

Latest open artifacts (#20): New orgs! New types of models! With Nemotron Super, Sarvam, Cohere Transcribe, & others
One of our favorite issues of the series so far.
This Artifacts Log post is unusual in how many diverse, quirky models there are across use-cases and modalities. Normally these model roundups are dominated by big models from the likes of Qwen, DeepSeek, Kimi, etc. There are models for all sorts of different use-cases in this post, from optical character recognition (OCR), RAG search, audio transcription, computer-use, code-editing, math theorem proving, and more. The artifacts covered this month also come from a much broader list of open model builders.
This gives us a lot of hope for the future of open models, where we see the need for domain-specific, cheap models as being crucial tools to complement the strongest, closed agents. When the top few models get the headlines, this vast, industry-scale tinkering can easily be forgotten. Reading this post gives a technically grounded, broad coverage of the many directions the industry is pushing specific models for. Expect more like this!
To encourage people to take a look at the diversity of models in this issue, the core part of the update is not paywalled. An otherwise quiet month at the top end of open models really delivered.
Artifacts Log
Our Picks
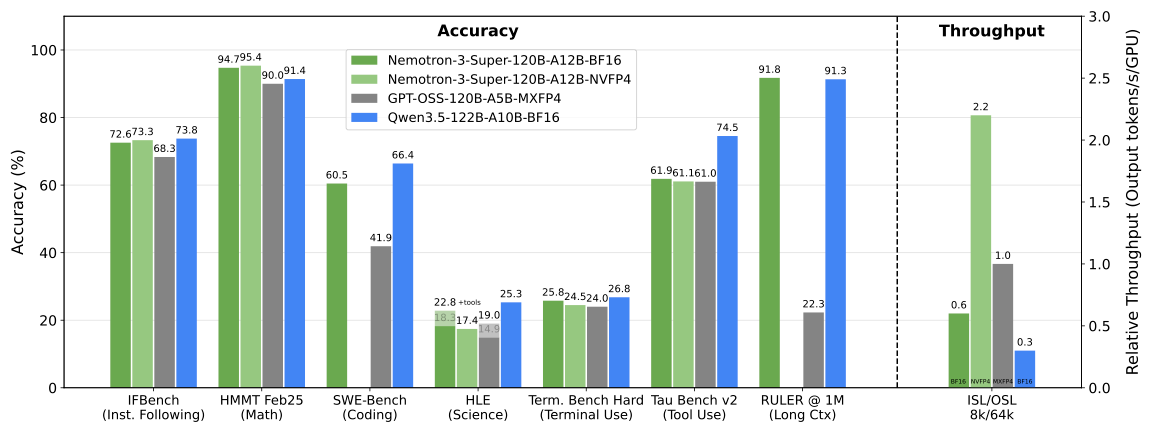
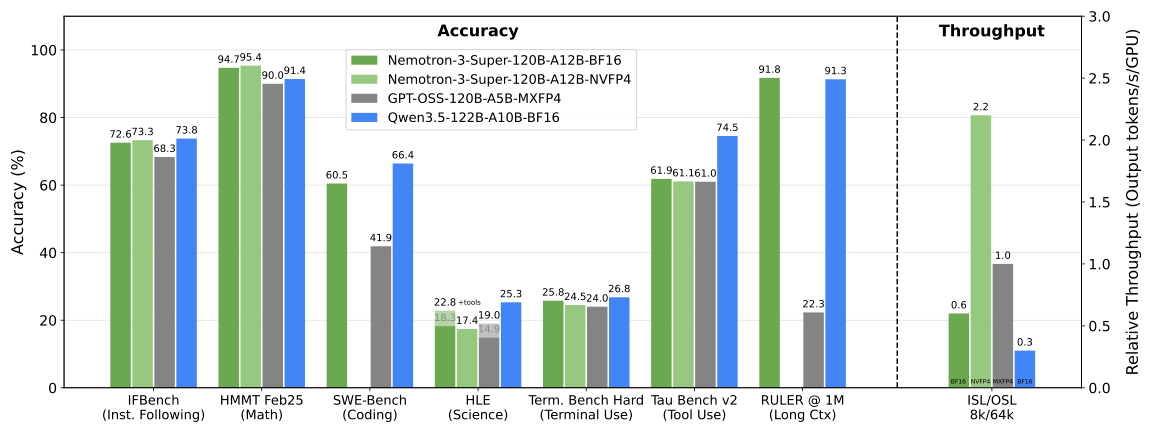
NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4 by nvidia: The long-awaited mid-sized model from NVIDIA is finally here: 120B total params with 12B active, a 1M context window, and support for multiple popular languages. Furthermore, the model is based on LatentMoE and uses NVFP4 during pre-training, which is a first for open models. Like other things from NVIDIA, it comes with an in-depth tech report plus pre-training and post-training datasets, with the vast majority of the data being openly released.
cohere-transcribe-03-2026 by CohereLabs: A speech-to-text model by Cohere based on the conformer architecture, similar to NVIDIA’s Parakeet. It features 14 different languages, including some AIPAC languages and Arabic. Performance-wise, Cohere claims it beats similarly sized open and closed models. To top it all off: The model is released under Apache 2.0! Previous open models by Cohere were released under a non-commercial license.
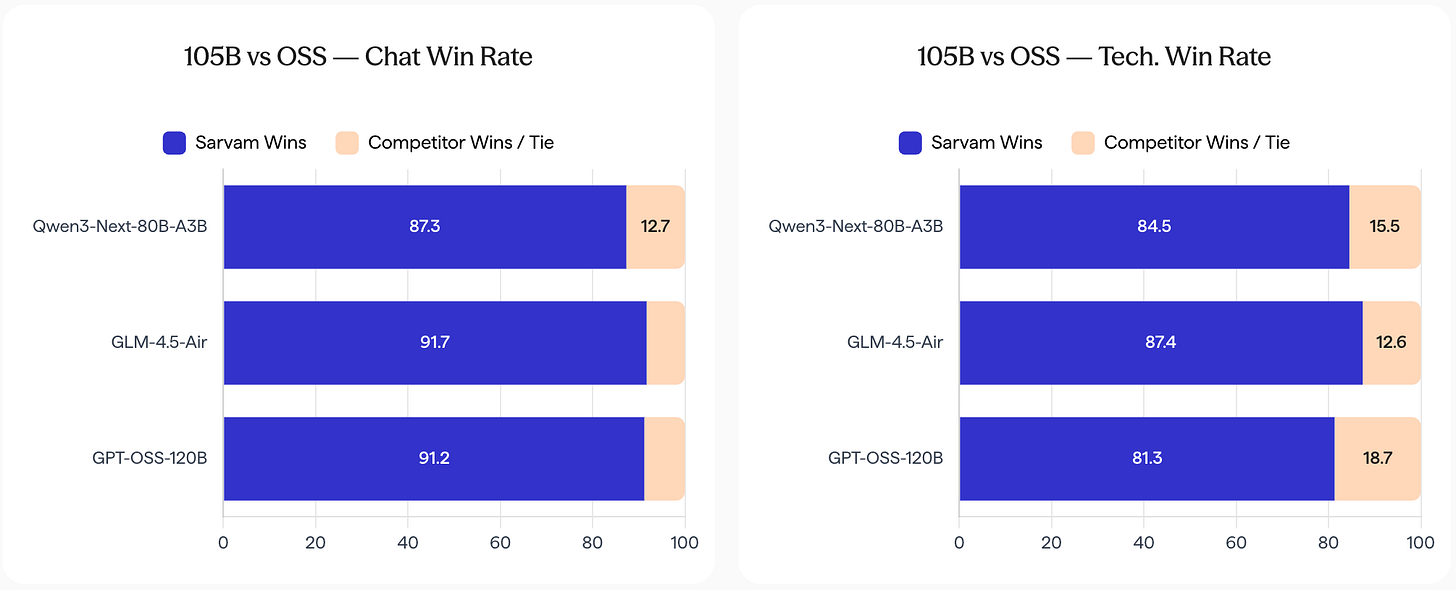
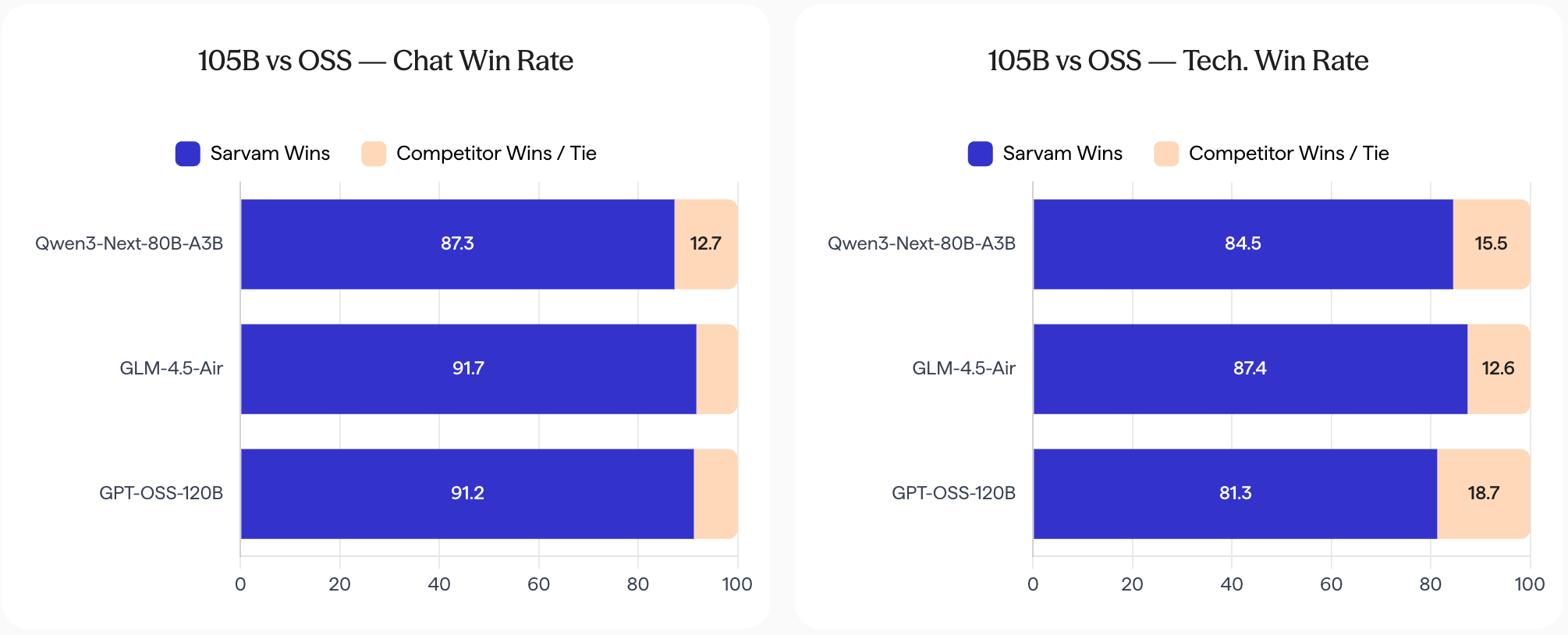
sarvam-105b by sarvamai: The Indian startup Sarvam, which trained open models in the past, has scaled up everything for its new flagship models in terms of dataset size (12-16T tokens) and model size (30B-A2B, 105B-10A). As a result, they come close to or even surpass a lot of open models with similar sizes. The release also shows why sovereign AI is so important, something that few other countries have internalized yet: In comparison with SOTA open models, the Sarvam models are vastly more preferred in Indic languages.
Mistral-Small-4-119B-2603 by mistralai: A 119B-A7B model by Mistral, combining their previous model generations into one as a hybrid reasoning model with coding abilities.
zeta-2 by zed-industries: The open source code editor Zed has released their edit prediction model openly in the past, which we featured a year ago. While the previous version was based on open data, the new version, based on Seed-Coder-8B, is trained on open source code by users who explicitly opted into data collection.
Models
General Purpose
gpt-oss-puzzle-88B by nvidia: A pruned expert version of GPT OSS 120B. It also replaces some global attention layers with window attention. Puzzle is “a post-training neural architecture search (NAS) framework, with the goal of significantly improving inference efficiency for reasoning-heavy workloads while maintaining or improving accuracy across reasoning budgets.”
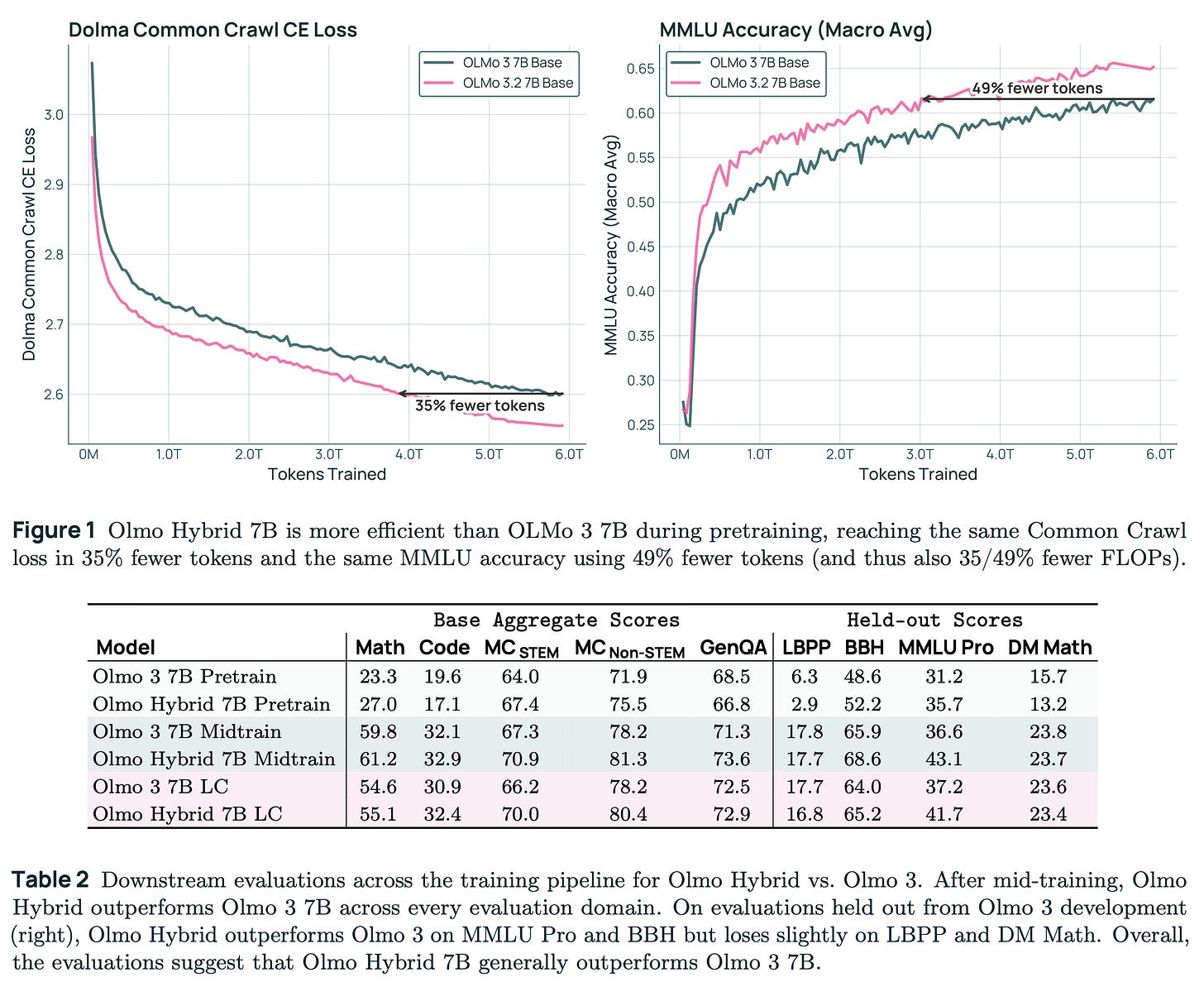
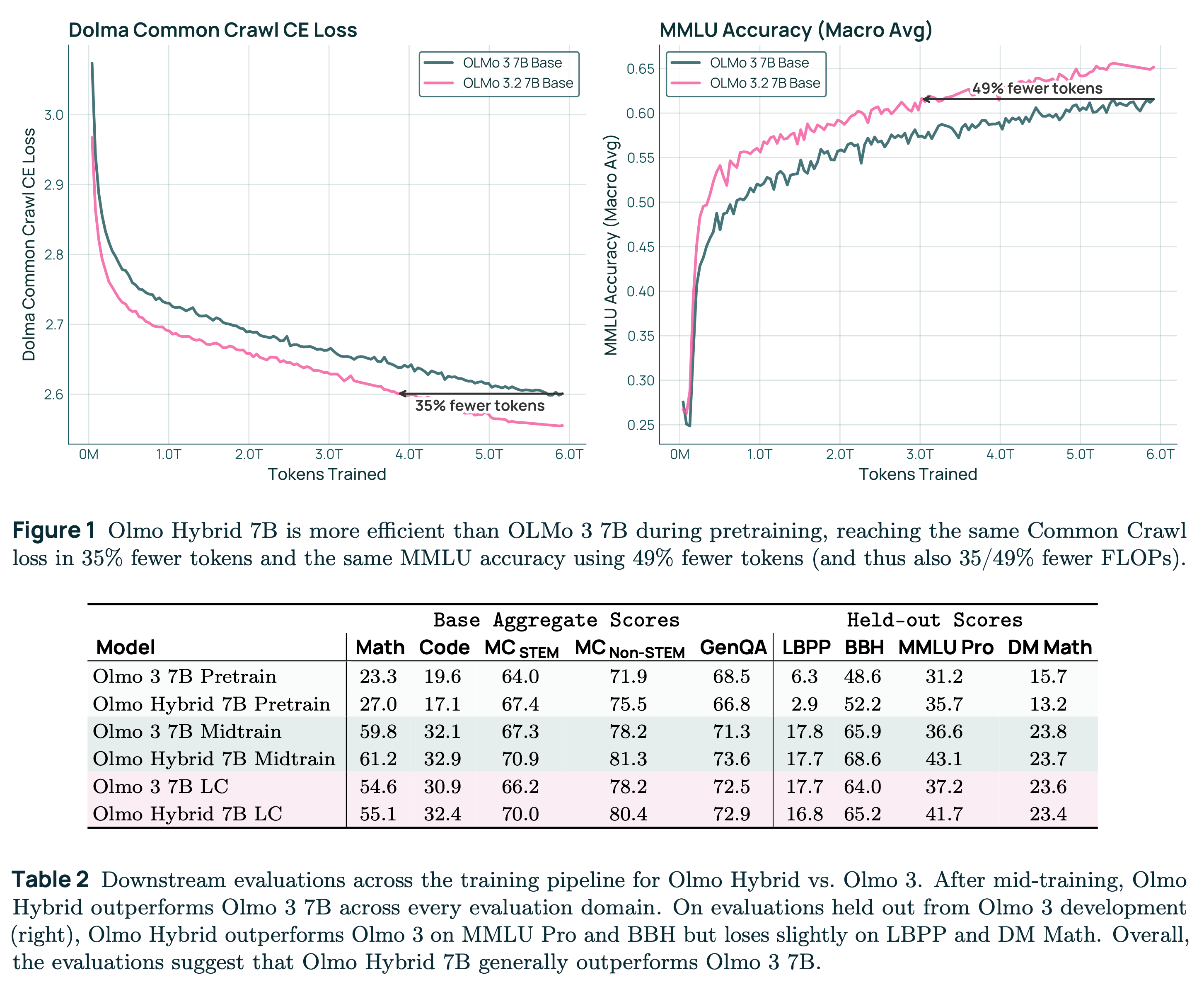
Olmo-Hybrid-7B by allenai: A hybrid attention + GDN (gated DeltaNet) model. See our blog post for more insights about the architecture and its challenges.
NVIDIA-Nemotron-3-Nano-4B-BF16 by nvidia: A compressed version of NVIDIA-Nemotron-Nano-9B-v2, which itself is a compressed version of NVIDIA-Nemotron-Nano-12B-v2. Nvidia has been pushing this direction more than anyone else with open models.
Multimodal
Yuan3.0-Ultra by YuanLabAI: A 1T multimodal model by the relatively unknown Yuan Lab. They pre-trained a 1.5T model on 2.2T tokens and subsequently pruned experts with a new technique, outlined in the tech report.
LongCat-Next by meituan-longcat: A multimodal model which can process text, vision, and audio as both inputs and outputs.

granite-4.0-1b-speech by ibm-granite: A small speech-to-text model supporting six languages. It also supports the generation of English audio for translation.
Phi-4-reasoning-vision-15B by microsoft: A Phi model which uses the SigLIP-2 vision encoder.

Special Purpose
MiroThinker-1.7 by miromind-ai: A fine-tuned version of Qwen 235B for agentic workflows, especially research.

tabpfn_2_6 by Prior-Labs: An update to the popular tabular prediction model, which is slightly larger than its predecessor. Its license allows research and internal evaluation only.
sam3.1 by facebook: An update to SAM 3, carrying the same restrictive license.
Holotron-12B by Hcompany: A policy model for CUA agents.
LongCat-Flash-Prover by meituan-longcat: A Lean4 fine-tune of the large LongCat model.
Leanstral-2603 by mistralai: A Lean4 fine-tune of the new Mistral Small 4.
reka-edge-2603 by RekaAI: A model for robotics, beating models such as Cosmos-Reason2. Its noncommercial license converts into Apache 2.0 after two years.

RAG
Qianfan-OCR by baidu: There have been a lot of great OCR models lately. This one is from Baidu and is licensed under Apache 2.0.
chandra-ocr-2 by datalab-to: An update to the Chandra OCR model, released under a restrictive license.
Reason-ModernColBERT by lightonai: A SOTA retrieval model released under a non-commercial license. However, there is also code to re-generate the data, allowing the training of a commercially viable version.
context-1 by chromadb: A fine-tuned version of GPT-OSS for agentic search with an in-depth tech report. It also marks the debut of Chroma into the open model space. Trained with Thinking Machine’s Tinker.

dots.mocr by rednote-hilab: The beloved dots.ocr model has been updated and supports SVG outputs. However, on top of the general MIT license, the model comes with additional usage restrictions, just like its predecessor.
