This was a great talk from Tatsu Hashimoto (Alpaca team prof.) on how to contribute to the open ecosystem as an academic.
You really should watch 3b1b’s introduction to Attention.
Housekeeping
Audio of this post is available (soon) in podcast form or on YouTube.
My real podcast is at retortai.com.
Paid subscriber Discord access in email footer.
Referrals → paid sub: Use the Interconnects Leaderboard.
Student discounts in About page.