

Arcee AI is a the startup I’ve found to be taking the most real approach to monetizing their open models. With a bunch of experience (and revenue) in the past in post-training open models for specific customer domains, they realized they needed to both prove themselves and fill a niche by pretraining larger, higher performance open models built in the U.S.A. They’re a group of people that are most eagerly answering my call to action for The ATOM Project, and I’ve quickly become friends with them.
Today, they’re releasing their flagship model — Trinity Large — as the culmination of this pivot. In anticipation of this release, I sat down with their CEO Mark McQuade, CTO Lucas Atkins, and pretraining lead, Varun Singh, to have a wide ranging conversation on:
The state (and future) of open vs. closed models,
The business of selling open models for on-prem deployments,
The story of Arcee AI & going “all-in” on this training run,
The ATOM project,
Building frontier model training teams in 6 months,
and other great topics. I really loved this one, and think you well too.
The blog post linked above and technical report have many great details on training the model that I’m still digging into. One of the great things Arcee has been doing is releasing “true base models,” which don’t contain any SFT data or learning rate annealing. The Trinity Large model, an MoE with 400B total and 13B active tokens trained to 17 trillion tokens is the first publicly shared training run at this scale on B300 Nvidia Blackwell machines.
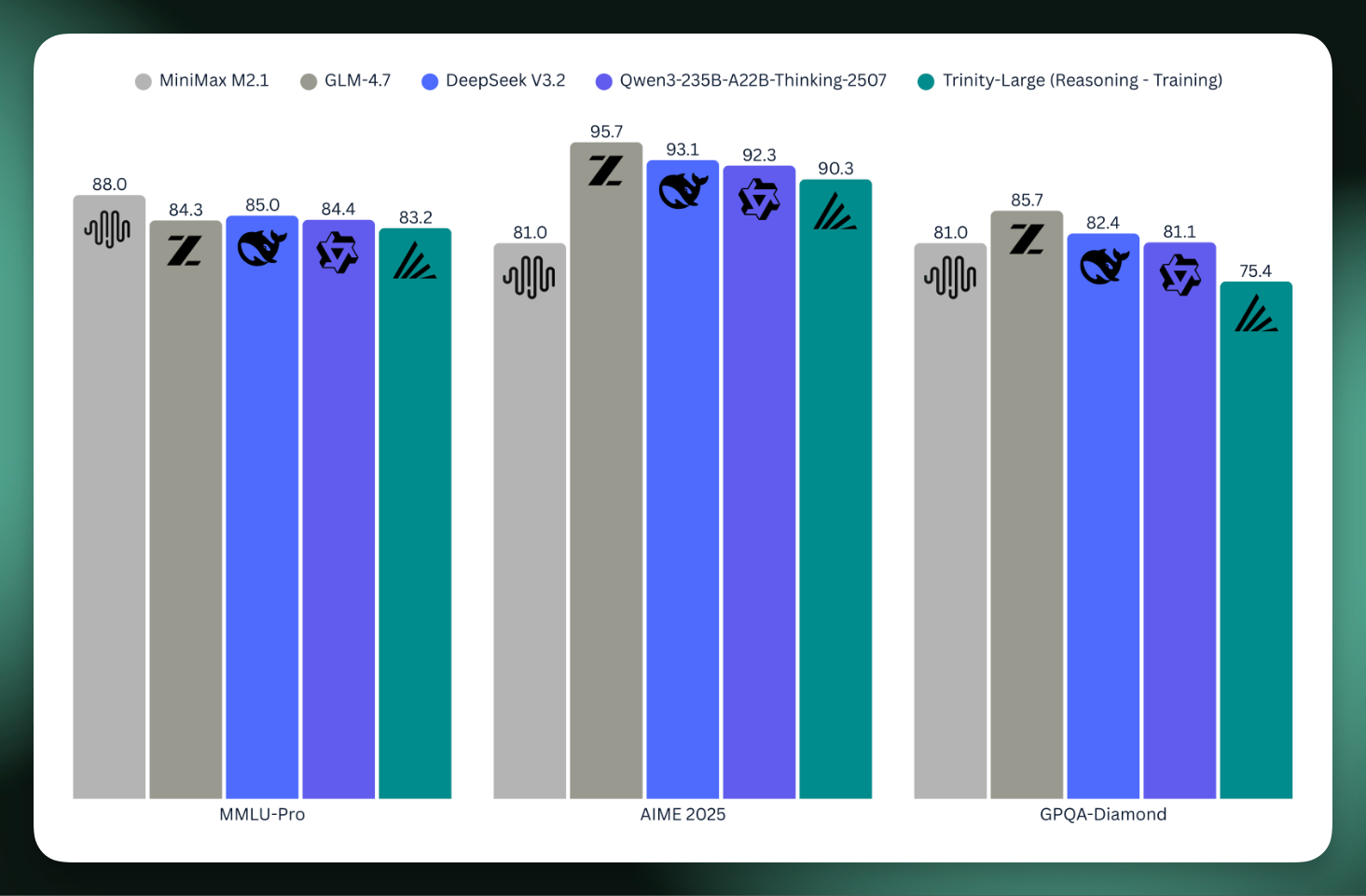
As a preview, they shared the scores for the underway reasoning model relative to the who’s-who of today’s open models. It’s a big step for open models built in the U.S. to scale up like this.
I won’t spoil all the details, so you still listen to the podcast, but their section of the blogpost on cost sets the tone well for the podcast, which is a very frank discussion on how and why to build open models:
When we started this run, we had never pretrained anything remotely like this before.
There was no guarantee this would work. Not the modeling, not the data, not the training itself, not the operational part where you wake up, and a job that costs real money is in a bad state, and you have to decide whether to restart or try to rescue it.
All in—compute, salaries, data, storage, ops—we pulled off this entire effort for $20 million. 4 Models got us here in 6 months.
That number is big for us. It’s also small compared to what frontier labs spend just to keep the lights on. We don’t have infinite retries.
Once I post this, I’m going to dive right into trying the model, and I’m curious what you find too.
Listen on Apple Podcasts, Spotify, YouTube, and where ever you get your podcasts. For other Interconnects interviews, go here.
Guests
Lucas Atkins —X,LinkedIn — CTO; leads pretraining/architecture, wrote the Trinity Manifesto.
Mark McQuade — X, LinkedIn — Founder/CEO; previously at Hugging Face (monetization), Roboflow. Focused on shipping enterprise-grade open-weight models + tooling.
Varun Singh — LinkedIn — pretraining lead.
Most of this interview is conducted with Lucas, but Mark and Varun make great additions at the right times.
Links
Core:
Trinity Large (400B total, 13B active) collection, blog post. Instruct model today, reasoning models soon.
Trinity Mini, 26B total 3B active (base, including releasing pre-anneal checkpoint)
Trinity Nano Preview, 6B total 1B active (base)
Open Source Catalog: https://www.arcee.ai/open-source-catalog
API Docs and Playground (demo)
Socials: GitHub, Hugging Face, X, LinkedIn, YouTube
Trinity Models:
Trinity models page: https://www.arcee.ai/trinity
The Trinity Manifesto (I recommend you read it): https://www.arcee.ai/blog/the-trinity-manifesto
Trinity HF collection — (Trinity Mini & Trinity Nano Preview)
Older models:
AFM-4.5B (and base model) — their first open, pretrained in-house model (blog post).
Five open-weights models (blog): three production models previously exclusive to their SaaS platform plus two research models, released as they shifted focus to AFM — Arcee-SuperNova-v1, Virtuoso-Large, Caller, GLM-4-32B-Base-32K, Homunculus
Open source tools:
MergeKit — model merging toolkit (LGPL license return)
DistillKit — knowledge distillation library
EvolKit — synthetic data generation via evolutionary methods
Related:
Chapters
00:00:00 Intro: Arcee AI, Trinity Models & Trinity Large
00:08:26 Transitioning a Company to Pre-training
00:13:00 Technical Decisions: Muon and MoE
00:18:41 Scaling and MoE Training Pain
00:23:14 Post-training and RL Strategies
00:28:09 Team Structure and Data Scaling
00:31:31 The Trinity Manifesto: US Open Weights
00:42:31 Specialized Models and Distillation
00:47:12 Infrastructure and Hosting 400B
00:50:53 Open Source as a Business Moat
00:56:31 Predictions: Best Model in 2026
01:02:29 Lightning Round & Conclusions
Transcript
Transcript generated with ElevenLabs Scribe v2 and cleaned with Claude Code with Opus 4.5.
00:00:06 Nathan Lambert: I’m here with the Arcee AI team. I personally have become a bit of a fan of Arcee, ‘cause I think what they’re doing in trying to build a company around building open models is a valiant and very reasonable way to do this, ‘cause nobody really has a good business plan for open models, and you just gotta try to figure it out, and you gotta build better models over time. And like open-source software, building in public, I think, is the best way to do this. So this kind of gives you the wheels to get the, um... You get to hit the ground running on whatever you’re doing. And this week, they’re launching their biggest model to date, which I’m very excited to see more kind of large-scale MoE open models. I think we’ve seen, I don’t know, at least ten of these from different providers from China last year, and it’s obviously a thing that’s gonna be international, and a lot of people building models, and the US kind of, for whatever reason, has fewer people building, um, open models here. And I think that wherever people are building models, they can stand on the quality of the work. But whatever. I’ll stop rambling. I’ve got Lucas, Mark, um, Varun on the, on the phone here. I’ve known some of them, and I consider us friends. We’re gonna kind of talk through this model, talk through building open models in the US, so thanks for hopping on the pod.
00:01:16 Mark McQuade: Thanks for having us.
00:01:18 Lucas Atkins: Yeah, yeah. Thanks for having us. Excited.
00:01:20 Varun Singh: Nice to be here.
00:01:20 Nathan Lambert: What- what should people know about this Trinity Large? What’s the actual name of this model? Like, how stoked are you?
00:01:29 Lucas Atkins: So to- yeah.
00:01:29 Nathan Lambert: Like, are you, like, finally made it?
00:01:32 Lucas Atkins: Uh, you know, we’re recording this a little bit before release, so it’s still like, you know, getting everything buttoned up, and inference going at that size is always a challenge, but we’re-- This has been, like, a six-month sprint since we released our first dense model, which is 4.5B, uh, in, in July of last year, 2025. So, um, it’s always been in service of releasing large. I- it’s a 400B, um, thirteen billion active sparse MoE, and, uh, yeah, we’re, we’re super excited. This has just been the entire thing the company’s focused on the last six months, so really nice to have kind of the fruits of that, uh, start to, start to be used by the people that you’re building it for.
00:02:16 Nathan Lambert: Yeah, I would say, like, the realistic question: do you think this is landing in the ballpark of the models in the last six months? Like, that has to be what you shop for, is there’s a high bar- ... of open models out there and, like, on what you’re targeting. Do you feel like these hit these, and somebody that’s familiar, or like MiniMax is, like, two thirty total, something less. I, I don’t know what it is. It’s like ten to twenty B active, probably. Um, you have DeepSeeks in the six hundred range, and then you have Kimi at the one trillion range. So this is still, like, actually on the smaller side of some of the big MoEs- ... that people know, which is, like, freaking crazy, especially you said 13B active. It’s, like- ... very high on the sparsity side. So I don’t actually know how you think about comparing it among those. I was realizing that MiniMax is smaller, doing some data analysis. So I think that it’s like, actually, the comparison might be a little bit too forced, where you just have to make something that is good and figure out if people use it.
00:03:06 Lucas Atkins: Yeah, I mean, if, if from raw compute, we’re, we’re roughly in the middle of MiniMax and then GLM 4.5, as far as, like, size. Right, GLM’s, like, three eighty, I believe, and, and thirty-four active. Um, so it-- you know, we go a little bit higher on the total, but we, we cut the, uh, the active in half. Um, it was definitely tricky when we decided we wanted to do this. Again, it was July when... It, it was July when we released, uh, the dense model, and then we immediately knew we wanted to kind of go, go for a really big one, and the, the tricky thing with that is knowing that it’s gonna take six months. You, you can’t really be tr-- you can’t be building the model to be competitive when you started designing it, because, you know, that, obviously, a lot happens in this industry in six months. So, um, when we threw out pre-training and, and a lot of our targets were the GLM 4.5 base model, um, because 4.6 and 4.7 have been, you know, post-training on top of that. Um, and, like, in performance-wise, it’s well within where we want it to be. Um, it’s gonna be... Technically, we’re calling it Trinity Large Preview because we just have a whole month of extra RL that we want to do. Um- But-
00:04:29 Nathan Lambert: I’ve been, I’ve been there.
00:04:31 Lucas Atkins: Yeah, yeah. But i- you know, we’re, we’re in the, um, you know, mid-eighties on AIME 2025, uh, GPQA Diamonds, uh, seventy-five, um, at least with the checkpoint we’re working with right now. We’re still doing more RL on it, but, um, you know, MMLU Pro, uh, eighty-two. So we’re, we’re, we’re happy. We’re really-- Like, for it being our first big run, like, just getting it trained was, was an extreme accomplishment, but then for it to actually be, like, a, a genuinely useful model is a, a cherry on top.
00:05:03 Nathan Lambert: Yeah, let’s go big picture. Uh, like, let’s recap. We have all of the... We have this full trinity of models. I think that there’s a fun note. Uh, did I put it in this doc? Yeah, on Nano Preview, which was the smallest- ... you’re, like, charming and unstable. The model card’s really funny. Um, ChatGPT, doing deep research on this, I was like, ChatGPT Pro just tagged next to it, “charming and unstable.” And I was like: Is this a hallucination? And then in the model card, you have, like: “This is a chat-tuned model with a delightful personality and charm we think users will love. Uh, we think- ... it’s pushing the boundaries, eight hundred million, um, active parameter, and as such, may be unstable in certain use cases.” This is at the smallest scale- ... which is like, I appreciate saying it as it is, and that’ll come up multiple times in the conversation. And then you have Mini, which is like, um, I think it was, like, 1B active, 6B total type thing. In my-- I, I don’t have it, the numbers right in front of me. I have it somewhere else. Um-
00:05:52 Lucas Atkins: Yeah, Nano was, Nano was the 6B, uh, 1 active.
00:05:55 Nathan Lambert: Oh, yeah, yeah.
00:05:55 Lucas Atkins: And then, and the Mini was twenty-six, 3B active.
00:05:58 Nathan Lambert: Yeah. So, like-
00:06:00 Lucas Atkins: Um, yeah.
00:06:00 Nathan Lambert: -are these based on more of, like, you need to build out your training chops, or are you trying to fill needs that you’ve-... heard from community, and like, I think for context, previously, your first open model was a base and post-trained model, which was Arcee 4.5B, which was a dense model- -which people like. And prior to that, you had, like, a long list of, like, post-training fine tunes that you had released. So before that, it was like a post-training shop, and I think that kind of history is i- important to fill in, ‘cause I think most people-- a lot of people are gonna meet you for the first time listening to this.
00:06:34 Lucas Atkins: Yeah, it, it, um, we chose those sizes for Mini and Nano, uh, specifically Mini, um, the 26B, 3B Active, because we wanted to de-risk, uh, large. Like, th- this has all been in service of getting to a model of, of, you know, the 400B class. So, um, we, you know, learned from doing the original 4.5B, that you might have everything on paper that you need to train a model, but i- inevitably, there’s tremendous, you know, difficulties that come up, and, um, it, it’s-- we, we definitely knew we wanted to make sure that we, you know, solved some of... E- especially when it came to just doing an MoE model performance, uh, you know, like a, like an efficient, fast train of an MoE. So, um, we thought that that was a good ground where we could, you know, it wasn’t crazy expensive, uh, but gave us a lot of data, uh, going into large. And then Nano just came about because we had some extra compute time, and we really want to do more research on, like, smaller models that are very deep. Um, and we hadn’t really seen that in an MoE before, so that one was very much we started training it, and then it, you know, early benchmarks were good, so we said, “Well, we’ll just do the whole dataset.” Um, and, uh, but most of the love for those releases went into, to Mini. So I, I definitely think that long term, uh, from an ROI perspective, the smaller models are going to be where we shine, just because there’s a tremendous amount of, of cost savings a company can get from, from optimizing on a, on a smaller model. Um, but, but we, uh, w- we’re definitely gonna be trying to push the, the large frontier, too.
00:08:26 Nathan Lambert: Yeah. Um, I’d like to kind of double-click on training before going back to the small model that’s useful for companies, ‘cause we’re gonna have-- we’re gonna end up talking for, like, twenty minutes plus about open ecosystem. So I kind of am curious, like, philosophically, how your company feels about, like, sharing scientific details. So if I ask you, like, what are the things you’re technically most excited about in the model, or, like, what are the pain points? Like, uh, like, are you willing to talk about these things? Like, I- Do you feel like it’s kind of orthogonal to the company? Like, I feel like a lot of it is just, like, things that happen. I think your framing of all of this is in service of getting the big model going. And particularly, of, like, you have to be thinking about your model as landing in six months, is probably... Like, for people not training models, it’s hard to think about, ‘cause even I- ... like, I’m thinking about trying to refresh our post-training stack for OLMo 3, and I’m like, the thinking model, the, um, we are pretty SFT heavy right now, and it makes it not very dynamic in terms of the thinking time. But it’s just like, I can’t see people deploying this model, or probably will have a hard time fine-tuning it. And it’s like to think about where tool use models are going in six months, like, seems pretty hard. Um, it’s a very hard task to do, so it takes a lot of gumption to actually set out and do it. So I, I would just appreciate the framing, kind of self-reflecting on what I go through. So if you have anything that you think was, like, particularly hard to actually land the six-month outlook, because you use Muon as an optimizer, or is it Muon? And some of these things. I think the data, it’s well known that Datology is cranking a lot of this, and you probably provide-- I think of it as like you’re kind of driving and working with these partners, and I’m sure you provide a lot of feedback on what’s working and what’s not. So- ... anything you’re willing to share, I think it’s useful.
00:10:08 Lucas Atkins: Uh, I, I think, um, I mean, on the data side, like Datology, I-- at least for these models, that, that partnership has very much been almost an extension of our own research team. Like, we’ve worked very closely with them, and, um, obviously, our model’s doing well, you know, i- is, is, is good for them. So, um, but it, it-- there was definitely, you know, and you know this better than most, like, small-scale ablations, when you throw them at scale, sometimes, you know, uh, the-- i- it doesn’t always turn out how you want. So there was quite a lot of iterating there to at least get the dataset we used for Large. Um, I, I would say that as far as looking out six months and then figuring out how we wanted to... Obviously, the big one was compute. We don’t, um, you know, we, we never raised as, like, a foundation model company, so we’ve ne- we haven’t signed massive commits for, you know, thousands of GPUs before. Um, we didn’t have a, a, a massive cluster that was always active, uh, for a lot of our post-training. So if they came before, um, you know, we had sixty-four, uh, H100s, that was pretty sufficient for that kind of work, but obviously, this necessitated quite a bit more. Um, but the first thing was-
00:11:29 Nathan Lambert: That’s still less than people would guess. Like, you’re releasing models- ... that weren’t like, your models weren’t catching national news, but people in the community knew about them. And, like, uh, i- I think of, like, Moondream when I think about that. Like, vik has- ... such little compute, and he puts it to so use. Like, you, like, see how successful he is? And he tells you that he has, I don’t know, thirty... Like, l- it might be, like, sixty-four GPUs. Like, uh- ... there’s, uh, uh, that’s a whole separate conversation on building- ... actual good ML output on little compute. I, I should ta- I should chat with vik about this, but aside
00:12:03 Lucas Atkins: No, it’s, it is-- I think it was... Yeah, it, it, it was very much a gift going into the pre-training side because-... we were kind of already thinking, All right, how do we do the mu- you know, the most with the, the least amount of compute? But, um, you know, we-- it took us quite a while to get the cluster that we have been training large on, which is twenty-two thousand forty-eight B300s. Um, and once we figured out when we were going to get that, get access to that cluster, everything else kind of became clear as far as, like, timelines for Mini and Nano and, and when we wanted to do that. Uh, obviously, you know, five hundred and twelve H100s was easier to come across, um, for Mini and Nano. So once we figured that out, um, it really became, uh, this game of, okay, how can we find, like, the best research on the topic of, of pre-training, and what is kind of... What are the, the, the papers and publications that are coming out, um, that have enough potential and enough precedence, either because, uh, another lab used them, it comes from a reputable team, uh, the ablations and the, the evaluation setup, like in the paper, was sufficient enough to give us confidence. Uh, and then we basically spent, I don’t know, it was probably about two months just figuring out what we wanted our architecture to be for the MoE, then figuring out, okay, now that that’s what we want to do, how do we implement all of that in the actual training pipeline? Uh, how can we-- you know, at that time, there had been many people who’d done Muon, but, um, for post-training, and, and then other-- some Chinese labs had used it, but there wasn’t, like, a widely available distributed Muon, um, to do it that scale.
00:13:54 Nathan Lambert: What do you think that, like, looks like in decision-making? ‘Cause that seems like a risky decision, if you ask me. I think for one, the ti-
00:14:00 Lucas Atkins: Muon?
00:14:00 Nathan Lambert: ... the timing, the, the, like, timing sharing that you’re saying is good. Like, you said this for two months, and then, like... But, like, even Muon is like, that’s a bet that would even take-- like, somewhere like AI2, that would take some serious evidence to go with it. We would want to ablate it. So like- ... on a single track, it’s like y- you had probably had a process for becoming fairly confident in it then.
00:14:24 Lucas Atkins: It- yes, but it, it was also, like, Kimi had, had just come out, and we knew that that one used Muon, and so we knew that it, at least, if implemented correctly, could deliver a good model. There weren’t outstanding ablations done around like... You know, there wasn’t a Kimi scale model done with Adam, and then compared to Muon and see the difference. But, um, that at least gave us enough confidence that if-
00:14:50 Nathan Lambert: What does Muon give you? Does it give you, like, memory saving, uh, in-
00:14:55 Lucas Atkins: No, it’s actually a little bit more memory. It’s, it’s, it’s mostly-
00:14:58 Varun Singh: It’s, uh-
00:14:58 Lucas Atkins: ... like the loss converges a bit quicker.
00:15:00 Varun Singh: It’s, it’s less memory, actually. It’s, uh, uh, only one momentum buffer instead of Adam’s two, uh, beta buffers, and then it’s also better convergence.
00:15:10 Nathan Lambert: Okay. So it’s, like, mostly designed around convergence, and then I know the math is different, which is where this momentum term changes.
00:15:15 Lucas Atkins: Well, it, it kind of came out... I mean, it had its, its, its big, you know, uh, explosion of popularity in the kind of nanoGPT speedrunning community. So it was kind of all built around converging to a certain, you know, validation loss faster, and, uh, that, that, that was, um... As for why we chose it as opposed to Adam, we’d used Adam for 4.5b, uh, but we also knew that if we wanted to move this fast, that we were going to have to make some pretty big bets, educated. Um, but, but still, we would have to make some, some, some risky decisions, um, beyond just, you know, training in general. So, um, there were a few that Muon we went with, uh, I think was, was one of our bigger bets. Uh, we ended up not doing, like, multi-token prediction or, or, or FP8 because we were throwing so many new things into the run at once, um, that-
00:16:12 Nathan Lambert: Do these apply for-
00:16:12 Lucas Atkins: ... if something were to go wrong-
00:16:13 Nathan Lambert: um, Mini and Nano? Are those also Muon, or are those- ... Adam as well? Okay, so then you- ... you get some de-risk from that. Do you know off the top of your head how many days it take to train each of those? Like, a, a good-
00:16:25 Lucas Atkins: Uh-
00:16:25 Nathan Lambert: ... ballpark for people, before-
00:16:27 Lucas Atkins: Yeah, so-
00:16:28 Nathan Lambert: going into the bigger run.
00:16:29 Lucas Atkins: So, so Mini, uh, so Nano on it was five hundred and twelve H200s, uh, took a little over thirty days. Um, and then Mini was about forty-five days.
00:16:45 Nathan Lambert: Okay. I think another thing- ... off the top of my head is I know that, like, a OLMo 1B dense would take us, like, eleven days on a hundred and twenty-eight H100s for a dense model. So, like, sixteen. So, like, the numbers- ... just go up from there. ‘Cause then it’s like the question is like, I’m guessing i- if those are forty-five days, and then you have-- you up the number of GPUs, it’s gonna be like a similar amount of time, or forty days for the big model, but much more stressful.
00:17:16 Lucas Atkins: Yeah, the big model was... But again, that was- we knew that we, we wanted- we felt confident that we could deliver a competitive and exciting model in January 2026. Like, we knew that it would-- we could... Who knows kind of where the research and what, what class and, and, and, and skill and performance of model is gonna come out in the next three months? Um, so we also knew that we really wanted to land sometime in January, and that’s also why we also took- we went with B300s, even though definitely the largest public train of that size on B300s and, and the, um, you know, a lot of the software was not-- did not have, like, out-of-the-box B300 support. It was the only way we were gonna be able to train a model of this size in-
00:18:06 Nathan Lambert: Did you have to do this? Did you have to implement the... like, help solve version issues or other issues on B300s? ‘Cause I’ve heard that-
00:18:13 Lucas Atkins: W-
00:18:14 Nathan Lambert: ... the rollout has been rough.
00:18:16 Lucas Atkins: We had to add-... a, a bit. There, there were a couple days where the, the data center had to take it offline to implement some bug fixes. It was, it was definitely, like, a very cool experience being on the bleeding edge, but, um, also, like, a little frightening ‘cause you just know, like, “Oh, we’re not getting the most out of these that we possibly could.” So, um, a little bit of both.
00:18:40 Nathan Lambert: Uh, was your final training run stable, or did you have to do interventions through it?
00:18:46 Lucas Atkins: Uh, it was very stable, actually. Uh, it took-- the beginning of it was not. The, the, the first ten days were absolute, um... It, it would start very well and, and looked, you know, uh, the dynamics and the logs, and the graphs looked very similar to Mini and Nano, and then after, uh, around a trillion tokens, it- the- we- you know, you’d get collapsing, experts would start to go crazy. Uh, part of this is just, again, we are very sparse compared to what you, you, you have. So, um, you know, four hundred billion total, um, thirteen billion active, two hundred and fifty six experts. Like, it was, it was-
00:19:26 Nathan Lambert: Did you do a, uh, expert routing loss or some sort of balancing loss?
00:19:30 Lucas Atkins: Yeah. Yeah, yeah. Yeah.
00:19:32 Varun Singh: We did, um, we used DeepSeek’s, uh... We, we modified DeepSeek’s Auxiliary-loss-free, um, uh, loss balancing with our own, like, uh, with some tweaks, and then we also added a sequence loss like they, uh, did as well.
00:19:47 Nathan Lambert: Uh, was there Auxiliary-loss-free one from DeepSeek V3, or was that a later model?
00:19:51 Varun Singh: That was V3.
00:19:52 Lucas Atkins: It was V3.
00:19:52 Varun Singh: They did a separate paper on it as well. Yeah.
00:19:55 Nathan Lambert: Yeah. Yeah, that makes sense. I think a lot of people have derived from there. Um, have you- ... had issues on post-training as well? So I have a theory that the new algorithms we’re getting from the Chinese labs, like GSPO and SysPO, are primarily for problems that you solve when you have big MoEs and you have expert problems when trying to do the RL. And that’s the whole reason that, like, I think our very serious AI two RL setup, like, we’re doing it on dense models, and we’re just like, “It’s fine. We don’t have this big clipping problem, and as much like we don’t have as much of a need to get the batch size as big to ac- activate all the experts.” So you’re saying you have so many experts and so much sparsity, that potentially sounds like you’re making RL harder.
00:20:36 Lucas Atkins: Um, yes. I will also... I will say that from just, like, a purely post-training side, we added as much as we po- we used- we... So our code base started from TorchTitan. We’ve had to make a ton of modifications to it to get it where we need it to be, but that was an excellent base. And from one of the bigger learnings from Mini and Nano was treating, uh, at least the SFT side of it, as a s- as a separate phase. Um, ‘cause with, with Mini and Nano, we finished the pre-training, we did context extension, then we took those and then ran those on, like, the sixty-four H100s we usually would do post-training on. Um, that presented a lot of challenges, uh, with the MoEs. They, they really... And that’s kind of been a thing in the open space, is post-training MoEs, like, really, um, can be frustrating, even for SFT. So for Large, we added, uh, like, fine-tuning directly to TorchTitan, um, and did it all on the same cluster. So, um, from a performance standpoint, like, SFT was very, um... actually ended up being totally different.
00:21:42 Nathan Lambert: What is the actual difference between the q- the, the implementations then? Is it just kinda like you end up with different batch sizes and parallelism and stuff? Like why-
00:21:50 Lucas Atkins: Uh, I mean, we ended up, we... Yeah, we ended up needing to get it to do really, like, to get context parallelism really well, really good, ‘cause we’re obviously going at a higher sequence length, and then, um, just adding the proper loss masking. Um, it, it, it, it ended up being a relatively easy implementation, especially ‘cause we did all the pre-processing, uh, outside of TorchTitan.
00:22:13 Nathan Lambert: Interesting.
00:22:14 Lucas Atkins: Uh, and then on the RL side, yes, I would say it’s not, um, it didn’t present itself as, as, as significantly harder than, than, um, Mini and Nano. However, that many GPUs does, so we didn’t end up using, uh, two thousand of the B300s for that. That ended up being, uh, a thousand. So two, we just split the nodes in half.
00:22:39 Nathan Lambert: Yeah. That makes sense.
00:22:40 Varun Singh: On the dense model side of things, uh, you mentioned that you didn’t need to use all the tricks and stuff. I, I think it is, uh... I think the, the, it- MoEs are just, in general, harder to RL, but I think it’s also, like, uh, b- because of, like, the KL mismatch between trainer and inference engine, right? Um, where you have, like, uh, sometimes the inference engine can pick different experts compared to, like, the trainer, uh, when you, like, do a forward pass on the same tokens. So I think there is definitely some, like, inherent instability with, with RL on MoEs.
00:23:13 Nathan Lambert: Yeah, that makes sense. Are, are... Okay, um, another question of, like, how much do you want to say? How do you feel about the state of public post-training recipes? Like, do you... Like, I, I feel like there’s so little out there, and there’s an opportunity to be seen as technical leaders by sharing just, like, more of what you’re doing. ‘Cause I feel like we’ve seen for years how complicated things can be, but also at, kind of at the same time... Like, we see this from the likes of Llama, has these really complicated recipes. But at the same time, I feel like just executing on a simpler recipe can get pretty close. But it’s just, like, very uns- I feel, uh, currently unsatisfied with how much I know about what are the actual core trade-offs of doing post-training well. And I think you could do a lot with SFT, but there’s definitely, in this RL regime, more trepidation of kind of narrowing your model to either downstream use or, like, being able to do this multi-week RL run where you get the most performance.
00:24:06 Lucas Atkins: Yeah, I mean, I, I, from-- since RL has become such a pivotal part of the process beyond what, you know, DPO and, and, uh, and kind of your, your typical RLHF was in the past, like, we used to get quite, uh-... sophisticated with, with how we would do SFT and, and even our, our RL. We, we obviously, we make MergeKit, so we, we utilized merging, and we used to do a lot of distillation, um, to eke out as much performance as we could. Now that RL is such a massive part of the entire post-training stack, I, I have almost reverted us to just really solid but simple SFT. Um, like in, in large, I mean, we’ve-- our post-training data set for, uh, Trinity Large is, uh, two hundred and thirty billion tokens. Like, like, it just like a really, really, really large-
00:25:09 Nathan Lambert: That’s ten X what we did. At least in SFT.
00:25:10 Lucas Atkins: And even that-- and even, even your tenant, like that was bef- before this kind of w- going at this scale and even kinda thinking and, and reasoning models. Like our largest SFT before that was five billion to-- we’d do, like, three epochs, but it was like five billion, you know, tokens, so- Um-
00:25:28 Nathan Lambert: Our non-reasoning model is, like, te- another ten X. So, like, our most latest instruct model is, like, two billion.
00:25:34 Lucas Atkins: Yeah, which is, uh, already a lot, you know. So, um, I, I’ve definitely... We-- you know, simplicity’s key because it also makes debugging anything easier, and then, um, devoting a lot of that sophistication to the RL. Our RL part is, like, really important. I do think that, I mean, the next, uh, phase of reinforcement learning for models of this scale is, is just scale. Is, is... Okay, we went from, you know, twenty billion SFT to two hundred and thirty, now we’re going from, you know, ten environments to a hundred. I think that that really is where you’re gonna get the biggest benefit. I also think that’s why, you know, MiniMax and, and, and other players like GLM are so performant and just, like, have that extra bit of, of usefulness that goes beyond just what you see in the benchmarks, is they’ve, they’ve really embraced, like, long-form, uh, RL. And, and so, um, yeah, I mean, to be quite frank, our, our RL pipeline’s rather... immature might be the wrong word. Like, it’s, it’s, uh, there’s definitely a lot more work we could do and a lot more work we need to do, but, um-
00:26:43 Nathan Lambert: Have you started the tool use side of RL?
00:26:46 Lucas Atkins: That-
00:26:46 Nathan Lambert: Or are you mostly... Well, um, beyond like, if you’re training on code, just verifying the code answer, I don’t count yet as tool use. I would say, like, search and code integrated reasoning is what I think is gonna be like minimum table stakes, but do it- to do it well is really hard. Like, we have to, like- ... like, you, you really, like, uh... That’s what I want to do. I want all of our models to have that this year. Search is prob- you have to have, like, a partner to do search or just, like, illegally scrape Google if you’re gonna- ... you’re gonna serve this model onto a customer, and it’s gonna- ... what? Go, go to Google, like, what?
00:27:16 Lucas Atkins: Yeah. Yeah, no, I mean, I, I... Beyond, like, like, really kind of like long-form, like deep research or, um, you know, even like GPT-OSS style or, or G- GPT 5 style, where, you know, it’s doing a hundred tool calls before it gives you a response. Not there yet, um, but that is kind of... Once we get past the, the final kind of RL of Trinity Large, and, and we kinda look at where we go next, like, that is the next major hurdle, um, for sure, and it’s intimidating.
00:27:56 Nathan Lambert: How big is your, your team of- of... Like, how many people are spending the majority of their time on the model? And then I think we c- start to wrap up technical talk and zoom out a bit to ecosystem and company strategy.
00:28:09 Lucas Atkins: Uh, there’s thirteen at Arcee- ... that are just, like, every, every single day is working on it. Yeah.
00:28:16 Nathan Lambert: And I guess that’s a good number because these people are talking about data, but there’s also, like, the whole data thing that’s coming somewhere else. But also somebody else that wanted to pre-train a model, like they could just download the best fully open data set. And I don’t think it’s gonna be quite as good, particularly in the fact that, um, like, if you look at OLMo’s models, we don’t have a lot of tokens, so we need to, like, acquire- ... more tokens in the open still. But to, like, get a number of thirteen, where some are spending a bit of time on data, but there’s the whole data abstraction, is actually kind of nice for somebody that’s like... To do a serious modeling effort, you need to have this many people, I think.
00:28:50 Lucas Atkins: It, it was-
00:28:51 Nathan Lambert: It’s reasonable to me.
00:28:52 Lucas Atkins: It was, it was a good number. I mean, I would say that, um, it, it was helpful to be able to, you know... This was like, how do we alleviate as many concerns as possible? Or how do we check off as many boxes, right? And it’s like, if we’re trying to do this in the shortest possible amount of time, like, we need to focus on what we’re good at, which is we- pretty good at post-training, and how do we get to the point where we’re able to do that? Well, we have to have a pretty strong base model. How do we get a strong base model? We’ll-- we have to, you know, figure out how to do it, perform, you know, efficiently across many, many GPUs, and then data’s, you know, extremely important, so getting a partner that could, you know, help us with that, and we could offload some of that. It, it- there ended up being, obviously, as you, you know, alluded to earlier, like, a lot of, uh, working with Datology and, and, and others to make sure that the data accomplished what we needed it to. Um, I think that that is gonna be an interesting... You know, as we, as we- now that we have Large and we’re looking at, you know, kind of going further, it’s like, okay, you know, the, the pre-training data really has to be in service of what you wanna do in the post-training, uh, work.
00:30:10 Nathan Lambert: How did you identify this?
00:30:11 Lucas Atkins: Like, like-
00:30:11 Nathan Lambert: Like, like- ... did, did you identify this through Mini and Nano, or, like, how’d you come to think that this was so important?
00:30:19 Lucas Atkins: Data in general or, or just-
00:30:20 Nathan Lambert: Or like this in form of post-training
00:30:21 Lucas Atkins: ... of optimizing it for the post-training? Um, I- really ob- observing other, other players, I think. I mean, it’s, it’s... You know, the, the true base model has kinda stopped really being a thing.... around Qwen2, but definitely around Qwen 2.5, um, where you started to see how much post-training data was making its way into the, the, the base models themselves. Um, and then you start to see the models that have done that, how malleable they are with RL, Qwen 2.5, Qwen3 being a good example. And you start to see like, oh, yeah, like they are, uh, doing as much in the last probably thirty percent of training to make it so that when they go to do RL or post-training, they’re gonna have a really good time. Um, you know, they’re just complete-- they’re way easier, way more malleable, way more performant than what you had in Llama 2 or Mistral 7B. So, um, I knew that i-in-intuitively, kind of going into this, but it wasn’t until after Mini and Nano, yeah, where, where we kind of... Well, definitely 4.5B, where we were like, “Yeah, we definitely need to juice our mid-training quite a bit.”
00:31:31 Nathan Lambert: Yeah, I agree. Okay, this was fun. We could- we’ll probably revisit themes from this. I think that, um, I can definitely go over time and keep chatting because I’m enjoying this. And for context, Mark and I had coffee at some point when I was at some conference in SF, and I was like: Damn straight, this is a fun bet that you’re making. So I’m trying to recapture as much of this as you can. Um, for context, it’s like in July, which is similar to when you decided to start this model, which is when, like, Qwen Coder came out, Kimi came out, um- ... GLM 4.5 came out, and I was just, like, looking- and Llama had kind of been, like, become a meme of going away. And that’s why I launched the Adam Project, where I was like: Come on, we need to have some people doing this. And I think that it’s, like, hard in the US because I think there’s so much money to be made on AI. Like, the company- the big tech companies are like: “We see it, and we’re gonna take it, so I don’t need to bother with, like, caring about open models ‘cause we don’t need it.” But from, like, an ecosystem co- perspective and a long-term tech perspective, I don’t think that works very well for the country. So it’s kind of this weird middle ground of like, how do you convince people to actually build open models? I was on... Like, I have calls with people in government asking me, like, what would I actually do? So it’s, like, very hard to think about this. And I have this- and then it’s just, like, to hear that you guys are just making this bet on this is very fun to me, but it’s also, like, based on actual learning from trying to do this. So you’ve been trying to train open models. I think Mark and I have both been at Hugging Face in our past, and you’re, you were trying to sell people on using open models, and there is a market for this, but it wasn’t enough to not have the base models. So I think, like, talking about your experience in selling on-prem open models and why you needed to train your own end-to-end, and why you needed to train bigger, is great because I hope there are more stories like this, and it kind of fills a void and inspires people to work in it. So how- however you want to take this prompt.
00:33:24 Mark McQuade: Yeah, I can jump in. Um, I mean, yeah, I mean, wh- when I started Arcee in 2023, right, uh, it was... All we did was post-training. Uh, and we worked with, uh, a lot of large organizations and did model customization, you know, for their use case on their data. Um, and we were using Llama-based models, Mistral-based models, and then, you know, some Qwen. I don’t even know if we actually did much Qwen, right, Lukas, at that time, but-
00:33:54 Lucas Atkins: No, we did. Yeah, we, we- Later on, but and then-
00:33:56 Mark McQuade: Later on, right? Uh-
00:33:57 Lucas Atkins: We did, and then we ended up not, because after a lot of Chinese models started to come out, then the companies didn’t wanna use Chinese models, so then we kind of went... Yeah, it was kind of just tricky.
00:34:08 Mark McQuade: Yeah, and people don’t realize that that’s real.
00:34:10 Nathan Lambert: People don’t realize that that actually happened.
00:34:13 Mark McQuade: Yeah, no, that’s, that’s a real thing. That’s why we, we started going down to pre-training was because, well, you know, Meta did their thing and kind of got out of it, right? So there was the, the main US player got out of it, and, and we were working with a lot of US-based enterprises that were not comfortable using Chinese-based architectures. And if you wanted to use the best open models of the day, it started to really trend towards, you know, the Chinese labs. Um, and to the point where we are now, where it’s like, you know, ninety-plus percent of the top mo- open models are coming out of China, um-
00:34:47 Nathan Lambert: Yeah, like, Cursor’s building on it and stuff. Like, people are building on these things.
00:34:52 Mark McQuade: Yeah. So, um, we said, “Okay, let’s...” Instead of we were so reliant on the Metas of the world, the Mistrals of the world, and Mistral largely stopped open sourcing, uh, you know, fully. So we said: You know what? We’ll just go down the stack, and we feel we’re capable enough to, to, to train our own models from scratch, and then we control the, you know, the stack. We can, you know, we, we control the core of, of... as opposed to relying on others to release great models. And, um, and then during this time, you know, it just happened to be that, um, you know, there wasn’t a tremendous amount of US companies doing it. So, um, from our perspective, it was kind of a, a win-win, in that we were able to own more of the stack by going down to pre-training and creating our own models, as well as we were entering into a, like, a space that there wasn’t a tremendous amount of competition, to be honest. Um, and, you know, I-- Lukas and I had said this yesterday, I, you know, I think as a startup, every startup doesn’t want to directly compete with, you know, X or OpenAI, or Anthropic, or Google because they have more money than God, and they can do whatever they want. Um, but when you’re doing open weights, you don’t-- it’s, it’s a different kind of compe- they, they don’t sit in there, right? You’re kind of going into your own path, where there isn’t a tremendous amount of players, and you can kind of find your, your way and, and build your niche and, and kind of go from there and, and become something big. So, um, it kind of happened to all coincide for us back in, in July, and, and we went all in.
00:36:23 Nathan Lambert: Yeah, yeah, like, uh, the, the all-in thing is real because this is expensive. I think that- ... I could dig up in my research the cost of daily, um, twenty-four T8 B300. So I think I’ve seen this type of cost at AI too, where we have long rentals, and we’re like: I know exactly how much this costs, and it’s like, it’s not cheap. Are you... A, a way to transition this is like-... do you see the demand? Like, you were selling open models, like, does this kind of be continuous, where people are like: “You helped us deploy this model, but it’s not good enough.” Like, is, is that something that’s happening, and you’re like: “Well, we have this, and we can help you do it coming in this time?” Or is it like you need to build it... It’s like, is it a we will build it, and they will come type of situation? Like, how much- ... continuity is there in this?
00:37:17 Mark McQuade: Yeah, I think it’s largely-
00:37:19 Nathan Lambert: I-
00:37:19 Mark McQuade: I, uh, from my perspective, I think it’s largely if you build it, they will come. Because we stopped, you know, focusing on that whole revenue generation side of the house when we started to go all in on being this, you know, frontier lab in the open source side. So, um, there’s a couple pieces to that, that, that I think we should all be very proud of inside of Arcee, is that we not only went all in by committing a significant amount of capital. Like, we, we committed, you know, sixty-five, seventy percent of our capital to these models, which is a large amount for a startup. I mean, we didn’t... So that’s not like a dip your toe in, that’s like, we’re all the way in.
00:37:55 Nathan Lambert: Yep.
00:37:55 Mark McQuade: Um, but we did that at the same time as abandoning essentially the whole revenue angle to go all in on it, because we couldn’t focus on both. So we said, “We know how to make revenue on open models. We’ve been doing it for two years. Now, let’s take a step back, because it wasn’t, uh, in a repeatable or sustainable way that we h- the way we had that business set up. Let’s take a step back, let’s build these models from scratch, let’s come up with the, the Trinity family, then let’s go back to generating the revenue side of the house and the monetization piece,” which I think we are in a good position to capitalize on even more now, but we, we took a... We, we, we kind of walked away from it to do what we’re doing here.
00:38:36 Nathan Lambert: Yeah, I love this.
00:38:36 Lucas Atkins: Yeah, I mean, when you have... When there’s only, like, thirteen, you know, uh, researchers who would... Well, we’re, we’re doing obviously our own products and own models, but when you’re working with customers, like, inevitably, those are the same people that need to help train those models for customers, and we got to a point where we were really beginning to, like, do mini and nano. We were getting down to, like, the start date of the cluster, where, um, having myself or Mark, or even, you know, Varun and others, like, pulled into customer or, or, or, uh, conversations or contracts, like, it was not-- we would not be where we are if we had continued, you have know, working with, you know, ten customers at once. So-
00:39:19 Nathan Lambert: But-
00:39:19 Lucas Atkins: ... we, we scaled that down pretty drastically. I do think that when... You know, Mark and I put a lot of thought into, “Okay, well, we’re gonna spend all this money to train these models, like, you know, w- how do we not...” I think, uh, one of the things that makes the idea of, of going all in on training open weight models hard, is that you’ve seen other people try it. And, and like M-
00:39:42 Nathan Lambert: Um, like, like do you think Meta or do you think Meta or Mistral went all in?
00:39:46 Lucas Atkins: I, I think, well-
00:39:48 Nathan Lambert: Meta obviously did.
00:39:48 Lucas Atkins: I think they, they both... Yeah. I think, I think that when I say all in, I mean more like Mistral was, was one of the core ones I’m thinking of, where- ... they were a venture-backed company that, like, had a, a, a fiduciary responsibility to bring in money, but were also trying to release open weight models, uh, for, you know, the West, and for their communities, and for the world. And, um, they tried doing closed versions, and then monetizing off of that. They, they also kind of have more recently, luckily, for all of us, gotten back to their kind of Apache 2.0 roots, and-
00:40:30 Nathan Lambert: Oh, my God.
00:40:30 Lucas Atkins: And-
00:40:30 Nathan Lambert: Have you seen the download numbers on Mistral 3 Large?
00:40:33 Lucas Atkins: I haven’t. No, what is it?
00:40:35 Nathan Lambert: Oh, s- no bueno, sir.
00:40:38 Lucas Atkins: Hey.
00:40:39 Nathan Lambert: Carrying on. Sorry.
00:40:41 Lucas Atkins: But, I mean, yeah, you know-
00:40:42 Nathan Lambert: Um, Mist- the, the Large Instruct model has downloads in the last month. I honestly don’t know what’s going on. Maybe there’s some, like, quantized version out there. I, I was confused.
00:40:50 Lucas Atkins: Maybe. Well, I mean, yeah. But I think that we-
00:40:52 Nathan Lambert: It’s, it’s hard to get adoption. The competition is insane.
00:40:55 Lucas Atkins: Hmm. Well, that’s, that’s- ... yeah, I mean, and that could be a whole conversation also, is, like, how do you actually get people to use it?
00:41:00 Nathan Lambert: I was gonna ask you, like, how do you get people... How do you get people to- - really sell into this? You said you’re good at it.
00:41:06 Lucas Atkins: Yeah, I think that the-
00:41:08 Nathan Lambert: Continue your point, we can come back to it.
00:41:11 Lucas Atkins: No, no, but they... I think they all kind of tie into it, is, is... We knew that the, the market was there for, for custom models. It was two years ago, frankly, and it’s even more so now, because RL has drastically, uh, increased the areas that you can hill climb and become really powerful with a tiny model. Um, and but, but also, people are beginning to see how powerful, you know, uh, te- uh, cust- or, or training in a, a, a product is. Like, you see Claude Code, you see Codex, you see, um... I think Deep Research was kind of one of the first ones that really kind of opened my eyes to what was possible, when you kind of are kind of training in the same environment that you’re serving your users. So we knew that, that people wanted it. We’d, we’d had good success with, with customers in the past using other people’s open models. So, um, it was less of a question of, like, could we monetize it, or will we? And it was just a matter of, um, could we get a model, you know, that pe- that, that we would feel that, you know, given a, a wide suite of basically being able to pick any model in the world, would, would our researchers and, and would our teams re- reach towards our own? And, uh, luckily, I think we’re there. Um, on, on the-
00:42:31 Nathan Lambert: Uh
00:42:31 Lucas Atkins: ... on the topic of, like, how do you get people to use it? How do you get adoption? You know, I’ve never wanted Trinity, uh, or our biggest advertising thing to be, like, US. You know-
00:42:45 Nathan Lambert: Yeah, I know
00:42:45 Lucas Atkins: ... like, if, if your entire-
00:42:47 Nathan Lambert: I know, man, it hurts me.
00:42:48 Lucas Atkins: Yeah, if your-
00:42:48 Nathan Lambert: I spent months reckoning with this.
00:42:50 Lucas Atkins: Yeah. If, if your entire, uh, you know, value prop is that you’re an American company-... great, but ultimately people are gonna use the best. Um, and so I think that we’re gonna be able to serve and, and the people like that need a US-based model because their compliance or legal teams won’t let them use something out of China, it’s gonna be a fantastic option. But I think, you know, kind of the next phase of what we’re doing as a company is, all right, now we’ve, we’ve proved to ourselves and maybe the, the wider industry that like we deserve to be in the conversation, and we can train models of this scale. Um, then it’s like, okay, how do we train the best one? Uh, ‘cause really, I mean, people’s loyalties are very fickle, and, and, yeah, you, you go to what’s the best. I guess it’s like, how much do you think
00:43:41 Nathan Lambert: you’ve learned about being able to tune a model narrowly by going and building the whole stack? Um, something we talk about is like ability- ... to specialize models, and I kind of, of opinion that you just make a better general model right now ‘cause the pace of progress is so high. And but the question is like, can we tune a OLMO that’s very good at science or something? And I- ... w-would guess that training the entire model, you’re going to be able to actually do a better job at what you were doing, but I don’t know how to articulate why or what that looks like.
00:44:18 Lucas Atkins: Um, I mean, the, the, the simplest answer to that being yes is just that... or the simplest reason why that’s the answer to the question is yes, is because we know what went into the model. Like, we know what it actually saw at the later stages of training during the decay. Um, and so that all- that helps influence, A, what are we tr- what kind of data and what topics and, and what format are we giving these models, uh, in post-training? But it also allows you to know like, okay, where, where do I absolutely wanna crank, you know, how, how many- how much of this, say, 230 billion dataset, do we want it to be math or, or, or, or coding? And a lot of that’s influenced by what you’re able to put in-
00:45:06 Nathan Lambert: How, how much of your post-training-
00:45:07 Lucas Atkins: ... post-training
00:45:07 Nathan Lambert: -do you expect to redo? Like, uh, how much can you say about when you’re serving something on-prem? Um, you- you’re not gonna redo the pre-training. You might, for a very big customer, redo mid-training or do continued pre-training- ... in which, in that case, you do need the pre-training data to keep, keep it being stable. Which is a use case where like I’m- I would love to see a paper that’s like, “Because of OLMO being open, we continued to pre-train on biology, and we mixed half of their exact mid-training dataset in with our dataset, and it, and it worked,” yadi, yadi. Like, you could obviously- ... do that, but how much do you think is gonna be like the standard, you fine-tune the last instruct model, or do- are you gonna have to retouch the post-training for a customer? Because that, like, I, I really feel like-
00:45:48 Lucas Atkins: Um
00:45:48 Nathan Lambert: ... it’s just at the end.
00:45:50 Lucas Atkins: It, I think, I think-
00:45:50 Nathan Lambert: But it would be fun if you had to change it.
00:45:52 Lucas Atkins: For the most part, um, I think a lot of tasks will be fine just starting from our, our, our, po- uh, like the released, you know, official post-trained version. Um, now, that’s for maybe simpler tasks, is the wrong way to frame it, but if it’s like, “Oh, hey, we’re doing a deep search agent. We want it to do 30 calls and, before...” That would be a good use for just starting with the finished model that we released that’s already post-trained. Now, if we’re going into something along the lines of, um, a very low-resource programming language or, um, something that it didn’t see a lot of in, in, in pre-training, um, or it’s kind of like a, you know, we’re wanting to train this thing to be really good at humanities last exam, but tools. Um, once we get into the world where we’re having to, especially... Actually, I have a much better answer to this question as I was thinking through it, but most of that holds the same. I think that the, the, the world where we’re gonna be doing a lot of extra instruct and, and SFT and, and post-training is gonna be when we’re trying to distill capabilities from large, like into mini or nano. So say like, oh, you know, this large is, is, is really great at invoice processing, but it’s also 400b, and the, you know, the company doesn’t wanna be hosting that on-prem, you know-
00:47:24 Nathan Lambert: Ah
00:47:24 Lucas Atkins: ... let’s go out generate a new one.
00:47:25 Nathan Lambert: Do you have costs off the top of your head for, like, what the hosting costs are for each of the model? Like, do people... Are people all gonna host these models in the same way, or is there actually-
00:47:32 Lucas Atkins: Uh
00:47:32 Nathan Lambert: ... a wide variance? And if you have, like, the same three models- ... do almost all of your customers end up hosting the same way, or do you end up doing a lot of, like, how do you configure the model to fit in the right hosting for them? Like, is that part of-
00:47:44 Lucas Atkins: It depends
00:47:44 Nathan Lambert: ... the business model?
00:47:45 Lucas Atkins: It, it, it, it kind of... And we tried to move a, a, a little bit further away from that because you get into the risk of being like, like a consultancy, and it’s- that becomes tricky, where there’s not a very clear separation of concern. But, um, for the mo- it would change depending on, were they using AWS? Did they have a commit with Azure? Um, if not, okay, then we, we can go to, you know, someone like Prime Intellect or Parasail and, and get a, you know, maybe a, a cheaper rack of eight. Uh, it just really depended. Uh, there’s quite a bit, um, of, of people that were also serving them, just using, like, Llama CPP. So, like, on CPU-
00:48:25 Nathan Lambert: Uh, is the 400b designed to be, to fit onto one rack of eight 80 big gigabytes in FP8? Is that how you designed it? ‘Cause Llama- ... Llama four, whatever, Llama 405b was the same. It was like one rack in FP8 works pretty well.
00:48:41 Lucas Atkins: It’ll do- we... well, you’ll be able to get really good throughput, a little bit lower concurrency on a, a rack of eight H100s at FP8, and then for, like, our, you know, what we’re serving, we’re serving them on, uh, a series of H200s, but we’re not doing, like, multi-node inference. Uh, but that’s just to add more, you know, replicas and- ... other kinds of things.
00:49:03 Nathan Lambert: Hopefully, eventually. I think that the-... Do you have anything else to say about selling open models? I think that generally, like, how do you think about the market for AI? ‘Cause I see the market as being so big, but the- with specifically with open models, it’s so hard to measure. I think I’ve started talking to some of the Chinese labs at all- as well, and I like to ask them, like, this is very US-centric and like Fortune 500 or whatever, and it’s just like, who the heck uses these models? I think- I guess another question is, like, what license or do you know the licenses you’re gonna use for the biggest models? And I think they’re, like, you’re, you’re playing with fire ‘cause people can use it for free, obviously, but potentially- ... you’ll get to hear like, “Oh, shit, somebody actually used our model for this.” And I think any successful business, you’re gonna want... You, you, you know that this model is not gonna be very relevant in a year with the pace of progress. So like- ... how do you think about your license decisions?
00:49:55 Lucas Atkins: Uh, we- you know, with the 4.5B, we tried to do like a, like a, a reve- one of those revenue-gated licensing. So it’s like, oh, it’s completely free for you to use for commercial and whatnot, but if you or your company made over, I think it was like $1.7 million last year, then you need to come to us and get a license. And what we ultimately found was like, it, it didn’t... Maybe for some people who are just only trying to train the model, release it on Hugging Face, and then just call it a day, maybe that is a huge requirement. But when so much of our, our, our company is built around, you know, training custom versions of the models, and, and not even just ours, but in general, even before we did pre-training. Like, at the end of the day, i- as long as we were using it, a- and we knew that we were in full control of, of whether- if we really succeed, it’s because we trained the models, we did them well, and we executed on it well. If we fail, it’s because we, uh, didn’t execute, instead of, oh, some company just stopped releasing good open models. Um, so we eventually switched to just Apache 2.0, and Trinity Large is also gonna be Apache 2.0. Um, you know, I’m- I think it is-
00:51:23 Nathan Lambert: I think this is the right approach. I have a big investor-
00:51:25 Lucas Atkins: Yeah, I think it-
00:51:25 Nathan Lambert: Without, without naming other companies, it’s easy- like, raising a lot of money, whe- or being Meta and releasing open models, and do it- and you could release it with non-commercial, and you could get all these, like... You could talk to, I don’t know, fucking Adobe, whoever. Oh, Adobe’s too big. They’ll have good AI. Some... I don’t know, a bank. Bank of America. You could run Llama on Bank of America and make good money on this. But I just feel like the cultural home of open source AI, and I don’t think- it’s impossible to know who wins it, and I don’t think that you’re in the prime position, and I don’t think that it’s easy to win, but you’re doing a thing that aligns with it. It’s the person that just, like, commits to building the models and learning how the ecosystem works, and to rebuild the models based on the feedback th- that you get from people, and to just kind of commit to an evolving process. And if the whole thing works out, there will be a lot of value, and the person who understands it best should be able to learn how to extract said value. And I think that I’m personally, like, sometimes frustrated with Hugging Face, ‘cause I feel like they have sat on that s- a sort of position like this, and they- ... haven’t figured it out. Not that it is easy to figure it out, but I think that has to be the ideal of open source AI, of like, if it’s really gonna work, that’s, that’s what I hope it looks like. And it’s like, I, I don’皮 know, maybe you guys could do some of that. Like, I have a question of like, could you figure out how to make models that are more fine-tunable- ... after all this post-training? Because you need to sell it to a- you need- ... you, you know the customer’s not gonna want it off the shelf. And I don’t know how to train to post-training to make sure that you don’t, you don’t cook it. Maybe you just learn that you need to warm up the model in a l- in the right way, and you just learn the technique of training downstream. But when you talk to people doing research, the different base models have such different characteristics. I think one of them is character training. I did this paper, and the guy was like: “Qwen and OLMo love their character,” and I’m like, “I have no idea why.” And but it’s like Llama and Gemma, you can change them so much. And I’m like, “Dog, like, please figure out why this is the case.” And for one thing, it’s really cool, but also, like, in your case, that would unlock a lot of value to be like, we know exactly what the model’s gonna do, and we know exactly how to change it. So.
00:53:35 Lucas Atkins: Yeah-
00:53:36 Nathan Lambert: Uh
00:53:36 Lucas Atkins: ... it, it, that’s- no, you’re, you’re, you’re right on the money. I think that even, uh, going into the post-training at large, we, uh, one of our researchers came out with, like, a pretty cool, um, experiment and ablation run that they did on drastically reducing catastrophic forgetting. And I almo- I mean, this was, like, three days before we were gonna start doing SFT, and then we ultimately just... I, I ended up pausing on it because it was just throwing something in that wasn’t tested. But, um, yeah, I think-
00:54:08 Nathan Lambert: A good research lead. You did the right thing.
00:54:10 Lucas Atkins: Yeah, I think, I think one of the most important things long term, you know, as we look at kind of what our research priorities are for this year is, is there’s obviously just how to scale RL and, and make these- the end result of the model as good in as many situations as possible. Um, but I think the other half of that is, you know, how do we make the, the, the speed and efficiency and, and performance of customizing them as, as fast as possible, and as easy as possible.
00:54:42 Nathan Lambert: Yeah. Do you learn in making open models from your experience just kind of running these open software things in MergeKit and DistillKit? I know there was a whole license journey on one of those as well.
00:54:52 Lucas Atkins: Yeah, DistillKit.
00:54:52 Nathan Lambert: Do you feel like they’re kind of isolated?
00:54:54 Lucas Atkins: Or MergeKit. Um, yeah, I mean, I think so. I think that, that, um, you kind of have to play the tape out. With MergeKit-... it was by far our most popular piece of software we’d ever released, but it was so popular because it took something that isn’t fundamentally very complicated, but we ma- but it’s time-consuming, and standardization is great for things like that, and we made it, uh, you know, streamlined and easy to do and fast, and you could experiment and ablate really quickly for, you know. And, and so I, I think that when we switched that to, like, a, you know, a, a similar, uh, revenue-based licensing, like, it, it didn’t end up having the value prop that was important because are you gonna pay Arcee, you know, thousands of dollars, or are you just gonna have one of your researchers-
00:55:52 Nathan Lambert: You’re gonna have clone code in a week, right?
00:55:52 Lucas Atkins: recreate it in a week, right? Yeah, so it’s-
00:55:55 Nathan Lambert: In a day.
00:55:55 Lucas Atkins: It’s, it’s kind of... It, it’s remi- it’s remembering like, okay, what is- what problem is this solving, and is this even a prob... Like, is the solution to this monetizable? Um, and so MergeGit, we brought it back to the original license, but I think with even viewing the models in the same way, it’s like it’s... Open source is an unbelievable marketing tactic. Like, there’s no one would care about Arcee if we weren’t open sourcing stuff, ‘cause as soon as you do something closed source, if you’re not the best or the cheapest for your price point, I mean, your performance point, no one’s gonna use it. Because-
00:56:30 Nathan Lambert: Um, another question on this. Um, do you think that open models are kind of at a disadvantage when progress is so high? Because it’s potentially easier to swap APIs than open model configurations, especially if, like, model weights are changing sizes or something like this. Where it’s like, “Oh, I can just upgrade to the new Opus, and I do this.” Like, does that, like, uh, decentivize people from using it? Or do you think most of the people are like: “I can only use open models, therefore, I’m gonna use open models?”
00:56:56 Lucas Atkins: Uh, I think for the people who are using, like, s- either self-hosted or, you know, um, uh, bespoke, uh, you know, engines to, to run it, where they have complete... You know, in a VPC or they have complete control over, like, data in and out, egress, ingress. I don’t think that’s really gonna be so much of a problem because they’re obviously doing it for a reason. Um, like, they’re either for privacy or security or, or HIPAA or SOC 2. For whatever reason they’re doing it, um, I, I don’t think that that’ll be, um, so much of a blocker, but I definitely do think that, um, you know, by far, e- even, even with some of the, the larger open... You know, like inference players, like Together and Fireworks, that, that host a lot of open models. Like, being feature- being on feature parity with a lot of these, these larger labs’ APIs is gonna be extremely important, um, o- of being able to serve, you know, um, with features that they’re used to, like prompt caching, that kind of stuff.
00:58:03 Nathan Lambert: Yeah, are- like, I, I think I saw that you guys are setting up an API as well. Is that kind of what the vision there is, is being able to o- offer parity at least, or, like, make it easy for people to consider it?
00:58:13 Lucas Atkins: I think so. I, I- we’re- we very... Yeah, we are doing our own API. We are hosting it. Um, we haven’t- we, we push a lot of that through Open Router just because it’s such a great place to get, like, discovered. Um, as... If we see, like, tremendous growth there, that would obviously be where we’ll, we’ll invest very heavily. Um, whereas the right move might be to let other people host it, and we invest super hard on the infra for, like, make- taking advantage of the models, um, and, and customizing them. There’s, there’s, there’s a few avenues we have ahead of us then, and we have, you know, projects going kind of toward to poke at each one. Um, and we’re just kinda getting as much data as we can before we... I mean, we’re gonna have to go all in on another direction soon. Not, not like pivoting away from pre-training, but now that we’ve done that, now w- what’s the next big bet we’re gonna make, and how do we go fully into that? So we’re trying to figure out what that is.
00:59:12 Nathan Lambert: Yeah. My two last kind of, like, real questions are, like, one is... I guess I can start with, like, where do you see the open model ecosystem? Do you think- where would you see it changing substantially in the next six or twelve months? I, like... Or, or do you? Or you just kinda think we’re marching along for a while?
00:59:31 Lucas Atkins: No, I think we’ll, I think we’ll, we’ll be... I, I, I don’t think it’s an unrealistic prediction to make that by the end of 2026, like, the best model in the world is, is some degree of open. Uh, I think that’s very, very possible, especially with, like, what I’ve seen GLM and, and MiniMax do recently. Um, they have started to find that secret sauce that takes you out of just being good on benchmarks and, like, genuinely useful in people’s day-to-day workflows. And, um, I wouldn’t- like, if, if I, you know, came back, and I... Someone came from the future and told me that the best model in the world was, uh, an open-weight model, I wouldn’t be surprised. I actually think we’re on a, a, a super good trajectory, and, and, and fostering and, and promoting that kind of work and adoption here in the United States is gonna be extremely important.
01:00:24 Nathan Lambert: And where do you see the company going? ‘Cause like, like, I have my guess. Like, you kind of hopefully-
01:00:31 Mark McQuade: What’s, what’s your guess? I wanna hear your guess.
01:00:31 Nathan Lambert: Um, you can hopefully do a mix and kind of oscillate into trading when you get... Like, you need to start having the feedback of the real world. I think that’s obvious. Like, it’s o- like, it’s... Well, obviously, you need to make money to survive as a company, but then you need to start using that as the feedback to guide training. And then it’s like, you need to figure out how to balance and do some of them at each time, and you can plan your cluster at different times, and then you kind of... Hopefully, they become a, a loop across each other, and they kind of make it so obvious of why you each need them, ‘cause it, it seems somewhat natural.
01:01:03 Mark McQuade: Yeah, I mean, exactly. You know, you kinda hit, hit it right on the head. Um, you know, getting feedback and then kinda steering the ship from there, um, is, is probably-
01:01:15 Lucas Atkins: ... exactly what we’ll do, but we have a good idea already. I mean, first and foremost, you know, we talked about it earlier, w- we’ve spent a tremendous amount of money. So, uh, we need to go raise some money after we - after we get, you know... We need people to back the, the, the mission and the vision of US open source and, and, you know, so, um, because, uh, you know, we, i- i- Lucas had mentioned about, like, MergeKit and how we flopped the license and, you know. I mean, we’re a smaller-sized start-up. We have-- we’re-- we gotta think of kinda unique ways to try and generate revenue because we don’t have the money of the large labs. So, uh-
01:01:52 Nathan Lambert: Well, I think it’s a benefit to the employee. I think a lot of these labs have over-raised.
01:01:56 Lucas Atkins: Yeah, I like, uh- uh, I-
01:01:57 Nathan Lambert: OpenAI, Anthropic, and all of them are fine. Like, with the OpenAI, Anthropic, Cursor scale, like, let it rip. They should, they should really rip the raising. But all the other companies that are stuck at the, like, the one to two billion range without, like, obvious traction, like, the risk goes to the... I mean, you could-- a lot of them do secondary, so a lot of the founders get out. But it’s like, the risk is the employees get nothing.
01:02:21 Lucas Atkins: Yeah. Yeah.
01:02:22 Nathan Lambert: There is a lot of money, but that’s also why I like the approach, ‘cause it’s like, “Oh, you’re doing the actual start-up thing.”
01:02:28 Lucas Atkins: Yeah, yeah. Yeah, I mean, I think... W- what I was gonna add to what Mark... is just like, what- whatever we do from, uh, uh, uh, scaling and, and speeding things up and growing, um, my goal is to keep our research and engineering teams pretty small. I think, I think that one of the reasons we’ve been able to, to move as quickly as we have is it’s been, like, a small group of, like, highly intelligent, smart, and opinionated people sitting in a room, debating in good faith on decisions. And I think that that’s, uh, uh, under the constraints of, “Hey, we don’t have five hundred million dollars to go and, you know, to rip on, on, you know, X, Y, and Z.” So and I think that’s kind of where creativity comes from, and I think that fostering a culture like that over time is how you can kind of make it so that excellence is less of like a, um, an accident, and it’s actually, like, a by-product of the way that you work. So, so we’re gonna stay small, we’re gonna stay lean, but, um, I, I do think that, like, the, the major, um, kind of challenge for us over the next probably six months, beyond any other models we might have, kind of, uh, think or we’re thinking about, is, is getting up to, like, post-training parity with the likes of DeepSeek, and GLM, Qwen, and others.
01:03:47 Nathan Lambert: Yeah. I, I hear lots of horror stories about this, where it’s usually and-- it’s-- you end up having people that are going after different important abilities, but, uh, like, doing each of the abilities alone is pretty easy to hill climb, but then you just end up with such a mess. It’s like you’re- ... building a custom puzzle, and you’re building all these custom pieces, and they’re magnificent, and then you’d have to, like, pick up these pieces and assemble this unknown thing at the end. And it’s like-
01:04:12 Lucas Atkins: Like they didn’t have the same designer, right? Yeah.
01:04:15 Nathan Lambert: As AI2 is barely scratching the surface of this. Like, you talk to the people at the frontier labs, and it’s like, holy cow, like, post-training is really the Wild West. But a lot of it works. I think, like, we find-- like, even like model merging gives a ton of performance across the whole- ... training pipeline. It’s like- ... you merge at pre-- you merge after each pre-training stage, you merge in post-training. It’s like-
01:04:35 Lucas Atkins: Roon can tell you.
01:04:36 Nathan Lambert: But merging post-training becomes a lot more complicated because you- ... can have all these domains and things, uh.
01:04:41 Lucas Atkins: Well, in, in merging, you know, it, it actually, it used to be very YOLO, um, the way we used to do it, and, and Charles, who, who created MergeKit, I call him, like, chief alchemist, and, like, you’d kinda just send him ten promising checkpoints, and he’d come back a day later with, like, some insane, you know, model that was really good at all of them. And, and you can’t do that as much in post-training anymore because of, uh, of just the, the formatting and the way that RL is done. Like, you do have to be a little bit more surgical about it, but yeah, everyone can tell you, like, any time we start to see anything worrisome at all in training or, or, or even something going really good, you know, “Lucas, what do we do?” I’m like: Merge it. I’m like, just-
01:05:21 Nathan Lambert: Merge.
01:05:21 Lucas Atkins: ... I’m like: “Just take it, just merge it. Let’s see.” And more often than not, it fixes it, so...
01:05:27 Nathan Lambert: Um, do you merge during RL? Like, you could just, like, merge the last few checkpoints and resume or something?
01:05:32 Lucas Atkins: We’ve ex-- we’ve, we’ve dabbled in that, not, not for what we’ve done. You know, again, a, a lot of the, the mini, nano, and large story for Trinity is, like, getting to a level of... what was my level of complexity I was comfortable with us undertaking, and then, uh, not introducing anything more. So, um, not yet. But we, I mean, we, we, uh, regularly merged. We didn’t do it for LARP, but we used to merge a lot, um, during just, like, your standard, uh, um... When we’d do, like, RLHF, we used to do a bunch of merging. We’d do it, like, every five checkpoints. We would-
01:06:11 Nathan Lambert: Online RLHF or D-DPO?
01:06:13 Lucas Atkins: There’s DPO.
01:06:15 Nathan Lambert: Yeah. It’s so much easier to get started. One of my goals is to have somebody figure out how to do actual online RLHF, pure LM feedback, obviously, for scaling. But it’s just like- ... it’s, it’s unsavory to it’s just, like, doesn’t look like DPO-
01:06:28 Lucas Atkins: Yeah, I mean, if, if, you know, if GRPO and kind of op-- in, in the, the present day RL regime, like, if that hadn’t materialized when it did, I think that would’ve been a big topic in 2025. But I do think that, you know, GRPO and just the overall, um, DeepSeek and o1 style reasoning and thinking and RL kind of... Any, a- any person who is thinking of doing that for, like, performance reasons, realize that there was something that had fifty thousand papers released every day on how to do it. Um- ... that was kind of probably right where you’d get the same amount of performance.
01:07:07 Nathan Lambert: Um, do you force dog feeding? Do you make yourself-- do you guys use your own models to understand them? Like, do you, like, make that a thing?
01:07:14 Lucas Atkins: Uh, Mini was the first one we could actually start doing that with, um, a- at least for, uh, a more general day-to-day tasks. So a lot of our, like, internal Slack, we have stuff that, like, monitors Twitter and LinkedIn for feedback on Trinity and, and, and that kind of stuff. That all runs on Trinity Mini now. Um, and then, uh-... you know, we, we put a good amount of work into, into large being, um, you know, good in, in a bunch of your, like, OpenCode and, and Cline, uh, and, and Kilo Code. So, um-
01:07:45 Nathan Lambert: Uh, what does that, what does that work look like?
01:07:49 Lucas Atkins: Uh, working with those guys to get data. And then, um-
01:07:53 Nathan Lambert: That’s, I mean- Good for me to know.
01:07:55 Lucas Atkins: I mean-
01:07:55 Nathan Lambert: I should do that, I guess.
01:07:58 Lucas Atkins: Yeah. Yeah, working with, uh... Or, or I mean, it- the way it started was us, like, using open models and then, like, passing those through as the base URL, and then, like, getting the logs from that. Um, and then realizing that, like, that translated pretty well. Um, and then over time, obviously turning this-
01:08:16 Nathan Lambert: Um, can you expand on this? So I was gonna ask you-
01:08:19 Lucas Atkins: So-
01:08:19 Nathan Lambert: -if you’re, like, using these open models regularly, ‘cause I, I’m just, like, Claude Code psychosis, man. I’m like, “Can’t take that away from me.”
01:08:26 Lucas Atkins: Yeah, I, I use, I use four... I’ve used 4.7 a lot. I think 4.7 from GLM was one of the first ones that could replace a lot of my day-to-day. Uh, I’ll still reach for Claude Code or even 5.2 Pro if it’s, if it’s, like, something that’s, like, really... I- if I do not know how to measure what success looks like for something, I’ll usually use those. Um, but, uh, yeah, I mean, it, it- even using DeepSeek before, um, kind of their May update was hit or miss. But, um, yeah, w- the reason I decided to, like, start talking to these people and working on, like, how can we get data and, and start making our models good in these systems was I would use them. I had a, um, you know, something that would grab the logs, like, it, you know, inter- as a proxy, so it’d like grab the logs and then format them in the messages format. And then I saw that and went, “Yeah, that’s... You can make a pretty good filter for just, like, standard stuff that you don’t want, and kind of hit a scale.”
01:09:30 Nathan Lambert: Yeah, it makes sense. So, so you’re like, uh, open code will let you look at the data, and then you’re probably gonna get a sense for... Like, I don’t even actually know how the, on the back end, the code agents in open code format data, which I think is actually something I should just go look at, ‘cause then you can design around.
01:09:44 Lucas Atkins: Uh, they’re all different. Yeah. Yeah, but you just have to- you just- basically, it all starts from like, what do you want your format to be? And then how can you take what, what those look like to, you know, to... How do you force it into that? The hard thing, though, is, is with newer models like MiniMax and 4.7, the way they do interleaved thinking is, is like... You know, I’m a big believer in post-training. Like, if you’re gonna do interleaved thinking, like, every sample in your data set should be that. Um, it, you know, it should follow that same format and that same behavior. So, um, that gets tricky if you’re trying to, like, take a bunch of Nemo tr... Or, or, or, well, like, uh, DeepSeek data and Qwen data, and then, oh, we’re also trying to mix in MiniMax, and at that point, you’re- it, it gets really difficult ‘cause they all handle thinking slightly differently.
01:10:34 Nathan Lambert: Yeah, I can buy this. Um, okay, this was fun. Any last predictions or things you want people to know about the model? I will say that, um, when you debuted the Trinity models, you had a great blog post that was very to the point, that covered a lot of this. So I’ll definitely link to the, um, what is it? The Trinity manifesto. I enjoyed reading it. So I’ll link to that in the show notes, and, oh, hopefully you have a new one for me to read when you’re done with the model.
01:10:58 Lucas Atkins: Yeah, we’ll do- we will have a tech report. We’ll have a tech report for you, too. So we, we never, we never did a tech report for 4.5B Mini or Nano because we were so focused on just getting to large, but we also thought it’d be very interesting to write it under the, the... How do you go from 4.5B to a 400B MoE in six months, and, like, what did we learn-
01:11:19 Nathan Lambert: That’s right
01:11:19 Lucas Atkins: ... when you’re viewing it as a whole, so.
01:11:21 Nathan Lambert: That’s about the timeframe that, um, Ant Ling took, too, as well. Ant Ling, uh, the anchor, we talked about, they’re like... It took us about six months to do, um, Ring-1T and their 1T models, which, like, it sounds like a lot more, but I think that’s about the same. It, it depends on compute and configs and stuff to go from, like- ... basic modeling to big MoE, which is pretty interesting to see a lot of people speedrun this sort of thing.
01:11:46 Lucas Atkins: Yeah, it’s, it’s a really, uh... It is a logistical nightmare, but, like, I think everyone on the team has had a tremendous amount of fun over the last, uh, six months. So now the fun begins.
01:11:58 Nathan Lambert: Yeah. Congrats on the milestone. Congrats on the model existing. That has gotta be an almighty relief, and I’ll look forward- ... to see what you all are up to soon. I’ll stop by at some point next time I’m in the Bay.
01:12:10 Lucas Atkins: Yeah. Yeah, come by. Yeah, come by.
01:12:12 Nathan Lambert: Thanks for-
01:12:12 Lucas Atkins: Thanks for having us.
01:12:14 Nathan Lambert: Yeah. Thanks, guys.
