

Lossy self-improvement
Why self-improvement is real but it doesn't lead to fast takeoff.
Fast takeoff, the singularity, and recursive self-improvement (RSI) are all top of mind in AI circles these days. There are elements of truth to them in what’s happening in the AI industry. Two, maybe three, labs are consolidating as an oligopoly with access to the best AI models (and the resources to build the next ones). The AI tools of today are abruptly transforming engineering and research jobs.
AI research is becoming much easier in many ways. The technical problems that need to be solved to scale training large language models even further are formidable. Super-human coding assistants making these approachable is breaking a lot of former claims of what building these things entailed. Together this is setting us up for a year (or more) of rapid progress at the cutting edge of AI.
We’re also at a time where language models are already extremely good. They’re in fact good enough for plenty of extremely valuable knowledge-work tasks. Language models taking another big step is hard to imagine — it’s unclear which tasks they’re going to master this year outside of code and CLI-based computer-use. There will be some new ones! These capabilities unlock new styles of working that’ll send more ripples through the economy.
These dramatic changes almost make it seem like a foregone conclusion that language models can then just keep accelerating progress on their own. The popular language for this is a recursive self-improvement loop. Early writing on the topic dates back to the 2000s, such as the blog post entirely on the topic from 2008:
Recursion is the sort of thing that happens when you hand the AI the object-level problem of “redesign your own cognitive algorithms”.
And slightly earlier, in 2007, Yudkowsky also defined the related idea of a Seed AI in Levels of Organization in General Intelligence:
A seed AI is an AI designed for self-understanding, self-modification, and recursive self-improvement. This has implications both for the functional architectures needed to achieve primitive intelligence, and for the later development of the AI if and when its holonic self-understanding begins to improve. Seed AI is not a workaround that avoids the challenge of general intelligence by bootstrapping from an unintelligent core; seed AI only begins to yield benefits once there is some degree of available intelligence to be utilized. The later consequences of seed AI (such as true recursive self-improvement) only show up after the AI has achieved significant holonic understanding and general intelligence.
It’s reasonable to think we’re at the start here, with how general and useful today’s models are.
Generally, RSI can be summarized as when AI can improve itself, the improved version can improve even more efficiently, creating a closed amplification loop that leads to an intelligence explosion, often referred to as the singularity. There are a few assumptions in this. For RSI to occur, it needs to be that:
The loop is closed. Models can keep improving on themselves and beget more models.
The loop is self-amplifying. The next models will yield even bigger improvements than the current ones.
The loop continues to run without losing efficiency. There are not added pieces of friction that make the exponential knee-capped as an early sigmoid.
While I agree that momentous, socially destabilizing changes are coming in the next few years from sustained AI improvements, I expect the trend line of progress to be more linear than exponential when we reflect back. Instead of recursive self-improvement, it will be lossy self-improvement (LSI) – the models become core to the development loop but friction breaks down all the core assumptions of RSI. The more compute and agents you throw at a problem, the more loss and repetition shows up.
I’m still a believer that the complexity brake on advanced systems will be a strong counterbalance to the reality that AI models are getting substantially better at every narrow task we need to compose together in making a leading AI model. I quoted this previously in April of 2025 in response to AI 2027.
Microsoft co-founder Paul Allen argued the opposite of accelerating returns, the complexity brake: the more progress science makes towards understanding intelligence, the more difficult it becomes to make additional progress. A study of the number of patents shows that human creativity does not show accelerating returns, but in fact, as suggested by Joseph Tainter in his The Collapse of Complex Societies, a law of diminishing returns. The number of patents per thousand peaked in the period from 1850 to 1900, and has been declining since. The growth of complexity eventually becomes self-limiting, and leads to a widespread “general systems collapse”.
There are plenty of examples in how models are already trained, the deep intuitions we need to get them right, and the organizations that build them that show where the losses will come from. Building leading language models is incredibly complex, and only becoming more-so. There are a few core frictions in my mind.
1. Automatable research is too narrow
First, it is clear that language models this year will already be useful tools at optimizing localized tasks like lowering the test loss of a model. Andrey Karpathy recently launched his autoresearch that popularized doing just this. This allows AI agents to play directly on GPUs to target tasks like lowering the loss on the test set. This approach works in narrow domains, i.e. one general test loss or one overall reward. The problem is that there’s a long-standing gap between an on-paper more accurate model and models that users find more productive. The most provocative case is for pretraining, which was discussed more at length around scaling laws. Scaling laws show us that the loss will continue going down, but we don’t know if that’ll be economically more valuable.
In post-training, reinforcement learning algorithms are at least more directly tied to specific performance gains as most RL training environments can be used directly as an evaluation. Still, I worry about generalization and tying back to models that are better at the specific task of improving themselves. It’s a big leap from models get better at some things to that necessarily translating to models that are better at building themselves and designing experiments. We’ve seen many AI capabilities sort of saturate at certain levels of human taste, such as writing quality. AI research is a bit different here, as there is a very high ceiling to climb up to. Where models mostly saturate on writing because there’s inherent tension in preferences, models will saturate on research because the search space and optimization target is too wide.
The early benchmarks for measuring this sort of ability all fall prey to the same problem – narrow scope. Agents will do well at optimizing single metrics, but the leap required to navigate many metrics at once is a very different skill set. That is actually what the best researchers do — they make many scalable ideas work together.
The most related benchmark we have to measure this is PostTrainBench, which is quite fun, but progress will very rapidly get distorted on this. Over 90% of the challenge in doing post-training well is getting the last 1-3% of performance, especially without cooking the model in out-of-domain tasks. Post-training a general, leading model is extremely complex, and only getting more complex.
I could go on and on about this. Another example is from during my Ph.D. (2017-2022), when there was immense hype around a field called “AutoML” which aimed to use techniques like Bayesian Optimization to find new architectures and parameters for models. The hype never translated into changing my job. Language models will do more than this, but not enough to take jobs away from top AI researchers any time soon. The core currency of researchers is still intuition and managing complexity, rather than specific optimization and implementation.
2. Diminishing returns of more AI agents in parallel
The biggest problem for rapid improvement in AI is that even though we’ll have 10,000 remote workers in a datacenter, it’ll be nearly impossible to channel all of them at one problem. Inherently, especially when the models are still so similar, they’re sampling from the same distribution of solutions and capabilities while being bottlenecked by human supervision. Adding more agents will have a strict saturation in the amount of marginal performance that can be added – the intuition of the best few researchers (and time to run experiments) will be the final bottleneck.
A common idea to illustrate this is Amdahl’s law, which is taken from computer architecture and shows that a given task can only generate a fixed speedup proportional to how much can be parallelized and how many parallel workers exist. An illustration is below:
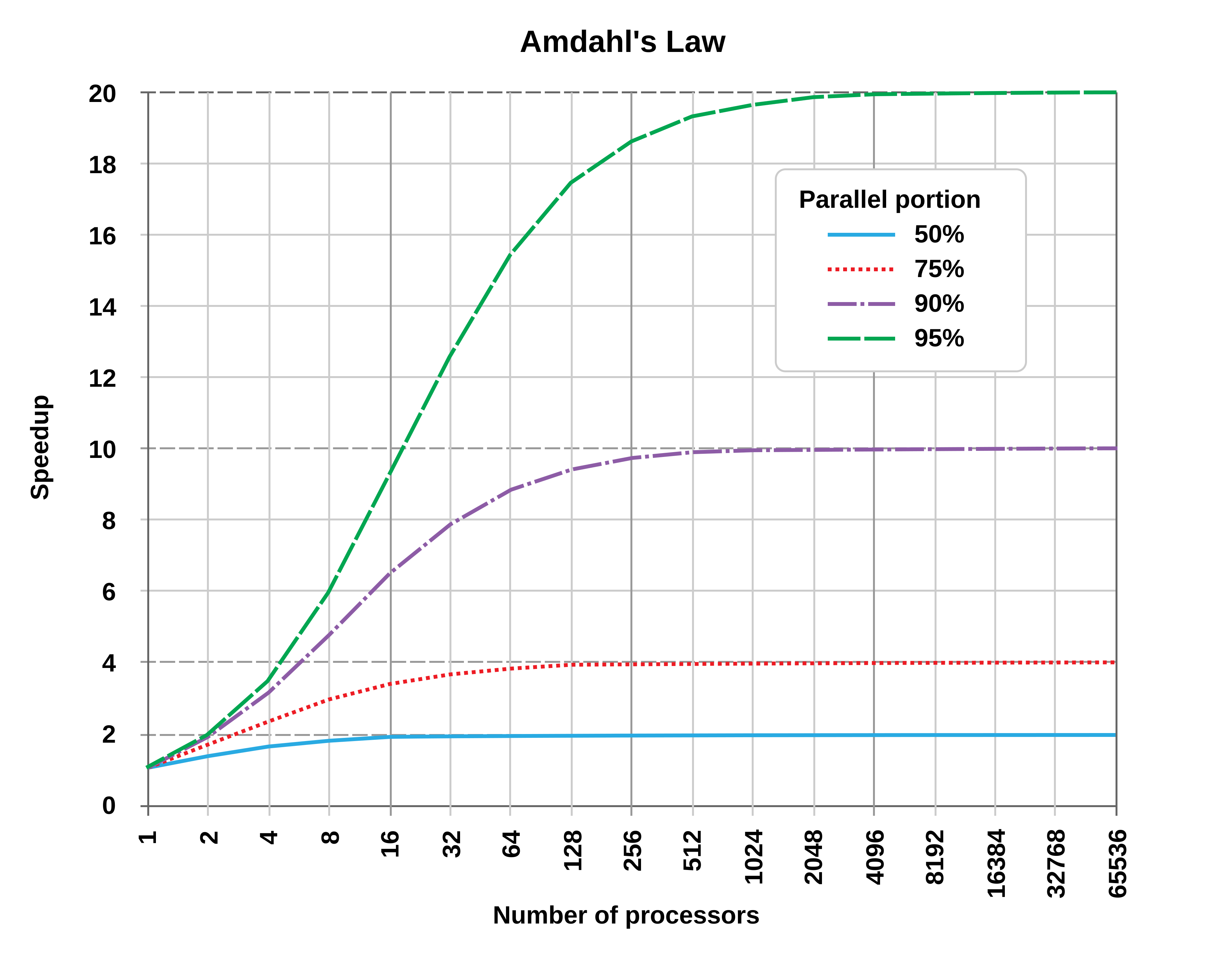
In AI this should be relatively easier to convey, as the low-level operating details of computers are fairly mysterious. Consider an AI researcher on the transition from writing code by hand to using AI autocomplete assistance to now using autonomous coding agents. These are all massive gains. Let us continue. Now this researcher uses 3-4 agents working on different sub-tasks or approaches to the problem at hand. This is still a large gain. Now consider this single researcher trying to organize 30-40 agents with tasks to do every day. Some people can get more value out of this scale, but not many.
How many people do you think could come up with 300-400 tasks for AI agents every day? Not many. This problem will hit the AI models soon enough as well.
3. Resource bottlenecks and politics
Fundamentally, all the AI companies are walking a fine line of acquiring substantial capital, converting new compute resources to revenue via sufficient demand, and repeating the process all-the-while spending an extreme amount on research. With the scale of resources here, there will always be political bottlenecks on who gets resources and what gets bet on. In this layer, research leadership sits above the AIs and the researchers. Even as models continue to improve, this source of friction will never get removed. It isn’t a substantial friction, but the AI models are fundamentally operating in organizations where humans are the bottleneck on resources.
The early scale of improvements with language models is local optimizations, where the resources used cost <$1M per day. With my other views on the frictions of AI, this is on its own a very minor impact on the rate of improvement, but for those with worries of fast take-off, RSI, and loss of control to AIs, it should be obvious that billions of dollars of compute resources for research are unlikely to be totally isolated for end-to-end experimentation of AI models.
The conclusion here is that because we’re at the early stages of using AI assistance, autonomously and at scale for AI-development, we’re collectively discovering the ways that AI can help us massively. We’re all applying these tools to capture the low-hanging fruit we see and our jobs are literally changing to be higher paced and more productive. The problem is that all of these axes have clear human, political, or technical complexity bottlenecks.
The bottom of every sigmoid feels like an exponential. We’ve ridden multiple exponentials in the era of language models, in 2023 we scaled to huge models and GPT-4 felt like magic, by 2025 we added inference-time scaling with o1 and reasoning models — they let us “solve” math and coding, now we’re going to take a big step by polishing the entire AI workflow (all the while scaling training compute massively). 2026 will feel like a huge step, but it doesn’t have a fundamental change convincing me that progress will begin to take off.
This could still cross the colloquial threshold for AGI, which is a drop-in replacement for most remote workers, which would be an incredible milestone. Much of the challenge in the debate of if we hit AGI in the coming years is that AI models are jagged and smart in different ways than humans, so they won’t look like drop-in replacements for remote workers, but in many cases just using AI will be far more effective than trying to work with a human. It’s reshaping what jobs are.
Let us consider the scenarios we’re working through.
Engineering is becoming automated today. Humans are way more productive, models can scale through complex infrastructure deployments much faster, run with higher GPU utilization, etc. Infrastructure gains become fixed improvements in the rate and scale of experimentation, the fundamental units of progress in AI.
Basic AI model research and optimization will be automated. The AI models are expanding in scope – they transition from writing kernels to deciding on architectures. This is moving from improving the experimentation toolkit to running minor experiments themselves. Configs, hyperparameters, etc. become the domain of the AI assistants.
These are both real. The problem is that a third era doesn’t have a simple scale to jump to. Where the AI models can create knowledge by synthesis and execution, the next jump requires harnessing thousands of agents or having models make more novel discoveries – like unlocking the next paradigm after inference time scaling. The improvements downstream of AI are going to make the industry supercharged at hill climbing, but I worry that this won’t bring paradigm shifts that are needed for new categories of AI – continual learning, world models, whatever your drug of choice is.
All together, the models are becoming core to the development loop and that’s worth being excited (and worried) about. The models are performing self-improvement. They’re not transforming the approach. We are scaling up the compute we spend on our own research practices and tools. There are diminishing returns. Agents are going to start being autonomous entities we work with. They feel like a cross between a genius and a 5 year old. We will be in this era of lossy self-improvement (LSI) for a few years, but it is not enough for a fast takeoff.
There are some papers showing that when models are trained on AI slop, which people are now producing and posting everyday, they have some weird version of Mad Cow disease and die. I feel like that's lossy self-improvement more than anything. Also, not a huge fan of the word lossy here because it has such a history in information theory that has nothing to do with the post.
The new models will be much better at creating useful, minimal "synthetic data" this data flywheel of improvement negates the complexity arguments. The type of data for that is simply mathematical tools, structures, and objects. There is a near infinite amount of useful data that can be created. In 2027, the best mathematician will be an AI. Curry-Howard correspondence means coding is immediately next, then likely physics. As usual, it's the data...not the models.