

The latest open artifacts (#6): Reasoning models, China's lead in open-source, and a growing multimodal space
Artifacts Log 6. The open LM ecosystem yet again accelerates.
It’s been a bit since the last Artifacts Log1 post — our monthly roundups of open models, datasets, and links in the AI space — and there have been a few updates since then. We’re trying to make this a more useful format for readers, better curating models, more useful groupings, and so on. Yes, you caught that right, it’s now we, Florian Brand, a Ph.D. student at Trier University, is the first additional contributor to Interconnects. There’s more on the operations side happening behind the scenes to improve Interconnects, but that’ll be shared just when relevant.
The biggest story on the “artifacts” side of the world is how Chinese labs have overtaken the capabilities of their leading American (and global) counterparts. DeepSeek is the headline story with DeepSeek V3 and DeepSeek R1, but continued contributions from Qwen and surprising models from Minimax (and others) put us at the first point in time where Chinese models are obviously ahead. We need to see what Llama 4 looks like, but having both these conditions be met is one for the history books:
The arguably most important model of today is open weights and under a permissive license, with DeepSeek R1, and
Chinese AI labs have taken a clear lead in open-weight AI models.
This has both obvious and nuanced geopolitical implications that will be addressed in future posts, but the trajectory is one to follow. How will the new U.S. administration react to these facts?
As usual, we start with links and then we’ll run a broken-out section of reasoning models so long as the phase is so hot. We’re well and truly into the “Alpaca era” for reasoning models so there will be a lot to learn in the coming months.
This is a long issue as we catch up on a missed issue or two. The artifacts in this post are listed in this HuggingFace collection.
Our picks
To make these easier to process, we’re pulling a few models (or datasets) front and center that are more helpful to know of. Then, you can dig into the rest.
Bespoke-Stratos-17k by bespokelabs: The first meaningful, public R1 distillation dataset, covering 17k reasoning traces for coding and math. Released under Apache 2.0. There is going to be a flood of these applied to many domains.
MiniMax-Text-01 by MiniMaxAI: Hailuo AI, regarded as the Chinese CharacterAI, also known for their (closed-source) video generation models, has released its first text model under a permissive license (still is custom, but simpler than Llama 3 license). Similar to DeepSeek V3, it is a big MoE model with 456B total params (46B active).
While the model is not as strong as DeepSeek V3, the main selling point is its 4 Million context window, which is unmatched in the open model space. In an interview (in Chinese), the CEO expressed that open sourcing accelerates technology development and that they want to continue to contribute to the community. They are also planning to release models more focused on coding and a reasoning model in the future.
ModernBERT-base by answerdotai in collaboration with LightOn: As a blast to the past, Answer.AI has released a model based on the BERT architecture, which is still widely used in the enterprise context. The model uses a lot of modern techniques, i.e., RoPE for long context, Flash Attention and training on a lot of tokens (2 Trillion) for BERT standards. The accompanying paper is information-dense and goes in-depth on the technical decisions made.

Eurus-2-7B-PRIME by PRIME-RL (Blog, code): Okay this is a technical one. The takeaway, for now, is that DPO-like ideas (where you can use the logprobabilities within a model as other types of signals) can be applied to process supervision.
A squint at this would be strong performance without needing complex pipelines to train an actual process reward model (PRM). A complex take on this is that it could scale more nicely than training reward models because when getting the reward from the policy model itself it is easier to add regularization that avoids reward hacking.
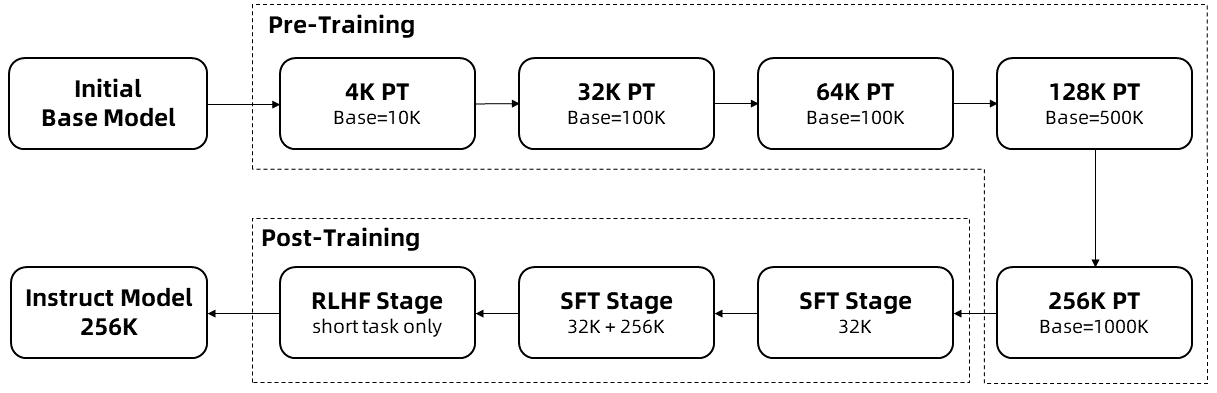
Qwen2.5-7B-Instruct-1M by Qwen: Minimax is not the only model breaching a context size of a million tokens. They use Dual Chunk Attention with eight phases of long-context training. The accompanying blog (and technical report) goes into more detail. They also contributed to vLLM to make the models easily runnable for others, which will help more long-context tooling be built around open LMs in the future! The long-context recipe is below.



Links
For those of you who didn’t see it, Simon Willison had a great 2024 year in review for LLMs. Worth checking out if you feel caught off guard by recent developments.
With the rise of DeepSeek, it’s worth revisiting this interview with the DeepSeek CEO translated by ChinaTalk.
Chris Manning’s keynote at the Conference on Language Models is a wonderful provocation that language is actually a very powerful medium for capturing understanding and meaning and that people over-rely on other modalities. This ties nicely into the growing debate on what reasoning means.
Jan Leike had a nice post on how to motivate post training research and how having models that can be more precisely controlled, through the lens of eliciting behavior, is important for alignment.
Dylan Patel of SemiAnalysis gave a fun lecture on many of his recent topics: inference math, scaling, and data centers.
This conversation at the Lenny’s Newsletter product conference is evergreen in understanding how productizing AI works (or doesn’t).
Onto the rest of the artifacts
Reasoning
Models
Llama-3.2V-11B-cot by Xkev: A Llama-3.2 Vision-based reasoning model, trained on a dataset containing reasoning stages. These stages are then used with beam search during inference.
deepthought-8b-llama-v0.01-alpha by ruliad: A Llama-based reasoning model, outputting its thoughts in structured JSON.
QwQ-32B-Preview by Qwen: A preview of Qwen’s reasoning model, which was released before R1, so researchers have been using this as a model for their experiments over R1 and its distilled versions.
QVQ-72B-Preview by Qwen: A version of QwQ which is vision-capable.
Sky-T1-32B-Preview by NovaSky-AI: A model fine-tuned from Qwen2.5 32B by training it on outputs of QwQ-32B and rejecting invalid outputs by checking them against the ground truth (for math problems) or running the unit tests (for coding problems). We will see more of these models in the future, similar to the emergence of Alpaca and related models in 2023.
Sky-T1-32B-Flash by NovaSky-AI: An improved version of Sky-T1 with shorter responses for simpler questions. This is achieved by picking shorter, but still, correct responses, rewriting the responses, and by using a length-normalized version of DPO.
(as you know) DeepSeek-R1 by deepseek-ai: Deepseek has released the full version of r1-lite, which we also covered in our blogpost. Aside from the official benchmark numbers, the model is remarkably strong and on par with o1, i.e., it currently is one of the best models available, both open and closed. The model is available under MIT, a license that DeepSeek has used for their experimental models like Janus in the past. Alongside the R1 and R1-Zero models, which are MoE, they also distilled the models with SFT onto Qwen and Llama of various sizes, with the appropriate licenses matching the original models. These models are incredibly strong for their size and continue the trend of distilling big models onto smaller ones, just like it has been done by the other, western labs for quite some time now. The distilled models are trained with SFT only - in the report, they mentioned that applying RL yields even further gains.
Datasets
NuminaMath-QwQ-CoT-5M by PrimeIntellect: A 5M dataset of reasoning traces for math problems, generated by QwQ-32B.
Codebases
A new blog post (code) came out showcasing RL training applied directly to the Qwen 2.5 Math 7B model — DeepSeek style — that boosted results notably. What’s most interesting to me is how similar the curves look to our RL experiments at Ai2. There’s this period where response length goes down before increasing again. We need to know why this happens ASAP.

Lots of people are building RL + LM codebases these days. Ai2 and HuggingFace implemented GRPO in their frameworks recently. HuggingFace started another repo with recipes for R1-style training. All the interest is teaching me of new repos too, like veRL.

Models
Instruct
There are a ton of models here as we catch up. Strong models are coming from IBM (yes, surprises people), Cohere, Microsoft, Qwen, Meta, and many other players.
Flagship
granite-3.1-8b-instruct by ibm-granite: Largely flying under the radar, IBM steadily releases models in their Granite series to rival the smaller Llama models under an Apache 2.0 license.
aya-expanse-32b by CohereForAI: Cohere has released a new model of their Aya series by fine-tuning their Command R models, focusing on multilinguality by using multilingual preference training.
phi-4 by microsoft: Another entry in the Phi series, which cannot get rid of its reputation of performing well on benchmarks, while falling short in real-world usage.