

The latest open artifacts (#8): The return of ~30B models, side effects of OpenAI's proposed DeepSeek ban, and yet another reasoning roundup
Artifacts Log 8. Expect this pace to continue until mid summer.
OpenAI has had a tenuous relationship with open-source AI since ChatGPT. First was the existential risk policies, now it is real competitive threats from abroad. OpenAI released their comment on the new administration’s AI Action Plan, which has a lot in it, and this portion immediately stuck out to the broader AI community:

OpenAI claims, without existing evidence, that DeepSeek is “state-subsidized, state-controlled, and freely available,” so “the cost its users is their privacy and security.” Without flat out saying it, they’re insinuating that Chinese models should be banned within the U.S.
Yes, it is very reasonable to worry about information security for API models going to China, but this could very easily have unintended consequences of cutting off all Chinese AI models, open and closed, from the American system. This would be an extreme set back to the open-source AI movement, as open solutions win with a plurality of options.
The team at Ai2 had a much simpler message around open models in our comment to the OSTP for the White House AI Action Plan. The United States needs to invest in infrastructure and organizations who are building open tooling. By investing and enabling people building in and around the U.S. (i.e., our allies), the open model default will be effectively American. When it is the standard, benefits from open models from China get absorbed and increase progress, while being able to check for the reality of the risks that OpenAI posed above.
As you can see in this post, times are good for open models. It doesn’t take a lot to help it grow, but you need to be careful of some recommendations (or avoid some bills that have been drafted recently1).
The structure of these is:
Our Picks: The models and datasets you need to know about.
Links: Interesting reads from the AI community.
Reasoning: All the reasoning models and datasets.
($) Models: The rest of the open models, from diffusion language models to video generation.
($) Datasets: Open datasets to build on.
Post likely too long for email, we recommend reading on the web version.
Our Picks
What is notable here is about is how all of these models are in the 24B-32B range! This is a super popular size with developers as it is a nice combination of very capable, yet not too unwieldily large. Other than Qwen, there had been very few notable models in this range (with Llama 3 skipping it for risk concerns).
reka-flash-3 by RekaAI: A 21B reasoning model, trained with RLOO and released under Apache 2.0. This is the first open weights release by Reka AI but it went under due to the release of Gemma shortly after. However, the model is really capable, especially for its size. In our testing, it came close to the performance of 32B models, such as the R1-distill of Qwen and QwQ 32B.
OLMo-2-0325-32B-Instruct by allenai: A truly open model release, rivaling the quality of GPT-3.5 and the OG GPT-4. For more information, see our post. The base models are released alongside the instruction models.
gemma-3-27b-it by google: Aside from the points mentioned in our post, the Gemma release highlights some tricks used by labs: Knowledge Distillation using a big teacher model, a (5:1) local / global attention layer ratio. The latter is a configuration outlined by Noam Shazeer during his time at Character.AI. Apart from the instruction models, Google also releases the pre-trained base model.
Mistral-Small-3.1-24B-Instruct-2503 by mistralai: Mistral has updated their small model to support a longer context (from 32K in the last version to 128K now), as well as images as input. It keeps the Apache 2.0 license and is an overall strong model. In our testing (yes, hoping to continue to grow this internal testing), the model is stronger than a lot similarly sized models.
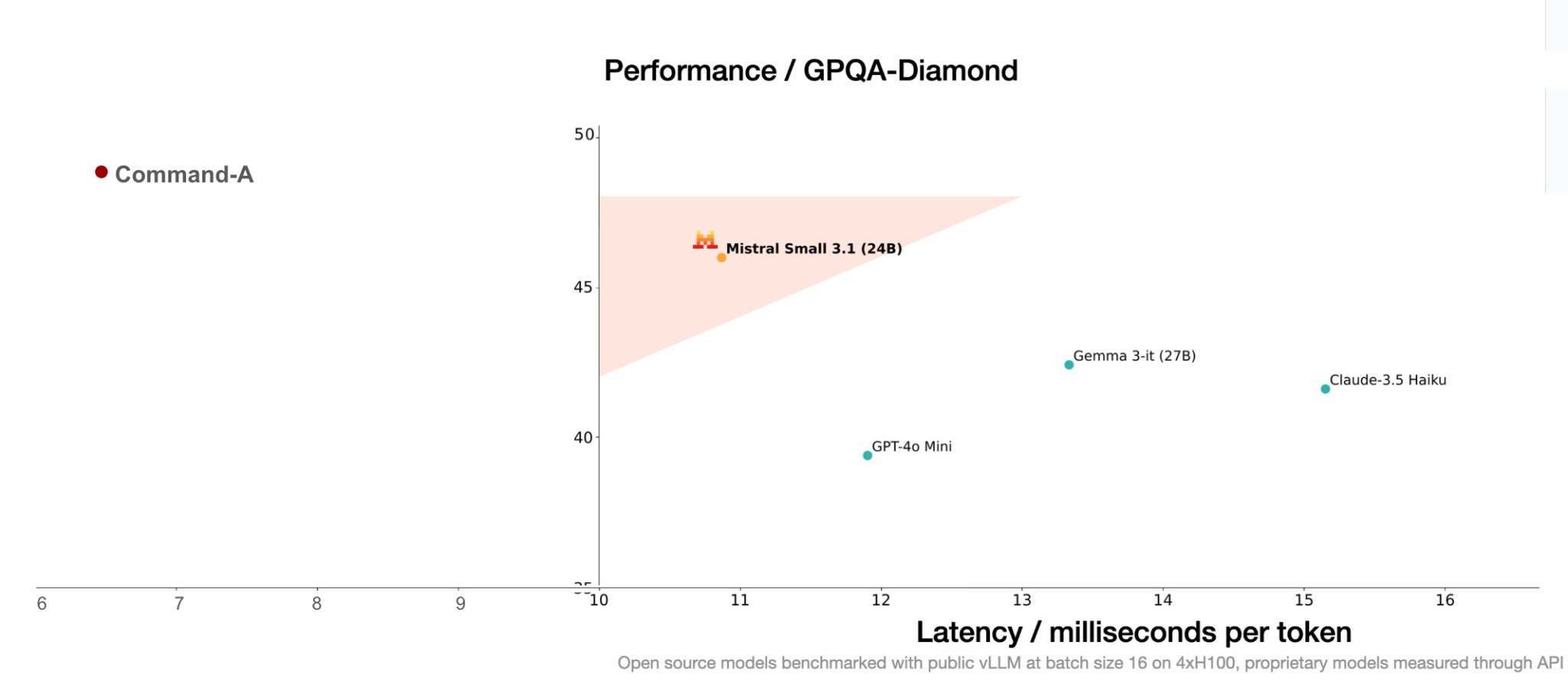
Though, the funniest part of this release was the meme’s from Mistral’s patented “triangle performance plots.” Below is the response from Cohere Co-founder Nick Frosst to the model, showcasing the speed of Command-A (another awesome open-weight model, highlighted below in this issue).
Source: https://x.com/nickfrosst/status/1901984106746941917
Links
A multi-institution group launched a DNA prediction foundation model, Evo 2, which sparked many great discussions on the role of foundation models for biology.
A good post on the current role and economics of data annotation companies came about, arguing why they don’t scale (plus reading list).
A blog post I referenced in my Elicitation Theory of Post-training piece is a good review on how post-training works.
Unsloth had a nice blog post on improving their GRPO implementation.
Horace He had a good career’s post on his move from Pytorch to Thinking Machines.
Kevin Xu had a good post on open-source’s role as soft power for technology (focusing on AI of course).
Elie at HuggingFace had some nice slides on the state of pretraining research.


Carlini had a series of posts as he moves from DeepMind to Anthropic. Particularly the career’s post on why he left DeepMind is most interesting for an understanding of how talent and information moves in the AI world right now.
Google launched the native image generation capabilities of Gemini 2.0 Flash and it is pretty fun to play around with it. Mostly, it’s interesting because of HOW LONG it took for this to ship, given it was one of the promising reasons to switch from GPT-4 normal to GPT-4o, and how it was highlighted in the Gemini launch.
Naturally, this becoming general audience resulted in a lot of memes floating around on social media with people doing all sorts of things. In case you cannot find it: You need to use Google AI Studio and selectGemini 2.0 Flash (Image Generation) Experimentalin theModeldropdown.

Ben Thompson did in in-depth interview with Sam Altman about the history, current state and future of OpenAI, the state of the AI ecosystem and AGI. His work at Stratechery is a wonderful complement to Interconnects.
Reasoning
Models
R1-Omni-0.5B by StarJiaxing: A multimodal reasoning model combining Qwen, Whisper and SigLIP to detect human emotions.
SearchR1-nq_hotpotqa_train-llama3.2-3b-em-ppo by PeterJinGo: A RL-trained model that learns to use search engines with multi-turn support. Those experiments are important first steps to training an (open) replication of OpenAI Deep Research.
OlympicCoder-7B by open-r1 (and their dataset codeforces with competitive coding problems): A Qwen2.5 fine-tuned model on and for competitive coding problems. This is exciting as one of a few open projects focusing on reasoning for code performance — most are still on math. Here’s their IOI scores:

Arcee-Maestro-7B-Preview by arcee-ai: A GRPO fine-tuned model on top of R1-Distill-Qwen-7B.
DeepHermes-3-Mistral-24B-Preview by NousResearch: A R1-based fine-tune onto Mistral 3 24B. Similar to the Llama-based version, the model can switch between outputting reasoning tokens based on the system prompt.
Light-R1-32B by qihoo360: A model trained with curriculum learning, i.e., training on examples with increasing difficulty in two SFT and one DPO stage.
Open-Reasoner-Zero-32B by Open-Reasoner-Zero: An open replication of DeepSeek-R1-Zero-Qwen-32B, i.e., a fine-tuned model of Qwen2.5 32B with RL only, missing the SFT cold start. They share the used code and data, as well as a tech report. This work will likely be covered more in a future post, but you should think of it as the most robust RL-on-base-model report since the DeepSeek R1 release.

Source: https://github.com/Open-Reasoner-Zero/Open-Reasoner-Zero/blob/main/ORZ_paper.pdf QwQ-32B by Qwen: The final version of QwQ, the reasoning model by Alibaba's Qwen, which was previously released as a preview version. It is also released under Apache 2.0. It is a strong model, especially considering its size.
EXAONE-Deep-32B by LGAI-EXAONE: A series of reasoning models trained with SFT, followed by DPO and a GRPO variant as well as SEMPER during the RL phase. It performs surprisingly well given the low number of examples (10K) during the final RL phase.

Datasets
natural_reasoning by facebook: A dataset of questions and their respective answers extracted from the pre-training datasets DCLM and FineMath, decontaminated for popular benchmarks such as MATH or GPQA.

The dataset creation process for NaturalReasoning. Source: https://arxiv.org/abs/2502.13124 Big-Math-RL-Verified by SynthLabsAI: A large math reasoning dataset with verified answers.
GeneralThought-430K by GeneralReasoning: Ross Taylor, who was also a guest in a Podcast episode, launched a new project called General Reasoning, which shows questions from benchmarks of various fields and the responses from various reasoning models. Besides the leaderboard, the regularly released data dumps are a treasure trove for training reasoning models.
We’ll see what people build on this, as there really are not many people regularly releasing datasets in this space.
