

Latest open artifacts (#15): It’s Qwen's world and we get to live in it, on CAISI's report, & GPT-OSS update
After a quiet month, Qwen is back in full force.
Before getting into the latest artifacts, there are a couple of pieces of crucial open ecosystem we have to cover.
First, the Center for AI Standards and Innovation (CAISI) released a report that observed the ecosystem and evaluated DeepSeek 3.1 against leading closed models. The evaluation scores they highlighted show some discrepancy with accepted results in the community. While MMLU-Pro, GPQA and HLE are close to the self-reported scores from DeepSeek and within usual error bars1, the SWE-bench Verified scores are off by a wide margin due to a weak harness for the benchmark. The harness is the software framework the model is used in for agentic benchmarks and has as great an impact as the model itself, as shown in this SWE-bench analysis by Epoch AI.
The CAISI report thus undersells the capabilities of DeepSeek’s models on a core benchmark for recent models (e.g. it is one of the benchmarks that Anthropic most heavily relies on for marketing of Claude).

Later in the report, CAISI shows a graph with cumulative download numbers from HuggingFace (left), something we also show on atomproject.ai (middle, right). However, our numbers differ greatly from the numbers from CAISI and those differ even more from the ones by HuggingFace itself. So, what is going on?
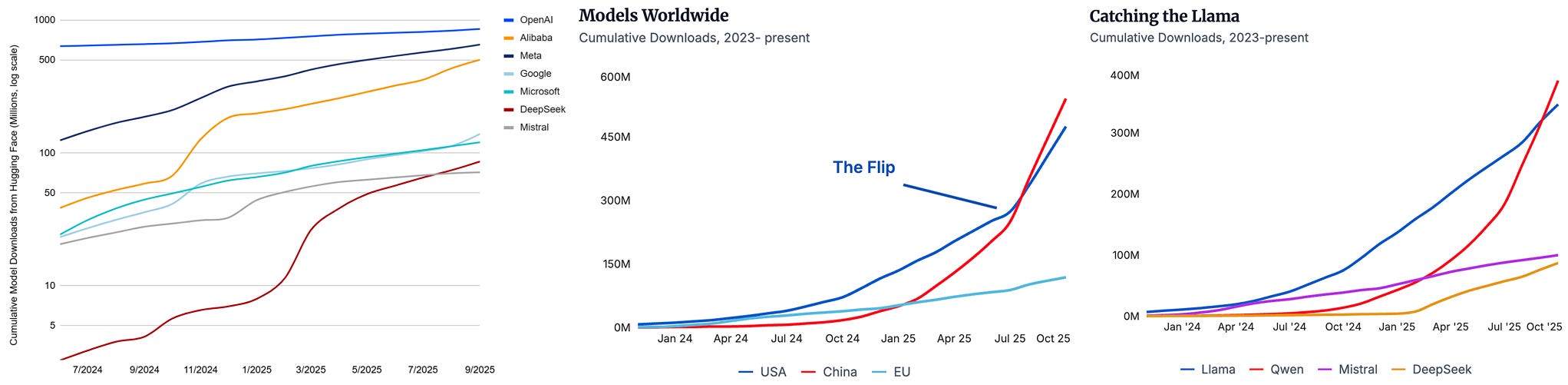
In short, it depends on which data you look at and how you clean it. For ATOM Project, we only consider models which were released after ChatGPT and are LLMs (based on our assessment). This excludes models like GPT-2 (which is the reason why OpenAI trumps all in the CAISI number, left), BERT-like models and ViTs like SigLIP (which are dominating the Google download numbers).
On top of this, we performed basic outlier filtering on daily downloads per model. Many models, such as Qwen 2.5 1.5B, which is one of the most downloaded models of all time, has extreme outliers on the order of 10M+ downloads that can heavily skew the overall numbers. These outliers affect every organization, but in different magnitudes. Furthermore, we also exclude quantized (like FP8, MLX or GGUF) versions, as those might skew the numbers.
The second news item is sharing an update on the utility of GPT-OSS — when the model first dropped it was plagued by implementation difficulties downstream of architecture choices (e.g. a new 4-point precision) and complex tool use (multiple tool options per category). OpenAI is actually ahead of the curve on the complexity of tools they support with these models among open options. Since release, the use of GPT-OSS’s 20B and 120B models is very strong with 5.6M and 3.2M downloads in the last month, respectively. These models are outperforming some popular models, such as Qwen 3 4B or Qwen3-VL-30B-A3B-Instruct. Additionally, I got very strong feedback from the community when I did a basic pulse check on the models. These are one of the first models I’d try on my new Nvidia DGX-Spark to get a feel for things.
Artifacts Log
Our Picks
granite-4.0-h-small by ibm-granite: We’ve been covering IBM and their Granite LLM series for a while. With this series, IBM finally scaled up the model size as well, bringing a series of hybrid (attention + mamba) models, ranging from a 3B dense to a 32B-A9B MoE. We used the models and were impressed, although not surprised, by the quality, given the continued persistence of IBM’s team to release better and better models.
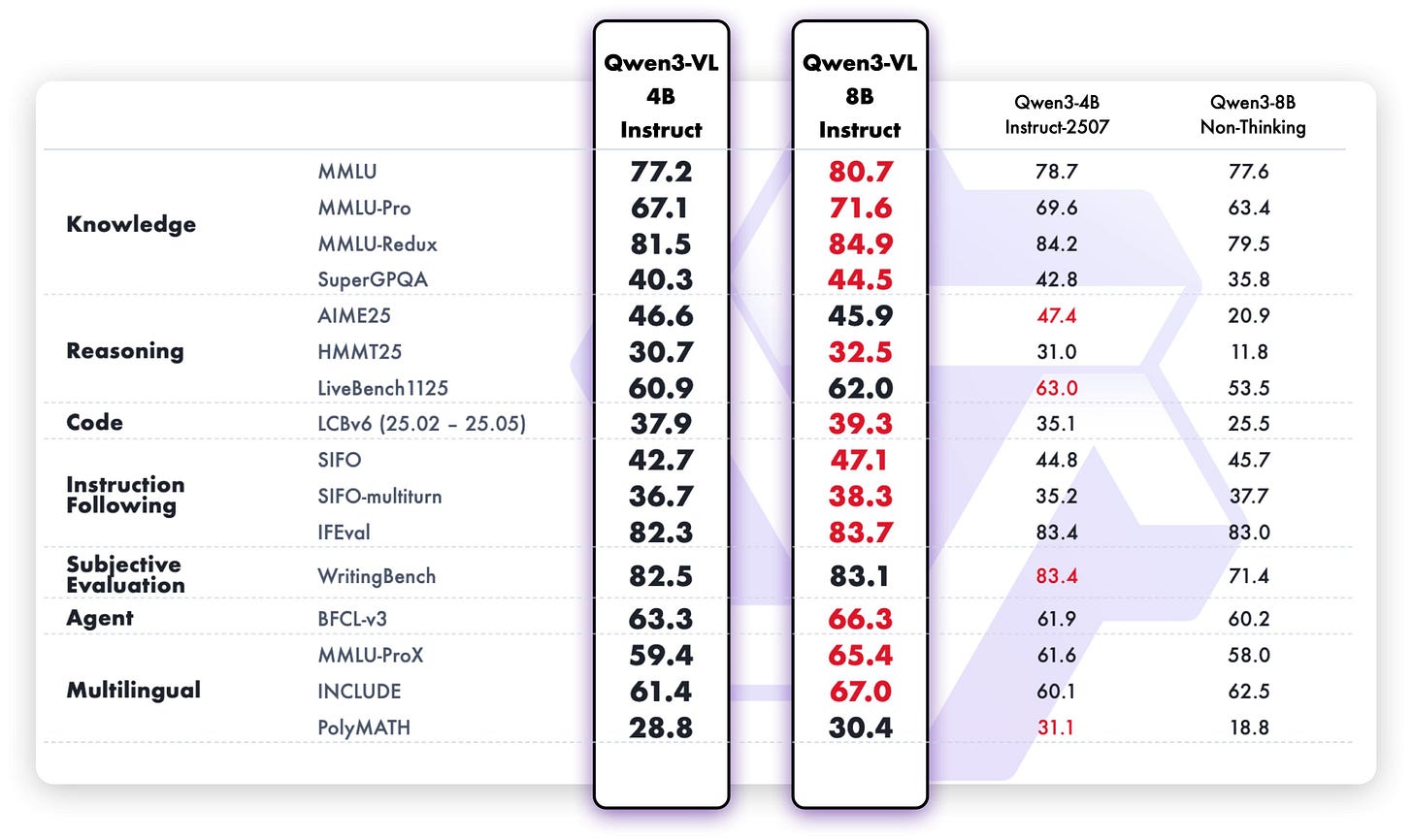
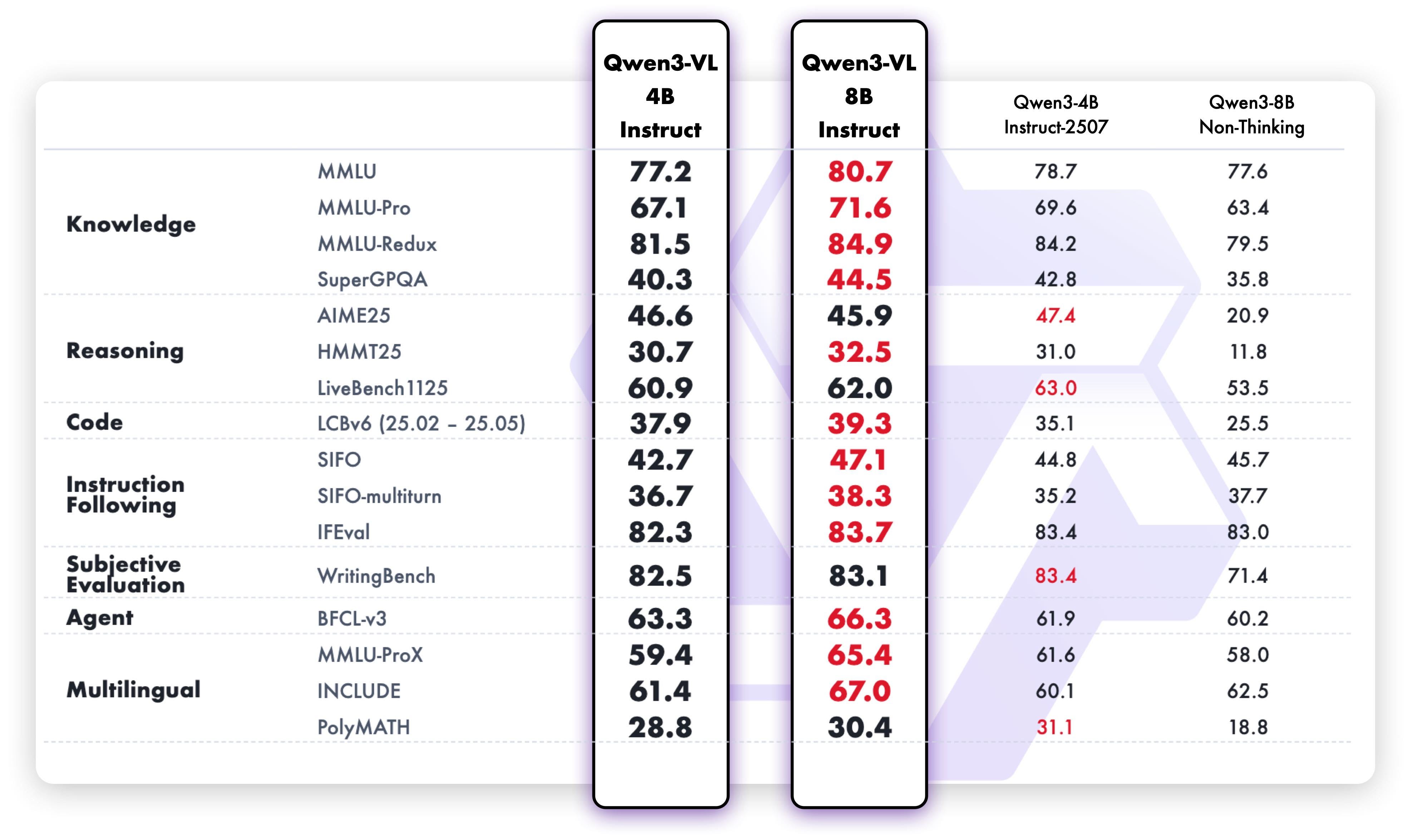
Granite, for at least the 3B variant, is roughly in the SmolLM3 quality range, being only surpassed by Qwen3 4B in terms of multilingual and instruction following capabilities. The tone of Granite 4.0 is refreshingly non-exciting compared to the sloptimized models recently (i.e. the trend across the industry for playful, emoji-filled, and often sycophantic models), making it feel like old Mistral models in a good way. Interestingly enough, they are also following Qwens lead and will release a separate reasoning model later in the year. We’ve heard many reports from people training models that hybrid reasoning — i.e. a toggle of thinking tokens on and off — adds a major complexity cost in training that lowers the peak performance of both modes. IBM debuted the hybrid thinking approach (togglable via prompts) very early on for open models, which was adopted by others later.Qwen3-VL-235B-A22B-Instruct by Qwen: The Qwen VL series finally gets its long-awaited and anticipated update with small (4B, 8B) dense and larger (30B-A3B, 235B-A22B) MoEs in both instruct and reasoning versions. We want to shine a special spotlight on the 8B variants: Their text benchmarks have also improved across the board compared to the initial 8B release — reinforcing our point on the challenge of hybrid reasoning. As the 8B versions did not get a 2507 refresh, these versions should be a no-brainer update and drop-in replacement if you were using Qwen3 8B (or are still using Llama3.1 8B).
GLM-4.6 by zai-org: Zhipu has released an update to their main series of models. This release is notable because many people say that it’s basically a Sonnet (or a Haiku) 4.5 at home, although it falls off (harder) at longer context than closed models. Still, a high praise and a continuation of the theme that Chinese open models improve at an astonishing rate, being close to the best closed models.
Ling-1T by inclusionAI: Inclusion AI is waking up and starting to adopt the release cadence of its bigger brother by releasing models left, right and center. Similar to Qwen, they also started to scale up model sizes considerably, hitting the 1T threshold. They also release a reasoning version and experiment with different architectures and modalities. Keep an eye on them!
moondream3-preview by moondream: Moondream is far from an unknown player these days and known for punching well above its size. They too adopted the MoE architecture with 9B total, 2B active parameters and improved the already great benchmarks even further. An interesting aspect is its unique (in the AI world) license:
TL;DR — You can use Moondream 3 (Preview) freely for personal, research, and most commercial uses. What’s NOT allowed without a separate deal is offering a paid product that competes with M87 Labs’ paid versions (e.g., selling hosted or embedded access to the model’s capabilities to third parties).


In the rest of the issue we highlight the long-tail of models, which again highlights the sweeping approach we’ve seen throughout the year from Qwen, but with continuing support from other rising Chinese labs. One of the sad things in this issue is that there are actually 0 datasets that cleared our bar of relevance. Open data continues to be in a very precarious position.
Models
Flagship
Qwen3-Next-80B-A3B-Instruct by Qwen: Of course, Qwen is also exploring different architectures, releasing a LLM with hybrid attention, consisting of Gated DeltaNet and Gated Attention. This model is trained on over 15T tokens and could be the groundwork for the next generation of Qwen models. Junyang Lin writes in a tweet about this series:
Qwen3-Next, or to say, a preview of our next generation (3.5?) is out!
This time we try to be bold, but actually we have been doing experiments on hybrid models and linear attention for about a year. We believe that our solution should be at least a stable and solid solution to new model architecture for super long context!
Magistral-Small-2509 by mistralai: An update to the reasoning model by Mistral.
LongCat-Flash-Thinking by meituan-longcat: Yes, the Chinese Doordash continues to release models. This time, they drop the reasoning version of their MoE, coming with an interesting tech report.