

Multimodal LM roundup: Unified IO 2, inputs and outputs, Gemini, LLaVA-RLHF, and RLHF questions
A sampling of recent happenings in the multimodal space. Be sure to expect more this year.
Everyone knows that multimodal models are going to be a big theme for the year, but I have yet to read a compelling argument as to why. To me, it’s based on grand goals for what AI should be able to do and complement the core functions of our information processing capabilities. What multi-modal inputs to models do is take us one step closer to letting large language models (LLMs) see what we see. Text was the primary form of visual information for a few centuries, but with TikTok and YouTube, our society is increasingly visual. There was a small phase where audio-only seemed like the next modality, but it remains niche relative to video, and text can normally be used instead of audio. To this end, image inputs can unlock a way richer set of training data and applications.
On the other side of things is what multi-modal outputs allow. The most impressive thing about the Gemini announcement to me is that it can natively generate images. Outputs are about creative acts, which are certainly complimentary to information processing but can be understood in their own way. With this separation of generation and information processing, the various parts of building multimodal models can mirror the encoder-decoder architecture of earlier LLMs (those used today are almost entirely decoder-only). This multimodal worldview is definitely a work in progress, so let me know if there’s a resource you like on the topic.
The notation for multimodal large language models (MLLMs) is also a work in progress. Some people refer to them as that, MLLM, but also the terminology visual language model (VLM) is used widely. It’s easy to see that visual is a subset of multimodal, but we need much clearer terminology when we want to differentiate between models like OpenAI’s GPT4-V and Google’s Gemini. OpenAI’s models only read image inputs while Google’s also outputs images. That is likely a huge difference in architecture and training methods.
This post roughly follows the normal training pipeline, starting with a paper about pretraining, moving through data collection, and finishing with LLaVA-RLHF and open questions.

Unified IO 2: Scaling multi-input, multi-output model pretraining
This recent paper and model release from the Allen Institute on Unified IO 2 caught my eye because it was the most relevant work to Gemini in training a model for multi-output operation. Unified IO 2 is, in short:
the first autoregressive multimodal model that is capable of understanding and generating images, text, audio, and action. To unify different modalities, we tokenize inputs and outputs -- images, text, audio, action, boxes, etc., into a shared semantic space and then process them with a single encoder-decoder transformer model.
A summary of the architecture is shown below. The core of multimodal models is figuring out how to share the tokenization space across a variety of signals (both for inference and training).

You can compare this system diagram to another popular multimodal language model, Flamingo, from DeepMind.
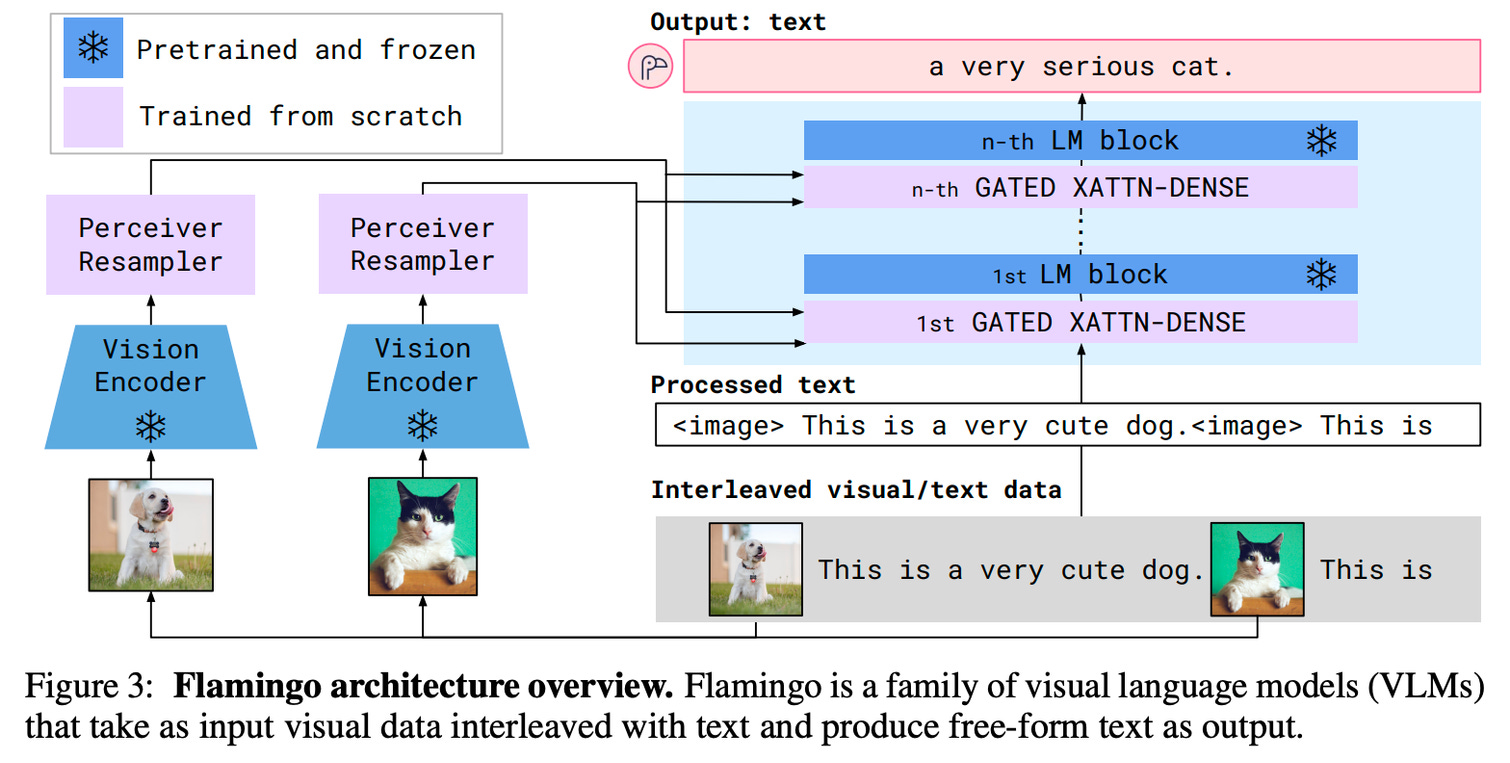
When you compare these to Gemini, a keyword is missing from Unified IO compared to Gemini, which is “interleaved.” Google says that Gemini “can output responses with interleaved images and text.” I want to know how stable these behaviors are, and how much work it takes to get the model to do both nicely. At a minimum, it seems like a substantial change in how pretraining data is structured. Normally, pretraining data processing will strip all images from sources, but for Gemini, they may need to leave them in line. Additionally, we don’t know if adding this output ability improved the language-alone capabilities, or if Google trapped themselves on a specific development pathway and got stuck with it. We’ll learn more soon.

My primary questions for the authors and paper fell into two categories. First, I wanted to know what problems emerge when you add more modalities in pretraining. Second, I wanted to know if they tried any instruction tuning or RLHF.
The pretraining architecture is built on UL2 from Google. The authors shared some of the substantial efforts it took to get off the ground in the paper (and in a talk I got to watch internal to AI2). As a summary, they stated that:
Model is not stable when use pure NLP LLM training receipts.
QK-Normalization – apply layer norm before QK attention.
Scaled Cosine Attention in Perceiver – avoid unbound value happens there.
More likely to have Numerical Issue – F32 attention logit instead of BF16.
Adafactor is better than AdamW in our optimization setting.
Carefully curated mixture ratio that consider the modality distribution, data quality and size.
2D Rotary Encoding ...
Auto-regressive with dynamic masking ...
In the interest of brevity, I’m continuing, but you know to look at the paper for more. They also shared the tooling they needed to do this:
Dynamic Packing – Efficient packing mechanism that can reduce the padding of unused modality tokens – leads to 4x improvements throughputs.
SeqIO – Super efficient data pipeline that easily mix arbitrary multi-modal dataset.
T5X – Model paralleled implementation that can scale up the model.
Ultimately, they tried using the T5 model as a starting point (because that was a codebase that worked for v1 of the model), but that didn’t work out of the box. They needed to do a lot of sampling around how much data was used for each subdomain. There’s currently vastly more text data available than domains like keypoint estimation. This sampling problem is important to getting a stable loss. The language corpus they used before any subtle sampling changes was designed to match that of the MPT model.
The authors did use a sampling of text and multimodal instruction tuning datasets, which gives the usual bump. I’ll discuss more on multimodal fine-tuning in the section on LLaVA-RLHF later.

Evaluating models like this takes a large effort. In short, the text-image capabilities are pretty comparable to LLaVA models. On language-only tasks, this model is closer to the 3 billion parameter text models. More information for Unified IO 2 can be found on Twitter, and a good sampling of the results via example audio and sequences is on the project website. The code and checkpoints are available. In the future, reproducing this type of work with decoder-only architectures would be compelling. This will take a lot of engineering effort, and the authors mentioned that parameter count would likely matter more at this point.
At another time, I’d like to go back and revisit some of Meta’s work in this area with CM3Leon Meta’s blogpost and paper would be the starting point for that.
Collecting preference data for images
Collecting preference data over text alone is much harder than images. For example, Midjourney has been showing users 4 outputs for quite a while and asking them to select a specific image to upsample or vary. Whichever image you choose is the preference label.

This behavior has been copied across a ton of model suppliers like Ideogram or DALLE. It’s likely due to saving compute that ChatGPT’s DALLE integration doesn’t have this. A more interesting variant is a dataset I see being made by the hot company tldraw. The thing is, right now, they’re feeding it all into OpenAI’s API, so hopefully they turned off the setting “train on my data,” which is on by default.
Essentially, tldraw works by passing in images with a special prompt to GPT4-V to get functioning web code out. The interesting part is how you can apply comments directly on the canvas and regenerate the element. In the figure below, the founder Steve Ruiz shows (from Latent Space) what happens if you just add a short nudge in the form of written text to GPT4-V, it’ll often fix the problem.

From this, there’s a preference pair for GPT4-V based on the original prompt and then the first generated code would be the rejected sample, with the minor follow-up being the chosen sample. These sorts of real-world usage in multimodal RLHF will be the most valuable. We’ll see that most of the academically available visual RLHF data will be limited to data augmentation to start, which I expect to have less compelling areas of application.
LLaVA-RLHF: The first experiments in multimodal RLHF fine-tuning
Large Language and Vision Assistant (LLaVA) was one of the most popular papers at NeurIPs (with more details shared in the v1.5 report). The models (of which there is a v1 and a v1.5 at both 7 billion and 13 billion parameters) represent some of the first easy-to-use and benchmark-strong open visual language models (VLM). This wasn’t surprising to me, as it seemed like more of the same exciting news from the new pace of ML developments. What caught both my eyes and the eyes of many in my network was the LLaVA-RLHF paper, which was seemingly the first open, substantial RLHF tune for a VLM. At least it was the first one the break through. The work involves two primary axes: a new factually augmented RLHF technique (Fact-RLHF) and a new synthetic dataset generated with GPT4V.
The system diagram is quite good, which at first looks like a normal three-stage RLHF process figure, but is really about the signal flow of correcting errors in multimodal instruction data.

The first sentence of their abstract points the work directly at investigating my most pressing questions about multi-modal RLHF, how do we cross modalities during instruction tuning and RLHF? It reads: “Large Multimodal Models (LMM) are built across modalities and the misalignment between two modalities can result in “hallucination”, generating textual outputs that are not grounded by the multimodal information in context.” To solve this, the paper does most of its work around generating data that relies on both modalities and learning how to evaluate it. Regarding data, the authors create
High-Quality Instruct Data. We convert VQA-v2 (83k) and A-OKVQA (16k) into a multi-round QA task, and Flickr30k (23k) into a Spotting Captioning task, and train the LLaVA-SFT+ models based on the new mixture of data including LLaVA-Instruct-90k (randomly sampled from LLaVA-Instruct-150K)
For better linking of images and text during training, the authors propose
Factually-Augmented RLHF. We introduce a novel algorithm named Factually Augmented RLHF (Fact-RLHF), which calibrates the reward signals by augmenting them with additional information such as image captions or ground-truth multi-choice option. The reward model is trained on 10k hallucination-aware human preference data.
The other contribution of the paper is MMHal-Bench, a dataset “with 96 image-question pairs, ranging in 8 question categories and 12 object topics from OpenImages.” This feels like the early days of finding something like MT Bench and AlpacaEval for multimodal inputs. They show that using their RLHF technique gives a moderate bump on benchmark scores.
I’m not particularly versed in various VLM benchmarks, so it’s not time for me to add commentary on how strong the models are relative to GPT4-V beyond the obvious fact that there’s a long way to go. A good summary of at least the peer models is in Table 4 of the paper. MMBench defines 20 abilities of multimodal models.
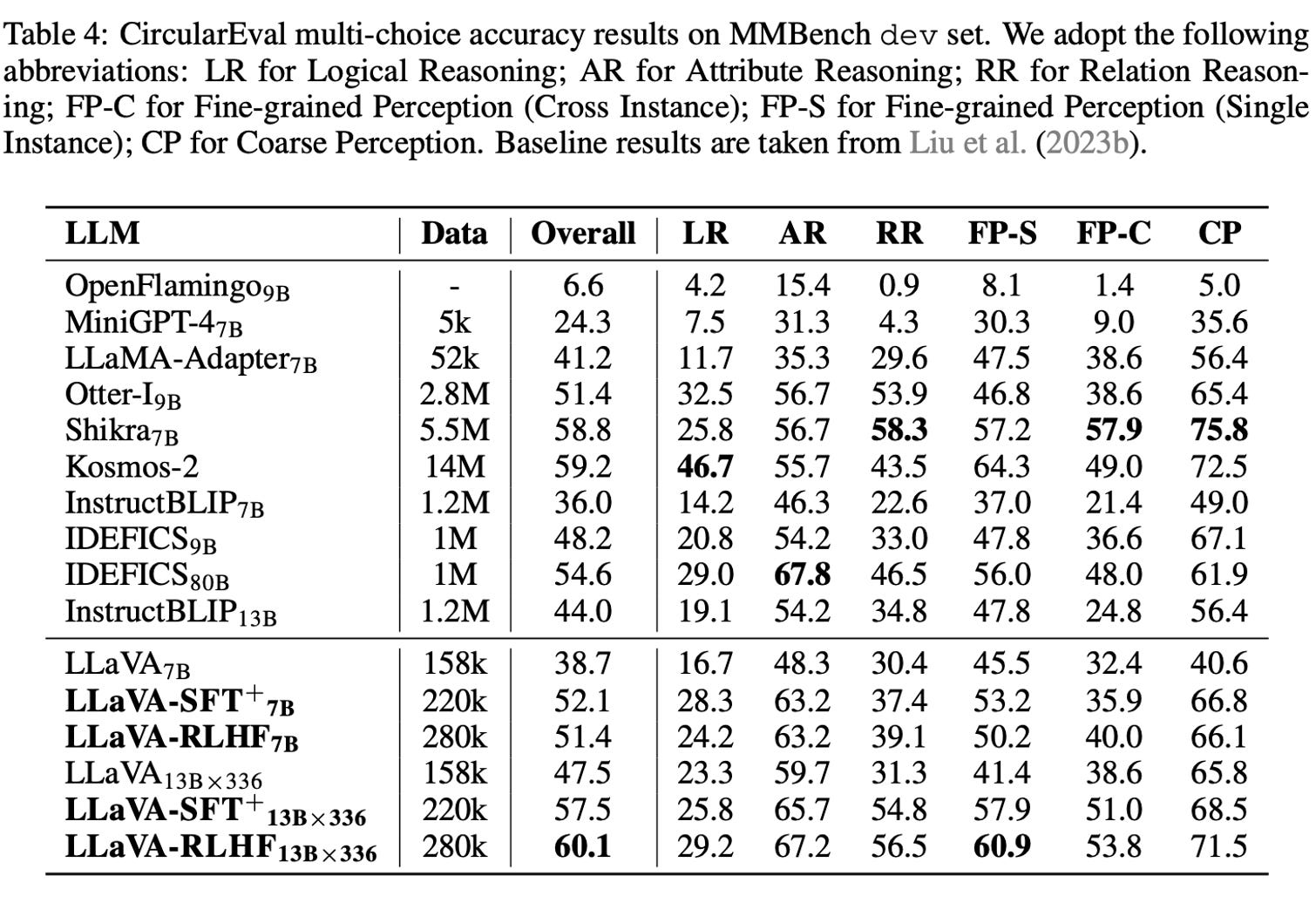
As someone who was at HuggingFace for the IDEFICS training, I’m impressed to see how fast it was surpassed. That’s how it goes this year! If you can’t keep releasing new iterations of your model, you fall behind.
Multimodal RLHF questions, ideas, and resources
My core question around multimodal RLHF is how to merge workstreams and goals. How do we balance the data that is language only with the need to be always training with images (or the model will overfit to text)? What percentage of image data is needed in the pretraining vs. fine-tuning corpus? How are people even going to use chat VLMs, would our existing datasets like Ultrafeedback even apply to the new use case?
How much harder, in terms of accuracy, diversity, and cost, will it be to generate multimodal preference and instruction datasets? We’ve seen how extensively GPT4 is used for open LLMs that are text-only. As far as I know, GPT4-V is way more expensive than text only, and it comes with a new set of safety filters to get used to. In short, we’ll have the same GPT4V datasets as ultrafeedback, but we’re far from understanding why these work. We need to study them with text only first.
A related area in my mind is multi-objective RLHF. From the Gemini paper: “We use multi-objective optimization with a weighted sum of reward scores from helpfulness, factuality, and safety, to train a multi-headed reward model.” Does progress with methods like this make it easier to translate to multimodality? Or, does this only apply when outputting images?
Some more resources I found in this area are a 2022 DeepMind paper, Improving Multimodal Interactive Agents with Reinforcement Learning from Human Feedback, a roundup from Davis Summarizes Papers on multimodal RLHF and chain of thought (focus on diffusion), the InstructBLIP paper from earlier in 2023, a systems paper on multimodal generation from Meta that may have hints, Silkie: Preference Distillation for Large Visual Language Models, RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback (which releases the dataset), a recent diffusion DPO paper, and another recent paper on scaling VLMs.
I’m most excited to see how creative people figure out how to make synthetic data work here. I’m guessing people will try and save money and use things other than GPT4-V, such as multiple models in one synthetic data system.
Audio of this post will be available later today on podcast players, for when you’re on the go, and YouTube, which I think is a better experience with the normal use of figures.
Looking for more content? Check out my podcast with Tom Gilbert, The Retort.
Newsletter stuff
Elsewhere from me
Episode 14 of The Retort is AI is literally the culture war, figuratively speaking, you know what we’re going to dig into.
Models & datasets
I made a dataset of the various test sets of preference data (there aren’t many out there) so formatting is common and ready to be used.
Python DPO pairs from Alpaca data.
MATHPILE: A pretraining scale corpus for math data.
New WizardCoder model, they tend to be good.
frankenMOE (taking parts from 4 different models and loss goes down?).
Llama pro: one of the first smaller models.
Tiny Llama is the peer. Which is better?Phi 2 is now MIT license. Though something is up with the model internals that makes it memory hungry (link).
Links
Apple models coming this year? I’m pretty bullish.
Synthetic datasets list from Eugene Yan.
Post from Simon on internet habits and building momentum.
A website for datasets that’ll help safety training of LLMs.
Awesome project for open-source robotics at Stanford.
Housekeeping
New paid feature, Discord: an invite to the subscriber-only Discord server is in email footers.
Interconnects referrals: You’ll accumulate a free paid sub if you use a referral link from the Interconnects Leaderboard.
Student discounts: Want a large paid student discount, go to the About page.
Reward model comes in a static form as an output of state b)
Hi @Nathan - In the RLHF systems diagram above the 3rd stage where the Policy LLM is getting trained, we see the signal of corrected caption passed into reward model - is the reward model also getting updated?