

How to scale RL
A bombshell paper from Meta and friends.
Two quick housekeeping items before I get to the post.
1. I’ll be in SF this week for the PyTorch conference (22-23), AI Infra Summit (21st), and other local events. Come say hi.
2. I launched a new Substack AI bundle with 8 of my favorite publications packaged together for teams of 20+. Learn more at readsail.com.
Onto the post!
“Scaling reinforcement learning (RL)” is the zeitgeisty way to capture the next steps in improving frontier models — everyone is staring at the same hill they plan on climbing. How these different groups are approaching the problem has been a poorly kept secret. It’s a simple idea, but one that’s hard to copy: Predicting the trajectory of the learning curve. There have been two reasons this is hard to copy for academics, which will be solved on different time scales:
The lack of stable RL training setups. There are many RL libraries being developed in parallel and the community has collectively made them much more ready for big RL runs over the summer.
The lack of compute for experimentation.
These aren’t new stories. In many ways they mirror the progression of open Mixture of Experts (MoE) models, where they still lag far behind the implementations of the codebases within top AI laboratories because it involves overcoming substantial engineering headaches in an expensive experimentation regime. Scaling RL has been shaping up the same way, but it turns out it is just a bit more approachable.
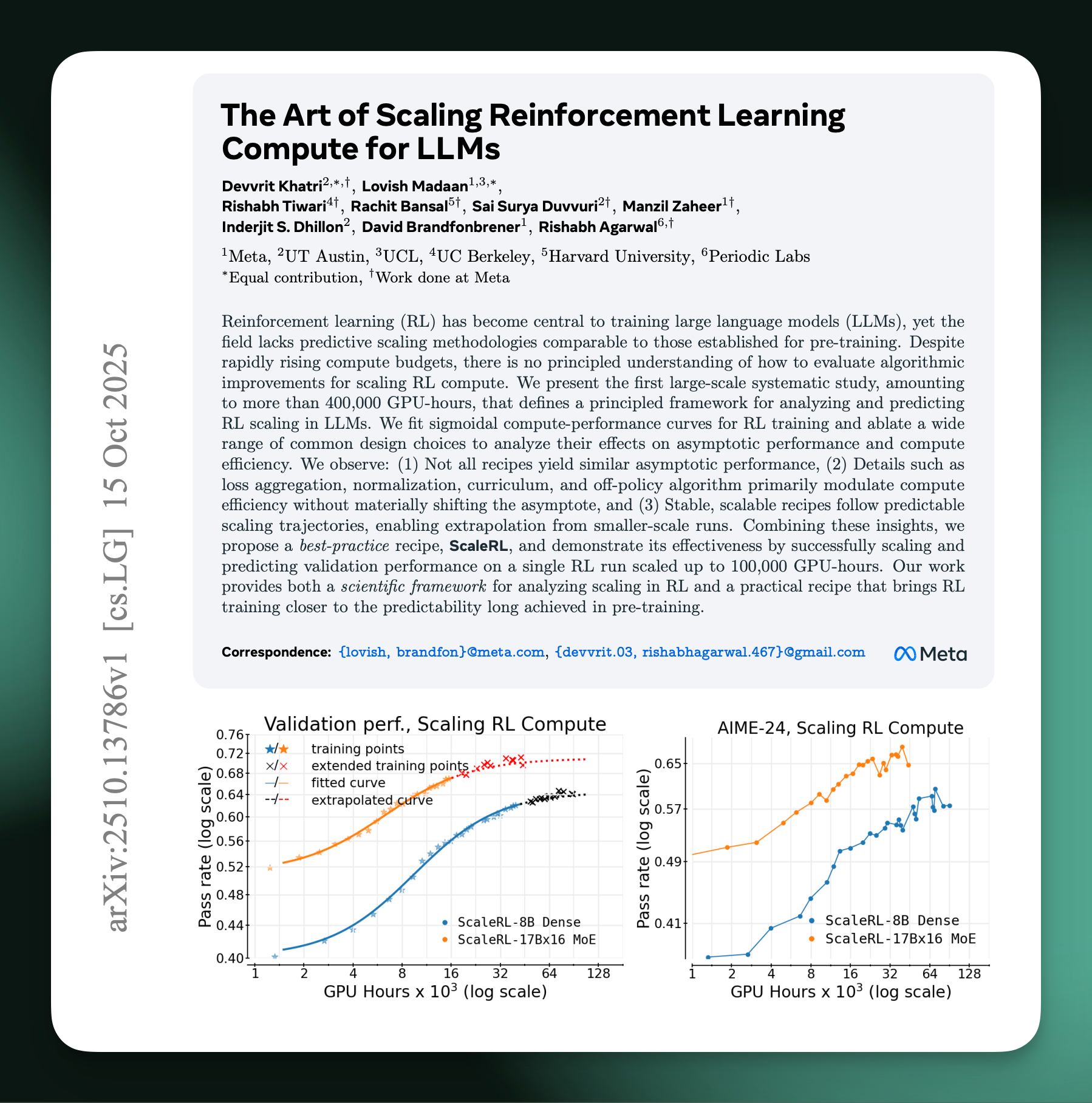
Last week we got the first definitive paper on scaling RL. It proposes a clear method to extrapolate RL learning curves over compute scales and sets a baseline for the order of compute that should be spent to have top-end performance. The paper, The Art of Scaling Reinforcement Learning Compute for LLMs (Khatri & Madaan et al. 2025), referred to as ScaleRL, is a must read for anyone looking to understand the absolute cutting edge of RL algorithms and infrastructure.
For some personal context, for all of 2025 we’ve had our main slack channel in the reasoning space at Ai2 called “scaling-rl” because of how essential we knew the first clear piece of work in this area would be. This post covers the key details and what I see coming next.
There are two key things you need to know about these, even if all the lower level RL math is confusing to you too. First is how these intuitively work and what they’re actually predicting. Second is how they compare to the pretraining scaling laws we know and love.
To the first point, what the approach entails is taking one (or a handful of) your key base models, run a bit of RL on each of them, predict the end point by a bit of shape forecasting across many stable runs, then, for your big run, you can predict the end point in terms of final performance. The shape of RL runs that motivates this is how you see your model often gain ~80% of the accuracy gain in the first few steps, and you wonder what the final performance of the model will be if you trained on your entire dataset.
The authors define three constants that they fit, A for a measure of the peak performance — accuracy on a subset of your training dataset, aka the validation set, B for the slope of the sigmoid curve, and C as compute on the x axis. What is then done is that you take a set of RL training jobs and you fit a regression that predicts the last chunk of real training points given the early measurements of accuracy over time. Then, you can compare the predicted final performance of your future RL ablations on that starting model by understanding the normal shape of your RL learning curves.
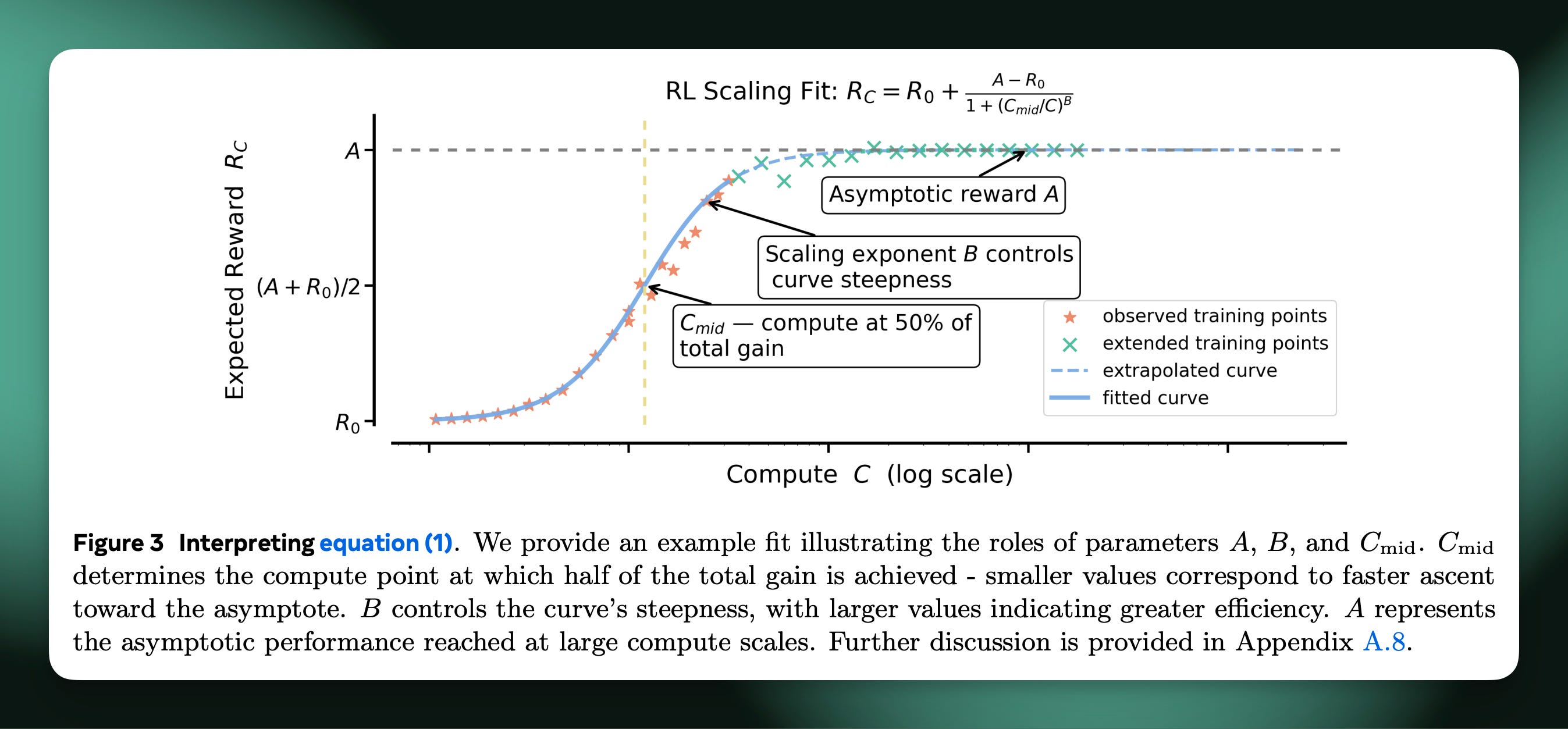
Second is to consider how this compares to pretraining scaling laws. These are very far from the deeply insightful power law relating downstream test loss to pretraining compute — accuracy on RL training datasets is a far more bounded measure than next token prediction. The RL scaling laws are most useful for ablating design choices, relative to pointing to something fundamental about the nature of models. In many ways, scaling laws for pretraining could’ve been viewed this way at the beginning, too, so we’ll see how RL evolves from here.
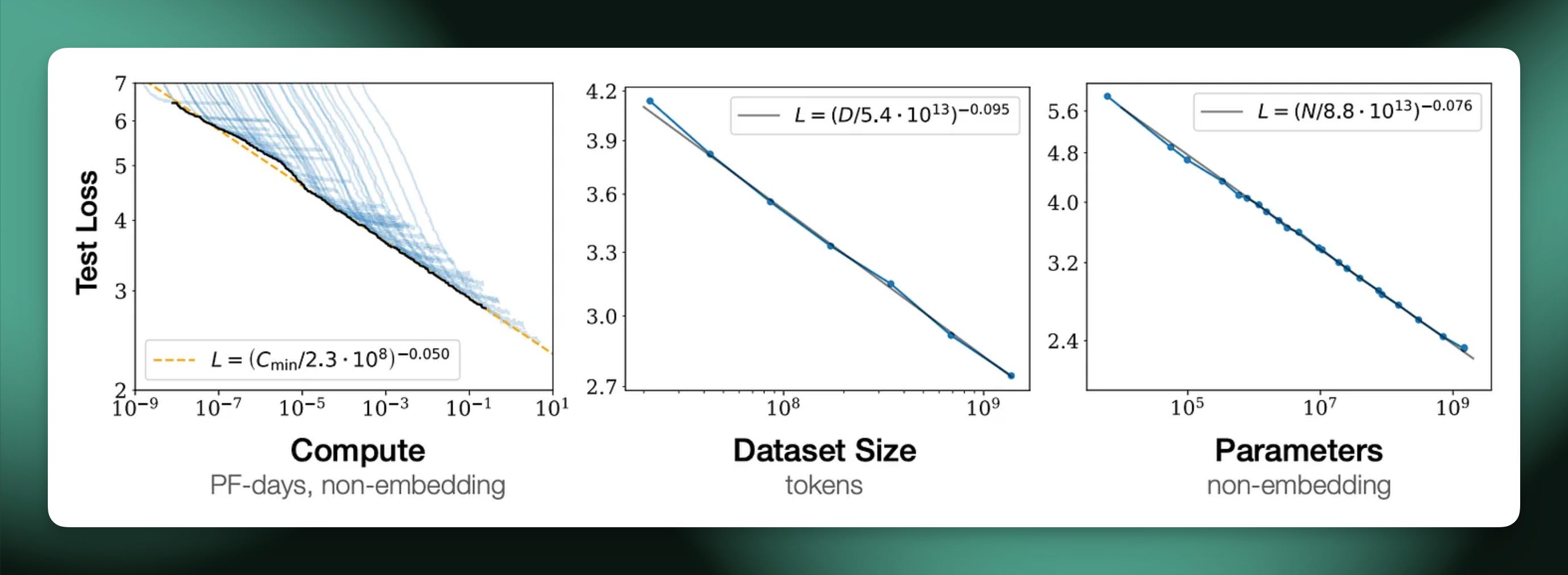
With that difference, scaling laws for RL will play a very different role in training leading models than the pretraining scaling laws we have today. The pretraining laws are about choosing the exact configuration for your big pretraining run (that you can’t really run a meaningful chunk of to debug at all), where RL is more about ablating which algorithm you’ll let run much longer.
In pretraining many decisions depend on your budget and scaling laws can give the answer. Your training compute, communication bottlenecks, maximum run time, data availability, etc. all define a certain model window. Scaling laws for RL may inform this very soon, but for now it's best to think about scaling laws as a way to extract the maximum performance from a given base model.
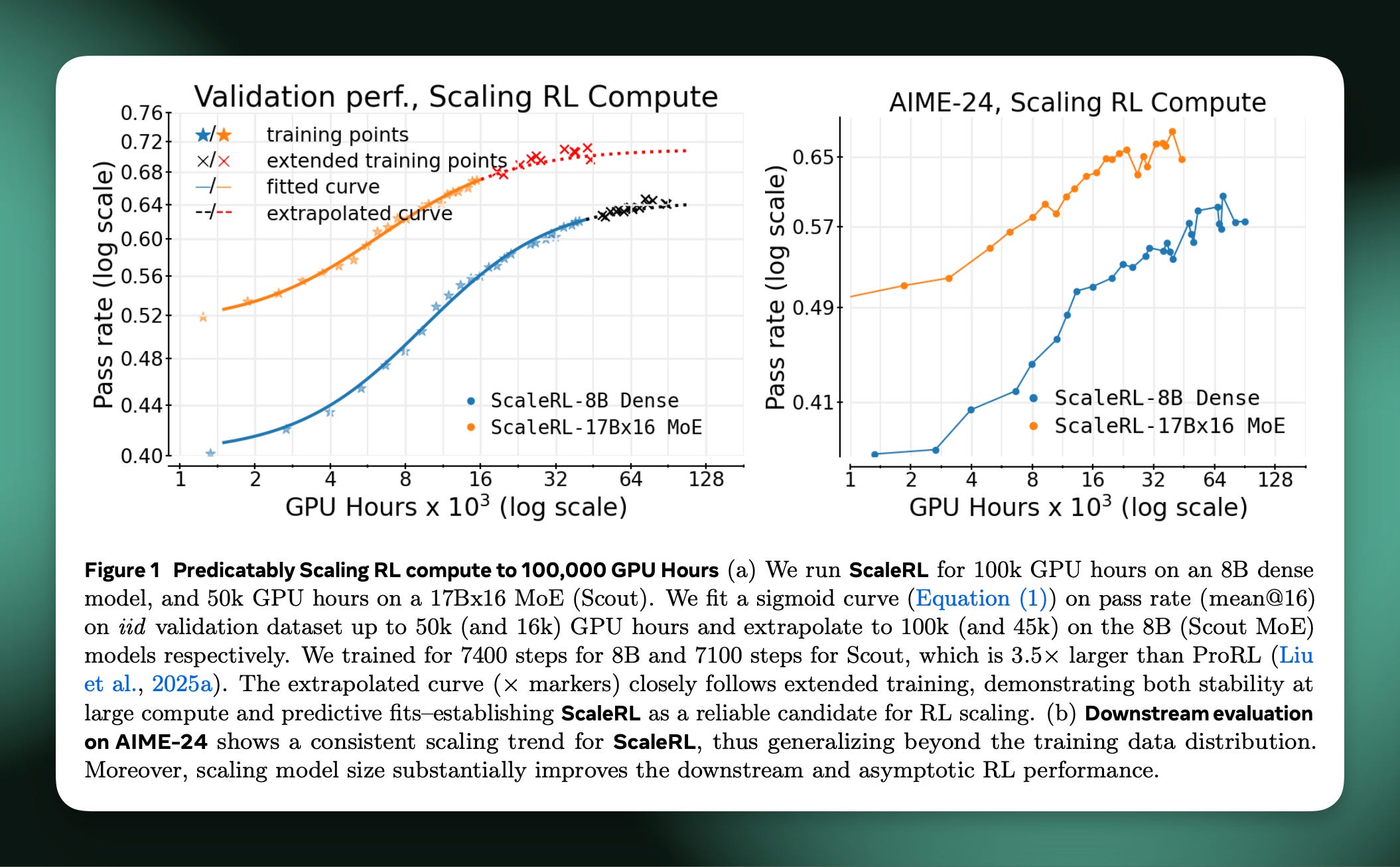
For all of these reasons, scaling RL is more like an art, as the authors say it, because it’s about finding the run that’ll get the last few percentage points of performance when let run over an extra order of magnitude (or two) of samples. It’s a fine grained way to extrapolate RL curves — which have a standard shape of a quick rise then a slow saturation. In practice, the authors fit curves over 1/4 of their training compute to predict the outcome after the remaining 3/4 of GPU hours. The limits of scaling laws will likely be pushed further in the future (and I don’t have a good heuristic for what percentage of compute is used for establishing pretraining scaling laws, versus what is deployed in the final run, comment if you do!).
From here, the paper quickly gets technical, serving as a check in on the major ideas that dominated the RL research ecosystem in the last 6 months. This paper blesses those as important or not when it comes to scaled up RL training. This fits a recurring trend across language modeling in the last few years: Most of the key ideas are out there, but open labs tend to not have the resources to put them all together in the right configuration. This sort of slow accumulation of knowledge takes an organizational intensity, clarity, and ability that is hard for small research groups to match.
There are a few key ideas that stand out to me as worth knowing and betting on following this paper:
Algorithmic advancements: The paper is very favorable on, arguably painting them as essential, some recent algorithms or advancements. These include truncated importance sampling (TIS), Group Sequence Policy Optimization (GSPO), and Clipped IS-weight Policy Optimization (CISPO) via the MiniMax M1 paper. More on these in a second.
Systems improvements: The authors highlight PipeLine RL (paper or repository) as the canonical reference for the combination of in-flight updates — i.e. changing model weights within one very long generation — and continuous batching — i.e. filling your RL batch over time until you have enough prompts for a learning step — which together represent 4X+ improvements over standard RL implementations on LLMs in terms of throughput. What this looks like in terms of idle GPUs is below, from the ServiceNow paper.

Intuitively, think about what happens if you were to ask 8 different questions to an LLM simultaneously. Some of these would finish early and some would take a long time. If you allocate your GPUs such that they have to finish all 8 questions before moving onto the next stack of questions, inevitably there will be GPUs idle when you’re waiting for the last answer.
Instead, continuous batching pulls in new questions all the time when the GPUs have cycles to do more processing. Though, this is more complicated in the RL setup because after every 8 (or your batch size) of questions you need to update your RL weights. Can you still do this and fill in new questions all the time to the GPUs? What happens to that one question that is taking forever?
In-flight updates is the solution to this. What is literally happening is that the model is updated in the middle of the generation. The models and RL systems just handle this seamlessly, and it removes a ton of idle time in matching the inference weights to the new updates from your RL algorithm.
Not having a few key details like this will make big RL runs not only more expensive in GPUs, but more importantly in time. A 1 day feedback cycle vs 4 days makes for a very different research setup. We have these two features in Open Instruct, our post training repo at Ai2, as do many other RL libraries.

A lot of this is fixing numerics, which is far harder with Mixture of Experts (MoE) models, and something that most open RL research hasn’t touched. This hunt for numerical stability is a common rumor for why Thinking Machines put out the deterministic VLLM blog post ahead of releasing their Tinker API — deterministic VLLM could be their forward pass.
Back to algorithms.
Ross Taylor summarized the various eras of RL algorithms that the community has gone through in 2025. First was the transition from vanilla GRPO to the likes of DAPO (see my earlier post on GRPO tricks or my YouTube video on them too), which noticed issues with the clipping formulation and biases in the GRPO advantage calculation. The next class of algorithms are those cited in this ScaleRL paper, CISPO and a general class of Truncated Importance Sampling1 (TIS) approaches, that are designed for sequence level optimization (often closer to vanilla policy gradient) that account for the probability delta between actor (the GPUs generating completions for RL, often something fast like VLLM) and learner (the GPUs performing gradient updates, in a different library).
This importance sampling term seems to be essential to getting modern RL infrastructure right, as without it, scaling to more complex systems is hard to get numerical stability with. There’s been a lot of chatter about “importance sampling” in the AI community. What is happening, practically, is that the advantage or reward is getting re-weighted by an importance sampling log-ratio corresponding to the difference in probabilities from the two sets of model implementations (e.g. VLLM vs Transformers).
In the midst of all the details, the paper summarizes the state of affairs — large scale yolo RL runs — quite well:
While RL compute for LLMs has scaled massively, our understanding of how to scale RL has not kept pace; the methodology remains more art than science. Recent breakthroughs in RL are largely driven by isolated studies on novel algorithms (e.g., Yu et al. (DAPO, 2025)) and model-specific training reports, such as, MiniMax et al. (2025) and Magistral (Rastogi et al., 2025). Critically, these studies provide ad-hoc solutions tailored to specific contexts, but not how to develop RL methods that scale with compute. This lack of scaling methodology stifles research progress: with no reliable way to identify promising RL candidates a priori, progress is tied to large-scale experimentation that sidelines most of the academic community.
What is important going forward, as this will happen again with future eras of LLMs after this RL era, is why we are here. This happened due to the large overhang in potential from deploying RL, where clear scientific best practices take a long time to establish (even when most of the best researchers are publishing publicly, which isn’t the case today). The leading AI labs can build up fairly sizeable gaps quickly, but information tends to flow out and be reproduced. It’s important that the public options keep materializing — I think they will.
This paper is the first step in a direction of that science of scaling RL, but leaves many questions unanswered:
No information on the impacts of different data. Polaris 53K is used in the paper, which is a solid option of the open, math RL datasets, but we find most of the RL data like this to be solved with a simple SFT set of reasoning traces on 8B models. Harder data may quickly become a limitation of open methods as people scale RL experiments to stronger base models. A paper reproducing these scaling trends over different data regimes is essential.
No information on choosing the right base model. It is accepted that bigger base models perform better with RL — which the authors acknowledge in the paper: “the larger 17B×16 MoE exhibits much higher asymptotic RL performance than the 8B dense model, outperforming the 8B’s performance using only 1/6 of its RL training compute.” With this, we need to perform scaling RL studies that show the optimal base model for downstream RL, in terms of overall compute budgets.
The authors acknowledge these limitations clearly. They’re not trying to hide it!2
To wrap this up, let us recall that there was a big brouhaha in AI circles a few weeks ago when a few frontier lab employees said that GRPO is far behind frontier labs RL stacks. What is more accurate to me is that vanilla GRPO is far behind, and the process of figuring out the set of individual tricks that works on your model and your data is a well kept secret. This new ScaleRL paper is a major step in showing people how to bridge that gap. From here, we have to build the tools in public.
I like this blog on importance sampling for RL (cited in the ScaleRL paper), but the Wikipedia article is helpful on a TLDR of what importance sampling itself is:
Importance sampling is a Monte Carlo method for evaluating properties of a particular distribution, while only having samples generated from a different distribution than the distribution of interest.
This detail I’ve been hearing about constantly as a core thing to get right with modern RL infrastructure.
Another key thing that is omitted from this work, and I think much of the efforts to improve the next model iteration like Claude 4.6 or GPT 5.1 is the “very long horizon” RL that is described when people mention RL solving open problems like scientific discovery. We’re much further from that, but still have substantial improvements to be made on current models.
Nathan, IIRC, you're quite bullish about the long term prospects of RL as applied to LLMs. But what do you think of the findings from the paper published last week "Reasoning with Sampling: Your Base Model is Smarter Than You Think" which seems to further confirm the results of the pass@k paper from earlier in the year. Is the only advantage of RLVR is improved one-shot performance in exchange for the loss of diversity? And even this is only applicable to verifiable scenarios?
Thanks
Thanks for writing this, it clarifies a lot. I totally agree that challenges in scaling RL, especially for academics, really mirror engineering headaches seen with MoE models. Your insight about predicting the learning curve is spot on; it’s such an important 'hill' to understand.