Latest open artifacts (#11): Visualizing China's open models market share, Arcee's models, and VLAs for robotics
Artifacts Log 11.
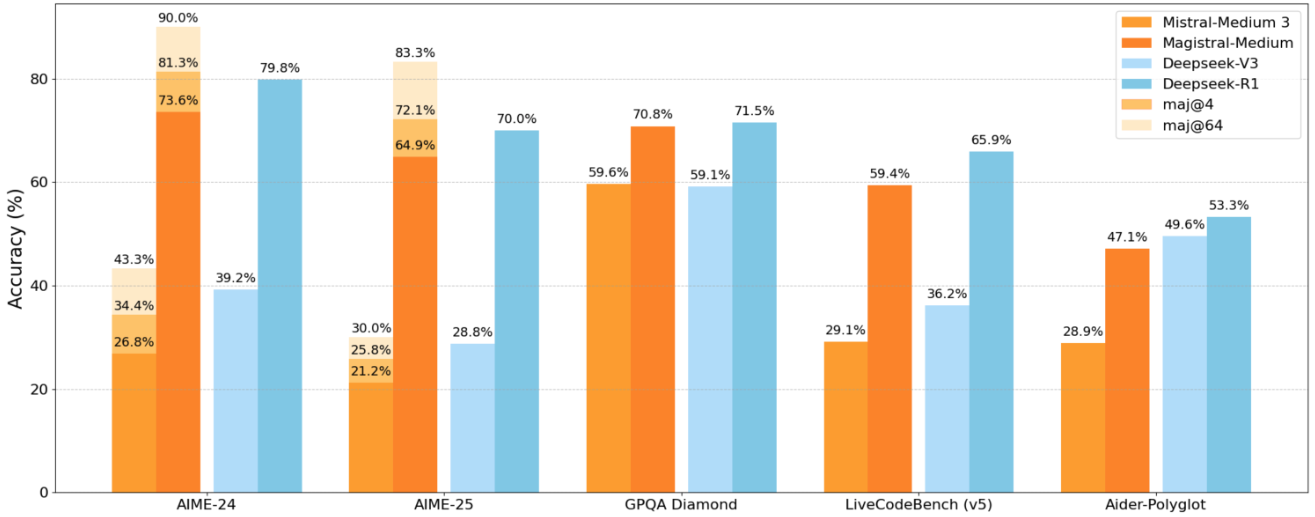
In previous posts, we've noted in text how Chinese models currently dominate the space of open models. We analyzed the geographic distribution of all models from past Artifacts collections to quantify it. It turns out that most of the artifacts are released by Western organizations (~60%), but most of these rely on Chinese models (i.e. Qwen). Crucially, on top of counting, Chinese models also have been qualitatively more impactful on the direction of the open ecosystem by releasing models closest to the frontier of performance with the most permissive licenses.

We present only a selection of models in the Artifacts series based on a mix of our perceived immediate and long-term impact. Our analysis of is broader than just text-only language models, including image/video generation models where Chinese labs are more dominant.
For attribution, we count fine-tunes according to the team that released them, i.e., a Qwen fine-tune published by a Western company is marked as Western.
When looking into the models heritage (as reported by HuggingFace), the picture is as expected: Qwen is the first choice for anyone who fine-tunes their model.1
Also, RL and reasoning is now part of a lot of the model releases as part of the training pipeline. Therefore, we stop making reasoning its own category. Together with links being broken out into its own series, these posts should have a more streamlined structure. Our picks, then models, then datasets.
Our Picks
comma_v0.1_training_dataset by common-pile: EleutherAI (and many others), known for various open-source projects such as The Pile, have shared their first stab at an openly licensed dataset with "Common Pile", spanning 8TB from various sources, such as code, legal documents or public domain books. This differs from other datasets for open-source models because those rely on a “fair use” like argument where publicly, unlicensed data is seen as fair to train on — 100% of this dataset has a clearly attributed, permissive license. Work in this direction is still rare, so every addition to those efforts is extremely valuable.
Virtuoso-Large by arcee-ai: Arcee AI, which we've featured in previous episodes with some of their fine-tunes, have started pre-training their own models, starting with a 4.5B parameter model (blog). This has led to them opening their previously closed models to the public, released under permissive licenses. This model is their flagship model, a 72B fine-tune of Qwen2.5. The move to open older models is really commendable, we hope others will follow suit!
moondream2 by vikhyatk: The moondream2 team is known for their excellent execution and attention to detail. This model release marks their first reasoning release. For training, they avoided using a larger teacher model, making the release even more impressive. This update delivers the usual improvements, most notably in object detection tasks. The model uses the same repository as previous releases, so update the weights if you downloaded the model previously.

Qwen3-Embedding-0.6B by Qwen: Qwen has entered the retrieval scene as well. While the community already fine-tuned Qwen2 and Qwen2.5 for various embedding tasks, the Qwen team has now started to release models on their own. As usual for the team, the models are solid in the related benchmarks and likely perform well in downstream tasks.
MiniMax-M1-80k by MiniMaxAI: Minimax has also released their first reasoning model, based on their own hybrid attention MoE architecture. They release two models, one with 40K and one with a whopping 80K thinking budget, which is the most of any available model, both open and closed. However, this does not necessarily mean that they are the best models for reasoning tasks; in our tests, the model really tends to overthink and spend a lot of tokens to reconsider its answers.

Models
Flagship
Magistral-Small-2506 by mistralai: Mistral has joined the party of reasoners with an open release building upon Mistral Small. The accompanying technical report provides a lot of details.