



GPT-4o-mini changed ChatBotArena
And how to understand Llama 3.1’s results on the community's favorite benchmark.
Audio of this post is available on podcast players here.
ChatBotArena is the largest community evaluation tool for language models. The LMSYS team, which emerged early in the post-ChatGPT craze, works with most of the model providers to host all of the relevant models. If you’re looking to get to know how multiple models compare to each other, ChatBotArena is the place to start.
ChatBotArena casts language model evaluation through the wisdom of the crowd. For getting an initial ranking of how models stack up and how the models in the ecosystem are getting better, it has been and will remain crucial.
ChatBotArena does not represent a controlled nor interpretable experiment on language models.
When evaluating models to learn which are the best at extremely challenging tasks, distribution control, and careful feedback are necessary. For these reasons, ChatBotArena cannot definitively tell us which models are solving the hardest tasks facing language models. It does not measure how the best models are improving in clear ways. This type of transparency comes elsewhere.
For most of its existence, people correlated the general capabilities tested in ChatBotArena with a definitive ranking of which models can do the hardest things for me. This is not true. In both my personal experience reading data and what the community knows about the best models, the ChatBotArena ranking shows the strongest correlations with:
Certain stylistic outputs from language models, and
Language models that have high rates of complying with user requests.
Both of these have been open research problems in the last two years. Style is deeply intertwined with how information is received by the user and precisely refusing only the most harmful requests is a deeply challenging technical problem that both Meta (with Llama 2) and Anthropic (with earlier versions of Claude particularly) have gotten deeply criticized for.
Among closed labs, their styles have been greatly refined. All of Meta, OpenAI, and Anthropic have distinctive styles (admittedly, I haven’t used Google’s Gemini enough to know).
Meta’s AI is succinct and upbeat (something that has been discussed many times on the LocalLlama subreddit).
OpenAI’s style is the most robotic to me. It answers as an AI and contains a lot of information.
Claude’s style is intellectual, bordering on curious, and sometimes quick to refuse.
When ChatBotArena was founded, these styles were in flux. Now, they majorly shift the rankings depending on what people like. People seem to like what OpenAI and Meta put out.
There are clear reasons why OpenAI’s models top the charts on ChatBotArena. They were the originators of modern RLHF, have most clearly dictated their goals with RLHF, continue to publish innovative ideas in the space, and have always been ahead here. Most people just did not realize how important this was to evaluation until the launch of GPT-4o-mini. Culture impacts AI style.

Every evaluation tool has weaknesses. Here’s the plot LMSYS recently shared with early results for GPT-4o-mini, which caused a bit of a stir.

OpenAI announced GPT-4o-mini, their latest model, marked as “intelligence too cheap to meter” according to Sam Altman. This model seems very likely to be distilled from current or unreleased versions of OpenAI’s models (as Claude does with Claude Haiku and Google with Gemini Flash). This was an important model in OpenAI’s line-up and one that will be used to many applications via the popular OpenAI API. In terms of people following the frontier model market, they were disappointed to see OpenAI going smaller rather than bigger.
On an evaluation that would rank models on “absolute peak ability,” people would expect GPT-4o-mini to be no where near the top 3.
LMSYS went so far as to share a thread and a demo to specifically show how GPT-4o-mini performed so well on their arena and it paints a clear picture of what the average ChatBotArena user tests (as usual, there is plenty of similar discussion on LocalLlama). I went through the battles, particularly with Claude 3.5 Sonnet, to confirm the discussion above. Mini has a distinctive list-and-line-breaks-style and Claude refuses a tad too many requests.
For a first example, in style:

Or a refusal:

There are plenty more like this. For me, the “overall” category of ChatBotArena is taken with large error bars.
Llama 3 in the arena
The scores for Llama 3.1 in the Arena were recently announced. The 405B model comes in behind the latest Gemini Pro and ahead of Claude 3 Opus. The 70B model is closed to older versions of GPT-4.
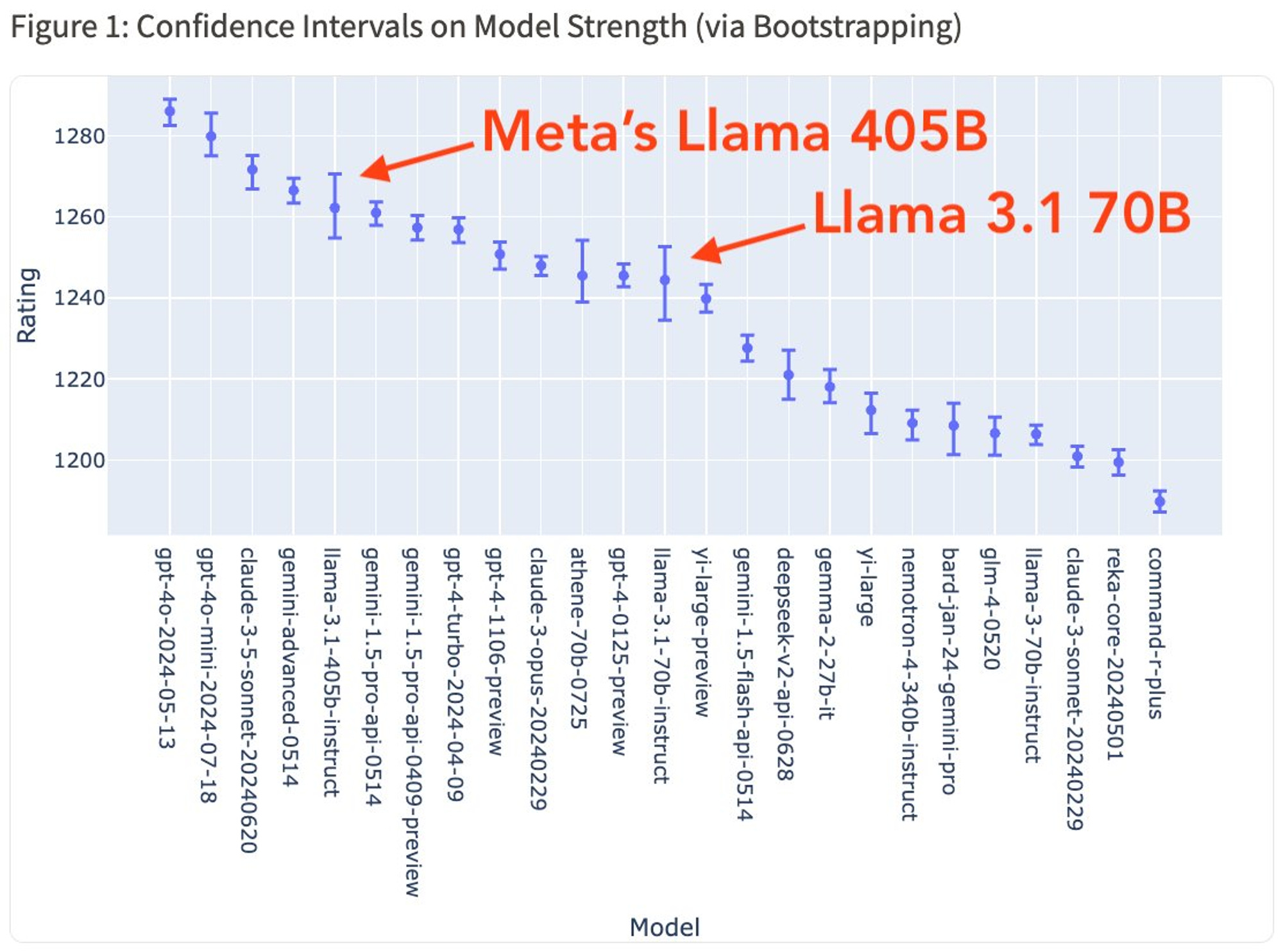
This figure slightly distorts things by making the y-axis very narrow — it makes the gaps between the models look bigger than they are. I very accurately predicted this Arena positioning for Llama 405B a few days earlier on Twitter:
Open weight models get to operate without a safety filter added (e.g. llama gaurd), which is a major boost.
Meta ai's concise and slightly different, friendly style will help it. Claude's style doesn't appeal to the masses who are voting.
Meta team members, being late to join the frontier model party, have shared plenty of interesting comments about ChatBotArena scores when discussing their projects. Some team members explicitly said that the first Llama 3 versions “outperformed expectations on the benchmark.” The recent episode of Latent Space with a lead on the Llama alignment team had more details, emphasis mine.
Now the models are getting so good that it's hard to get to some prompts to break them and to compare models and see their edge cases.
And later on.
Because when we did the preview, and I don't know yet what will be the results for this new Llama 3, but we ended [up] very high in this blind test leaderboard. And to be honest, I didn't expect that. I knew we had good results internally, but how that will transfer to perception from the community, people like using it in practice and comparing it to the other models, I didn't expect that positive feedback.
He continues to say, about the community scoring the models, that “we are limited,” edited slightly for clarity:
We are not good to do that. So, it gives you a very good indicator of how good, helpful, how on the main core of the distribution, simple prompts about the tone of the model compared to the others. But for much more complex prompts, much more intelligent reasoning, coding of complex stuff, it doesn't tell the full story.
Partial solutions and next steps
There are a few existing avenues to give us a more dependable signal for comparing top models.
ChatBotArena’s built-in harder categories (Hard Prompts, Reasoning, Math, etc.).
Private human evaluation, such as Scale AI’s new-ish leaderboard.
Both of these options have issues. Both of these options are better than the default, overall aggregate score on ChatBotArena. Evaluating cutting-edge language models is a domain-expert task. It is not cheap or convenient.
ChatBotArena’s hard categories are curated by training classifiers to route the prompts to different sections. The correlation between these prompts is closer to what we expect, as seen in their blog post.
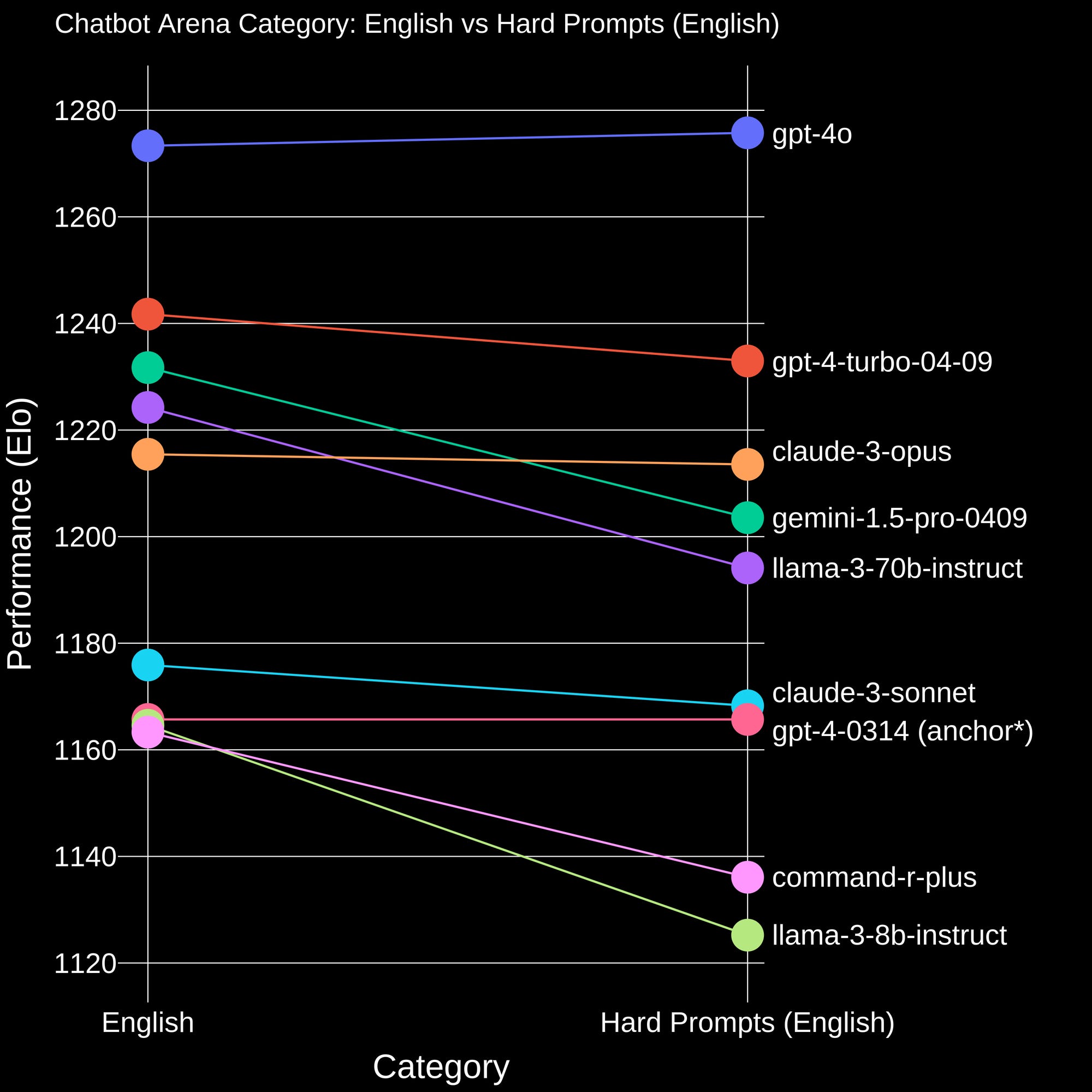
Fundamentally, this is only a small step in a direction that is extremely costly to go all the way on. This category requires a more powerful AI than we have to accurately classify the hard prompts. I suspect this category is actually prompts that present as hard, rather than being prompts that are what is currently hard for language models. We’re hoping to evaluate the latter, but the best we can do is a proxy. One solution could be human data from a provider that knows what the top labs are currently trying to overcome.
In the near future, I expect a mix of Hard Prompts, Math, and Code to become the default on ChatBotArena. It’s not an easy transition to make.
Here are the early results on Llama 3.1 405B Instruct on Scale’s leaderboard. It puts the model right at the top of instruction following, but below other frontier models on the more challenging tasks. This is more or less what I would expect in the shape of Llama’s performance characteristics, but it is closer to the top than I would expect.

Unfortunately, Scale’s leaderboard has a ceiling on trust due to the clear conflict of interest where models they’re selling training data to likely have an advantage by being in-distribution for their human raters. This happens due to the infrastructure of incentivizing human curators, regardless of whether the prompts are indeed fully blind. Even with this, the value gained by looking at this leaderboard with the noisier, more random prompts of ChatBotArena, is high.
No evaluation tool has an infinite lifespan. It’s a sign of progress that the language modeling industry has partially outgrown ChatBotArena. The Arena will still be a central component of model launches, but we need to keep building more tools to give a more diverse and robust representation of language model evaluation. As many as possible of these should be run in public and by organizations with simple incentives.
While we focus on frontier models, choosing prompts that fairly compare the best language models and those a tier below them may not exist. Much like there were plenty of prompts that open models couldn’t begin to solve in the early days of GPT-4, there are likely plenty of prompts that Claude 3.5 Sonnet can ace and few other models can. Global arenas built on model-to-model evaluations can never capture this information. For this, we must continue relying on specific benchmarks. Whenever you average over categories, you reduce some signals.
Housekeeping
Audio of this post is available (soon) in podcast form (and sometimes on YouTube).
My real podcast is at retortai.com.
Paid subscriber Discord access in email footer.
Referrals → paid sub: Use the Interconnects Leaderboard.
Student discounts in About page.