

Latest open artifacts (#17): NVIDIA, Arcee, Minimax, DeepSeek, Z.ai and others close an eventful year on a high note
Ending the year with a bang.
Happy new year! The open ecosystem hasn’t slowed down at all over the holiday period, which we know will continue right into and through 2026. There are a lot of great models in this issue, from GLM 4.7 and MiniMax M2.1 — open models that are starting to be “good enough” in the Claude Code form factor — and much stronger open models from Nvidia and Arcee to support the U.S.’s renewed motivation in the space.
Our Picks
K2-V2 by LLM360: LLM360, a project from MBZUAI, is back with their fully open-source model series. This model is a 70B dense model, and they release the whole data, from pre-training (12T tokens) to SFT, which they generated using GPT-OSS 120B at all three reasoning levels. They also release multiple checkpoints from the various stages of training. We expect a lot more from them specifically and the growing fully-open model community in 2026!
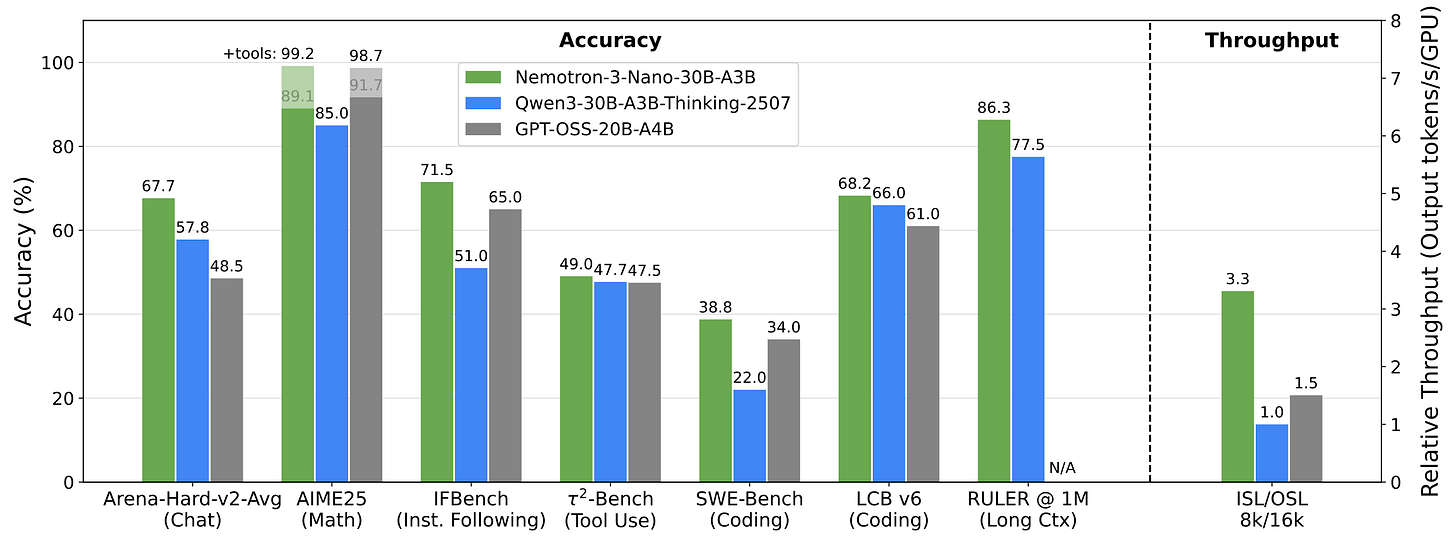
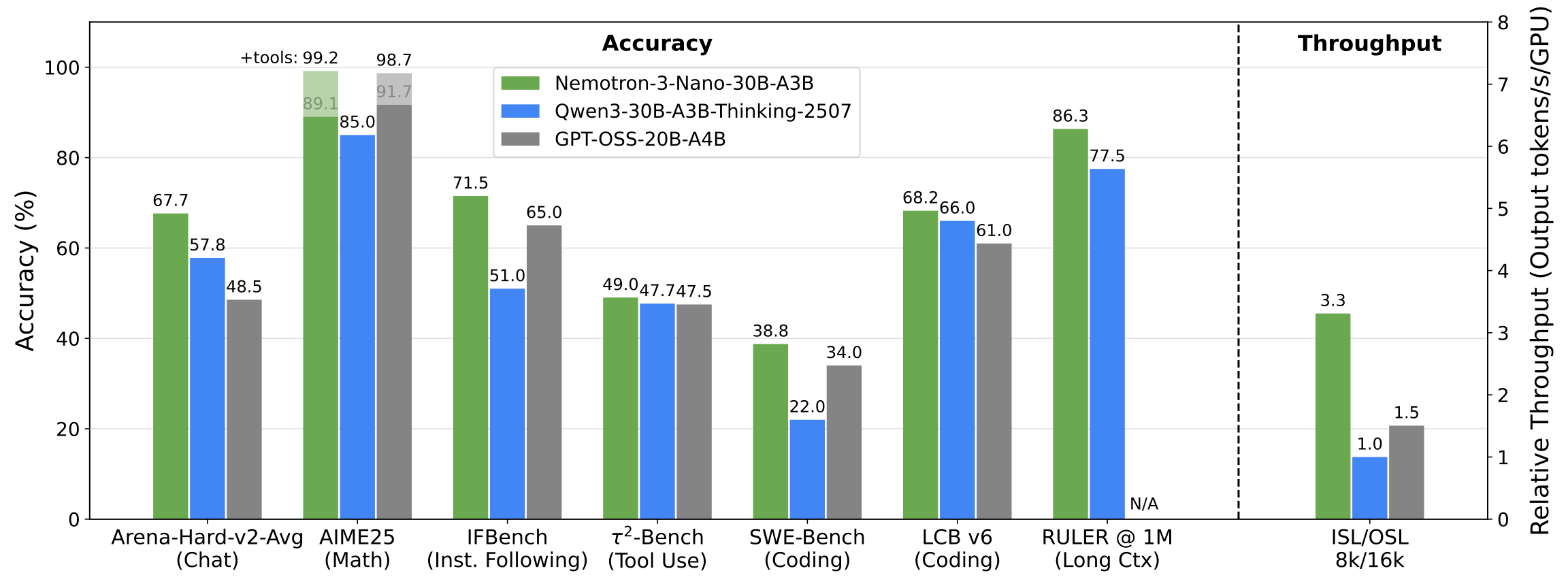
NVIDIA-Nemotron-3-Nano-30B-A3B-BF16 by nvidia: As luck would have it, NVIDIA released an update to their Nemotron series right after our year in review tierlist for 2025. Similar to other NVIDIA models, the vast majority of the data is released openly. Furthermore, they continue with the Mamba2-Transformer architecture, but make it a MoE as well. And to top it all off: They also announce two more sizes, slated for a release in H1 2026 (likely on the earlier side): Super, ~100B-A10B and Ultra, ~500B-A50B, which will use Latent MoE and multi-token prediction (MTP). 2026 will be an exciting year!
Trinity-Mini by arcee-ai: Arcee is not an unknown entity to the avid Artifacts reader. Now they are coming with a series of models: Nano, a 6B-A1B MoE and Mini, a 26B-A3B MoE are available today and trained on 10T tokens. They also plan to release Large, a 420B-A13B MoE trained on 20T tokens, in the coming weeks. We played with the Mini model and were impressed by its capabilities! As readers know, we’re also very happy to highlight new and rapidly improving open model builders in the U.S. using permissive licenses.
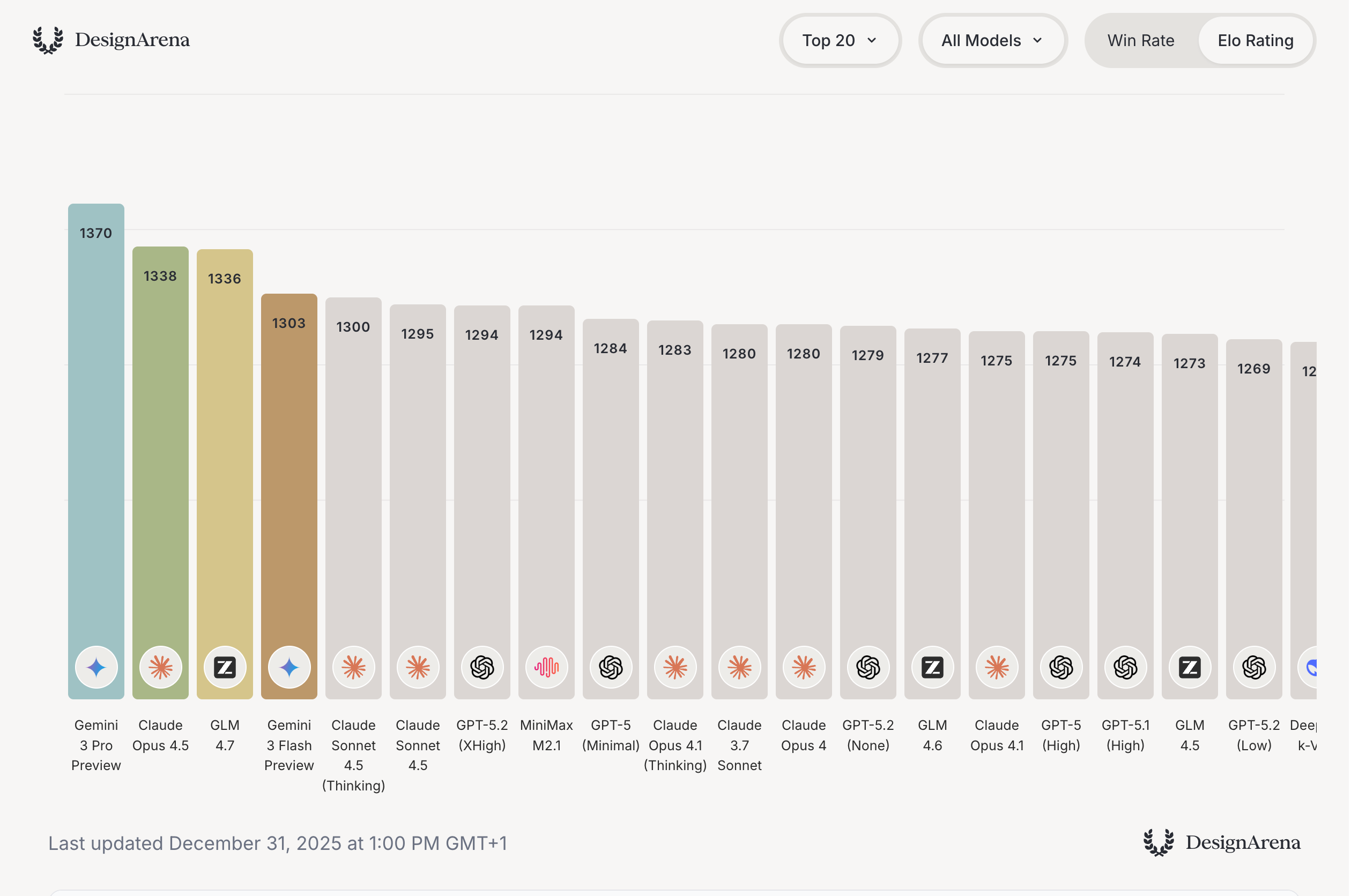
GLM-4.7 by zai-org: Zhipu, which will IPO on January 8th, dropped a really capable model just before Christmas with 4.7. GLM-4.7 is not close to (API model) SOTA performance on the usual academic benchmarks like GPQA or SWE-bench Verified, but manages to hold its performance beyond that in a broader suite of tasks like GPVal-AA or DesignArena.
I (Florian) have tested this model extensively the last days by using the Z.ai API (and the corresponding coding subscription at $28/yr) in the OpenCode as the CLI (which also offers the model for free at the time of writing) and was more than impressed by the quality of this model. In certain areas (especially in UI generation for websites), I preferred its outputs over Opus, while in other areas, it was more or less on the level of Sonnet 4.5, which was released a mere 4 months ago. However, the model is quite slow (the cheapest coding plan is slower compared to their other offerings) and its long-context performance is worse than other closed models, especially after 100K tokens. Furthermore, it is text-only, which I “fixed” by adding Gemini 3.0 Flash as a subagent in OpenCode. But again, this is an open model, dirt cheap and self-hostable on a node of H100s!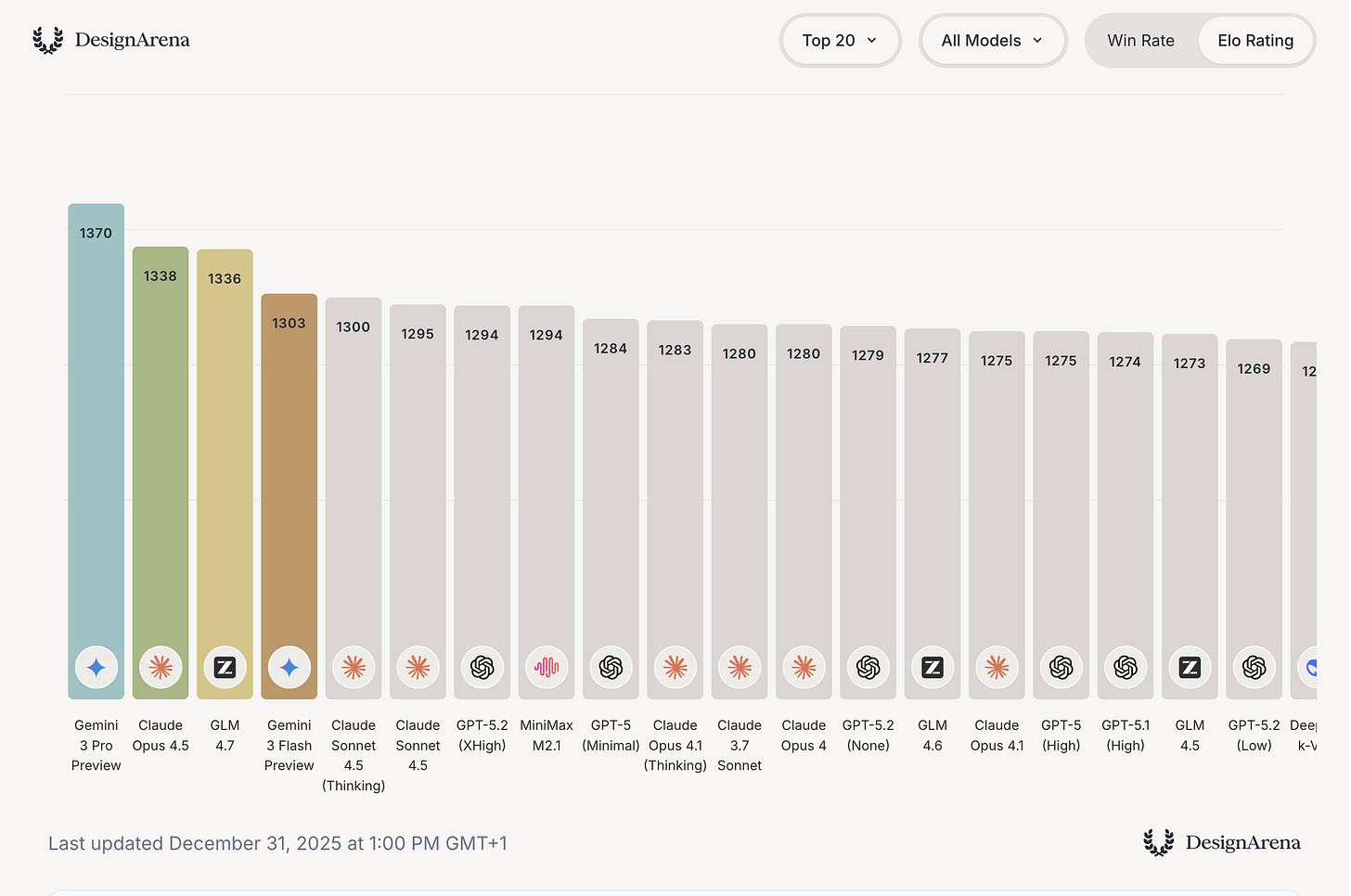
Llama-3.3-8B-Instruct by allura-forge: For some reason, Llama 3.3 8B is a thing that exists, but was never released publicly in the same way that the other models did. However, someone got access to the weights by using Meta’s Llama API and uploaded them to HuggingFace.
Models
Flagship
Apriel-1.6-15b-Thinker by ServiceNow-AI: An update to the Apriel series, focusing on using fewer tokens per answer while maintaining performance. They achieved this by using GSPO with length and verbosity penalties.
MiMo-V2-Flash by XiaomiMiMo: Xiaomi surprised everyone by dropping a 309B-A15B MoE. The first model, which we also covered, was just a 7B dense model. Members in our subscriber-only Discord used the model and liked its writing style. However, they also found that it is lacking in terms of agentic performance and function calling.
DeepSeek-V3.2 by deepseek-ai: Another update to the V3 series, which integrates DSA. They also trained and released a “high compute” version, V3.2 Speciale, which claims to beat the 2025 IMO and IOI with gold-medal performance.