

Artifacts Log 4: Reflection 70B, o1 on LMSYS, fine-tuning fine-tunes, and speech models
The latest open models and datasets.
Reminder — no audio for these posts. Previous Issues can be found here.
o1 and Reflection 70B
OpenAI’s o1 remains the biggest story of the week, as we all expected. On the news front, it’s largely been more of the same, most people aren’t quite sure how to use it but a few people are getting exceptional results from it. The vibes of this change with ChatBotArena’s results, which even surprise me in their magnitude. ChatBotArena, despite its flaws, is still the go to destination for “how models will fair in the real world easier tasks.”
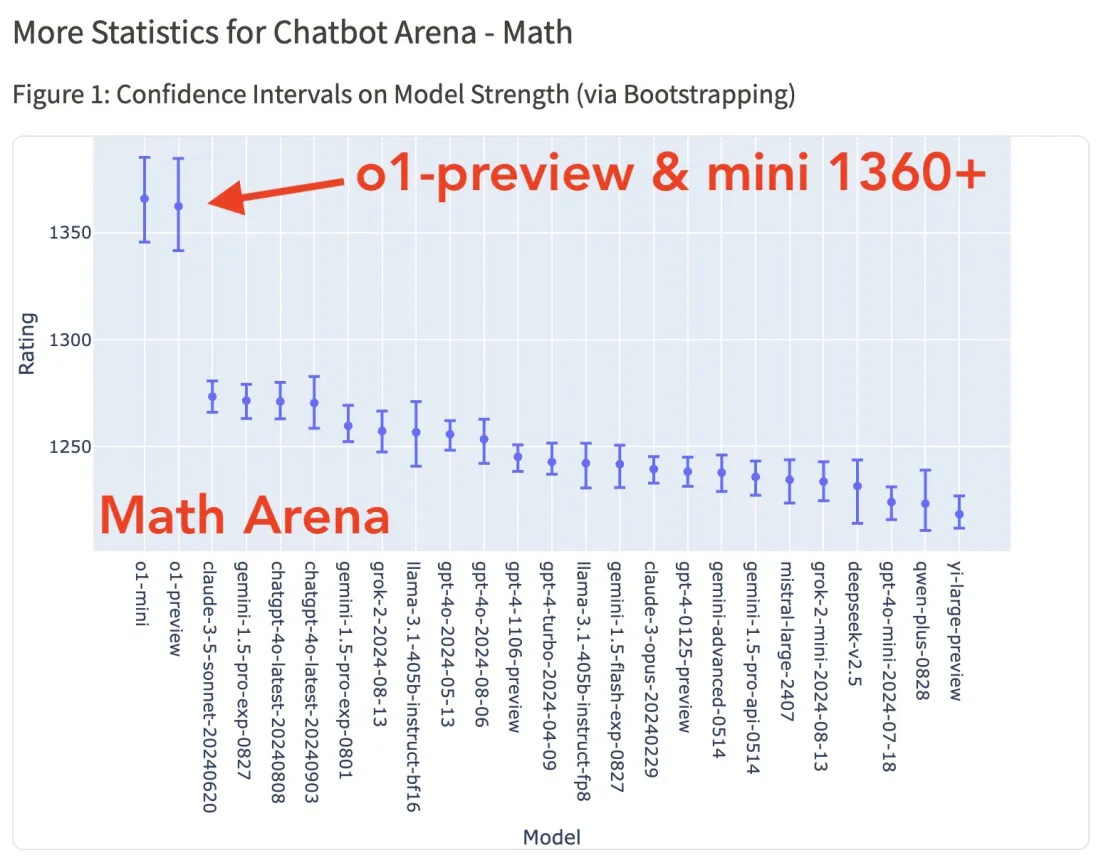
The o1-preview model is another clear step up in Elo relative to the other frontier models on LMSYS’s arena. One should take its results in some bigger error bars than they show, but its rare for us to see step changes on it.
You should be optimistic that o1 models will be come both easier to use and better understood, much like early generations of ChatGPT was relative to instruction tuned models.
Remember that for the first part of this year, we were seeing models incrementally improve on ChatBotArena. It looked like a smooth rate of improvement in Elo scores. Each of the models in this list is a step on ChatBotArena: o1-preview, ChatGPT Sept. 2024, ChatGPT Aug. 2024, Gemini Pro August, GPT 4o May 2024. Below GPT-4o are the rest of the major players.
This reads as OpenAI finding a major hill to climb on impactful style and RLHF training in the last 6 months — and they’re exploiting it.
o1 being top is surprising because it has a very different subjective feel than the rest of the models. It is an outlier in style, which we know to be very important to ChatBotArena, and it is still a major improvement. This is a new era of post-training.

o1-mini being third overall, and joint top in math, pushes back against scaling laws being the highest priority to exploit among frontier labs. This model is rumored to have about 70 billion parameters and it is crushing most competition in a (mostly) blind test.
In the coming months, we’ll see OpenAI release the full version of o1 (i.e. not the preview). This polish could be helping o1-mini a lot and could cause another boost in o1 on ChatBotArena. We’ll also see another top lab ship something closer to this than a standard autoregressive transformer within 6months.
Some have said that this is not a fair comparison because it isn’t normalized by compute. Pushing the frontier out in a way that is served to millions of users counts. The first organization to ship the best capabilities will get the users and the products built on their platform. Then, costs will come down.
On the open-source side of things, the expected timeline is longer. We’ll see signs of life in 6 months, but a fully matching model will be much longer. In the meantime, we’ll be stuck with systems much closer to Reflection 70B than o1.
The story of Reflection 70B has been covered extensively at this point, almost abusively, but the insights of the model largely are missed from this. There are a few things that we can take more seriously at a technical level following this.
Fine-tuning already fine-tuned models, and
Reflection prompting (why I wrote an article the day before Reflection 70B on spending more on inference).
Fine-tuning fine-tunes is a very popular enterprise feature. OpenAI/Anthropic/Google’s fine-tuning APIs are on top of fully fine-tuned chat models, mostly with techniques like LoRA. This is where businesses should start when they’re thinking about fine-tuning models like Llama for internal applications.
At the same time, there’s not a good academic and evaluation ecosystem for these types of models. We’ve seen other strong open models in the past that are fine-tuned multiple times. Nexusflow released Athene 70b just before Llama 3.1 and it was very strong, Acree AI has a strong model, the top models on the RewardBench evaluation benchmark are this, a 9B model fine-tuned from Gemma 9B Instruct matches Google’s Gemma 27B fine-tune in ChatBotArena, and more examples I missed. Reflection is one of these.
We need to construct clearer norms for thinking of these models. It’s too easy to write them off as leveraging the success of the previous model, but that’s reductionist.
The second point is that Reflection 70B’s prompting technique with reflection tokens was largely validated by the o1 release. This is something a lot of people are currently working on. It’s a simple way to spend more on inference, as we have seen with chain-of-thought prompting, and it is only going to become more prevalent.
Models
This week, Qwen released its 2.5 suite. It’s impressive, but I’ll cover it more in the next issue.