

Model commoditization and product moats
Where moats are tested now that so many people have trained GPT4 class models. Claude 3, Gemini 1.5, Inflection 2.5, and Mistral Large are here to party.
GPT4’s level of performance has been replicated within multiple organizations. GPT3’s level of performance has been reproduced by many. GPT2 level models can be trained by almost everyone (probably on the order of $1k to do in a few hours). The early idea that models could maybe be moats has been so resoundingly defeated that people don’t expect language model providers to have any moats.
In this era of massive investment into AI, the land grab phase, we’ll see the most providers trying to enter the space. It has turned out that many of these providers have reached largely similar tiers of capabilities, which may not always be the case as scaling costs get even higher (and future technical challenges emerge). Market share distributions will be defined by who can create sticky user behavior. To set the stage, I’m bringing up this image I Tweeted last week. It shows that since Gemini 1.5 Pro on February 15th, we’ve seen 4 GPT4 class models in Gemini, Claude 3 (GPT4 turbo tier, actually), Mistral Large, and Inflection 2.5.

I expected to have Llama 3 by now, but it seems the scope of what they’re doing is constantly changing. I have heard credible rumors that it is done training and credible rumors that multiple teams are trying different things and the best one wins. So, who knows when we’ll get this model?
These broadly available GPT4 class models are very rapidly going to create a high-entropy situation in the next few months — prices will fluctuate, companies will fight for usage, and narratives will shift fast. This fluctuation is the organizations trying to find a competitive advantage and a moat.
Every time a company matches GPT4 performance, which was trained in the distant past of 2022, folks love to tout the Google “We have no moat and neither do they” memo, which I’ve already debunked at length. Quoting the introduction of that piece:
The companies that have users interacting with their models consistently have moats through data and habits. The models themselves are not a moat, as I discussed at the end of last year when I tried to predict machine learning moats, but there are things in the modern large language model (LLM) space that open-source will really struggle to replicate. Concretely, that difference is access to quality and diverse training prompts for fine-tuning. While I want open-source to win out for personal philosophical and financial factors, this obviously is not a walk in the park for the open-source community. It'll be a siege of a castle with, you guessed it, a moat. We'll see if the moat holds.
Having the best cheap model could be another way to create a moat. While the companies creating openly trained and permissive-ish usage don’t normally have the economies of scale to drive down inference costs, those of Google, Anthropic (a borderline inclusion on capital assets), and OpenAI will probably use it as a loss leader. We need more data on the paid versus free tier usage of the various applications, and especially conversion numbers. We likely won’t get this data, so don’t buy into the PR narratives you hear too much.
The model I’m expecting to test this hypothesis is Claude 3 Sonnet. Can they get many users to unsubscribe for a better free model? Unlikely. Can they bring more people in from OpenAI’s free tier, probably? Both Anthropic and OpenAI probably have no chance of winning an inference price competition versus Google, though. It’s very likely in the long term that they can make more margin per user on advertising relative to subscriptions anyways. We’ve seen this switch with streaming services recently — it’ll just take longer to figure out the advertising stack of LLMs due to the complexity of the infrastructure and the new-ness of the information medium. Measurable ads will be annoying (forced links in responses for example), but subtle brand ads will be harder to sell.
In some ways, Claude 3’s timing seems like their last shot to get a consumer footprint (with GPT4.5-Turbo around the corner). Google’s recent “ship it” attitude and OpenAI’s larger consumer footprint will be extremely hard to beat. In some ways, I don’t even expect the Claude 3 step to matter much for paid users. Disruption theory on the internet has long been driven by the need to have a dramatically better experience or price, not just marginal gains.
The hypothesis that Claude 3 won’t meaningfully shift the consumer space is the strongest indicator that moats exist here. The people on Twitter switching over will be happy to have done so, but they’re not the average paying customer. We saw the same users “stop using ChatGPT” while tons of people got a ton of value out of it. ML systems’ moats are defined as just that, a system (or product), not a model like their open counterparts.
The Open’s opportunities and coordination problems
The biggest moat killer for LLMs is having all levels of the stack available in the open. Model weights are just one piece of this, with user data and infrastructure also playing a huge role.
The commoditization of GPT4 class models is a phenomenal indicator of the progression of the open LLM ecosystem. There are countless individuals who can easily pay the price it takes to create a model like Claude 3 and release it to the world. Depending on your accounting, the ballpark price will probably be on the order of $100 million (yes, I know you can make many different arguments).
The other method to solve this resource problem is via the coordination of open actors. Most of the issues in pretraining development take more engineering time rather than true trade secrets. Small organizations training models are constantly guessing at which feature will most improve their next model — doing all of them is how you have GPT4 class base models.
Even if we get the same base models, open LLM advocates need to create some tricky data infrastructure to truly reproduce GPT4 at a user level. In Where 2024’s “open GPT4” can’t match OpenAI’s, I wrote:
In short, the open capabilities of RLHF and all methods of preference fine-tuning are severely lacking their closed counterparts. Direct Preference Optimization (DPO), the algorithm providing boosts to usability, AlpacaEval, and MT Bench for open chat models isn’t a solution it’s a starting point (as I’ve written about extensively). We have a lot of work to do to truly have local chat agents at GPT4 quality. Primarily, I would recommend digging into data and continuing to expand evaluation tools centered around these methods. We’re just pushing the first few rotations around on the flywheel and efforts on data and evaluation tend to compound the most, instead of methods with vibes-based evaluation. This is epitomized by the fact that most fine-tuning data is derivative of GPT4 or a related model like Claude. OpenAI’s John Schulman already gave a very good talk on why training on distilled data can limit the performance of a model.
We need what Soumith was calling the sinkhole on his recent appearance on the Latent Space Podcast (which covers more actual ground than the Lex and Yann interview everyone has been asking me to comment on). The sinkhole is where all the prompts and feedback labels will go from all of the open providers. HuggingChat, Ollama, local llama, and anyone hosting open models, needs to do the hard work of getting permissions to transfer and share data.
The total usage of open models at moderately sized providers is probably less than the likes of OpenAI with 100 million consumer users, but it is also almost surely enough to have enough training signal. Coordination in the open is part of the problem that open-source has definitionally always fought — open-source systems have many different stakeholders and therefore opinions on what to do or not do with the data. I don’t see the data coordination problem being meaningfully solved with open models anytime soon — there will be a meaningful gap in preference alignment between open and closed models.
The newest version of the open-source AI license from the Open Source Initiative dropped last week. It’s slightly controversial in the fact that it doesn’t mandate open data, but just data processing instructions.
Reminder: People still think LLMs aren’t useful
A somewhat crucial aside given all the progress. The people who are ready to have a short-term impact on the development of LLMs are the best LLM sommeliers. People who don’t use models don’t speak the same language. There are countless executives and prominent people denying the usefulness of these models. It’s fine to ignore these people on the grounds of personal experience — LLMs feel like they’re getting more useful on a quarterly basis. It’s not that LLMs are unlocking new things that they can do, but more of the feeling that the things we’ve been trying to do with these models have gotten more reliable.
There are very few reasons to argue for the saturation of abilities of LLMs other than the ratio of cost to performance gain. As long as the performance gain comes, the marginal cost of tech businesses will almost surely make it worth it. Many people pay for multiple $20 per month subscriptions for AI, so if one is much better, getting them to pay $50 per month seems totally reasonable. This calculation does not include the potential for transformative new applications and use cases, which are definitionally hard to predict.
From someone selling on the internet (please subscribe, thank you), people underestimate how hard it is to get people to pull out their credit cards. More than a year into this, people would definitely stop paying if it wasn’t useful. We pay for multiple because being fast to find the best one is worth it to us.
I don’t even feel like I use the models enough to get a sense of how powerful they are and I use them at a high level almost daily. There’s a lot of alpha to unlock with deep familiarity — I know multiple people who regularly have a jailbreak that works to unlock special behaviors. Supposedly, it’s not so hard still to get the model to think it needs to do something it was trained not to in order to help you.
Things that are coming

With the probably coming Grok release, it’s wild how many mid-sized (7 to 5 billion parameter) open models there are. I can’t help but think how easy it would be for the leading closed companies to crush these models if they wanted to. Sometimes the open models look like playthings relative to API models. 6T tokens of training data for Google is totally small beans. It’s a bifurcated market with the press around it designed to make it confusing by burdening the terminology of state of the art.
I’m interested in the Chinese open models as a source of randomness. I’m not an expert, but it seems likely their incentives are not to play the exact same game as the US and European technology companies (obviously in some ways given the chip bans). This, outside of political risk, seems like a very likely net benefit for the progression of open LLMs.
And GPT4.5 is right around the corner, with a placeholder blog post being indexed by Bing on OpenAI’s website.
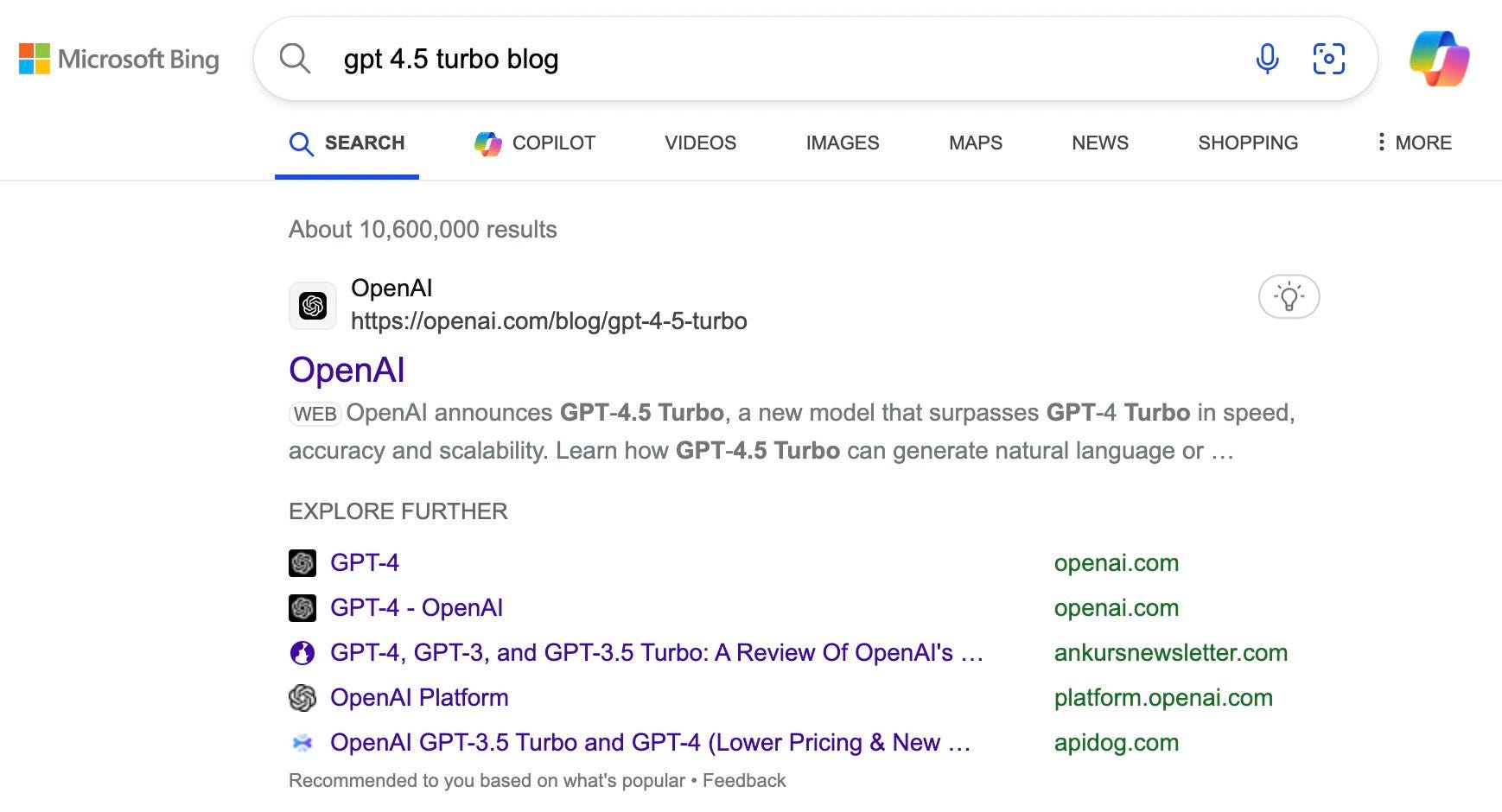
Audio of this post will be available later today on podcast players, for when you’re on the go, and YouTube, which I think is a better experience with the normal use of figures.
Newsletter stuff
Elsewhere from me
On the Retort episode 22, we debated if Claude 3’s success changes anything fundamentally in the LLM landscape.
Models, datasets, and other tools
An interesting instruction (prompt) generating model was dropped by Nous Research. More on Twitter.
Contextual dropped an interesting model trained with the new-ish RLHF method KTO.
Another Gemma fine tune popped up, are people starting to unlock the 8B model?
Links
A big update in consumer GPU fine-tuning market via Answer.ai and friends.
Good overview slides from Thom Wolf of HuggingFace on LLM things.
Housekeeping
Paid subscriber Discord access in email footer.
Referrals → paid sub: Use the Interconnects Leaderboard.
Student discounts in About page.