

This is the first of a handful of interviews I’m doing with teams building the best open language models of the world. In 2025, the open model ecosystem has changed incredibly. It’s more populated, far more dominated by Chinese companies, and growing. DeepSeek R1 shocked the world and now there are a handful of teams in China training exceptional models. The Ling models, from InclusionAI — Ant Group’s leading AI lab — have been one of the Chinese labs from the second half of the year that are releasing fantastic models at a rapid clip.
This interview is primarily with Richard Bian, who’s official title is Product & Growth Lead, Ant Ling & InclusionAI (on LinkedIn, X), previously leading AntOSS (Ant Group’s open source software division). Richard spent a substantial portion of his career working in the United States, with time at Square, Microsoft, and an MBA from Berkeley Haas, before returning to China and work at Ant.
Also joining are two leads of the Ant Ling technical team, Chen Liang (Algorithm Engineer), and Ziqi Liu (Research Lead).
This interview focuses on many topics of the open language models, such as:
Why is the Ant Group — known for the popular fintech app AliPay — investing so much in catching up to the frontier of AI?
What does it take to rapidly gain the ability to train excellent models?
What decisions does one make when deciding a modeling strategy? Text-only or multimodal? What size of models?…
How does the Chinese AI ecosystem prioritize different directions than the West?
And many more topics. Listen on Apple Podcasts, Spotify, YouTube, and where ever you get your podcasts. For other Interconnects interviews, go here.
Some more references & links:
InclusionAI’s homepage, highlighting their mission.
AntLingAGI on X (models, research, etc.), InclusionAI on X (overall initiative), InclusionAI GitHub, or their Discord community.
Ling 1T was highlighted in “Our Picks” for our last open model roundup in October.
Another interview with Richard at State of Open Conference 2025.
Over the last few months, our coverage of the Chinese ecosystem has taken off, such as our initial ranking of 19 open Chinese AI labs (before a lot of the models we discuss below), model roundups, and tracking the trajectory of China’s ecosystem.
An overview of Ant Ling & Inclusion AI
As important context for the interview, we wanted to present an overview of InclusionAI, Ant’s models, and other efforts that emerged onto the scene just in the last 6-9 months.1 To start — branding.
Here’s a few screenshots of InclusionAI’s new website. It starts with fairly standard “open-source AI lab messaging.”
Then I was struct by the very distinct messaging which is surprisingly rare in the intense geopolitical era of AI — saying AI is shared for humanity.

I expect a lot of very useful and practical messaging from Chinese open-source labs. They realize that Western companies likely won’t pay for their services, so having open models is their only open door to meaningful adoption and influence.
Main models (Ling, Ring, & Ming)
The main model series is the Ling series, their reasoning models are called Ring, and their Multimodal versions are called Ming. The first public release was Ling Plus, 293B sparse MoE in April. They released the paper for their reasoning model in June and have continued to build on their MoE-first approach.
Since then, the pace has picked up significantly. Ling 1.5 came in July.
Ling (and Ring) 2.0 came in September of this year, with a 16B total, 2B active mini model, an 100B total, 6B active flash model, and a big 1T total parameter 50B active primary model. This 1T model was accompanied by a substantial tech report on the challenges of scaling RL to frontier scale models. The rapid pace that Chinese companies have built this knowledge (and shared it clearly) is impressive and worth considering what it means for the future.
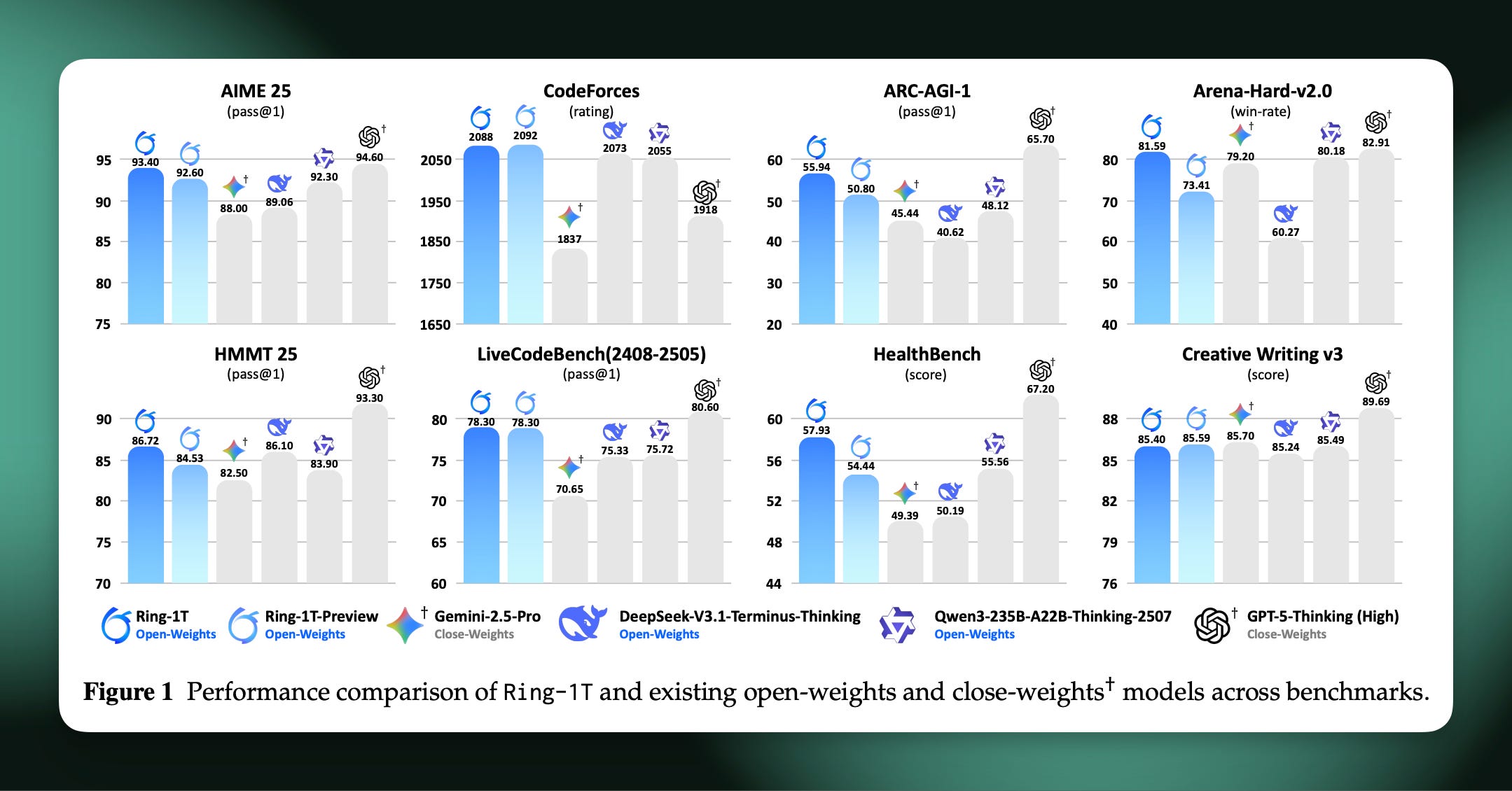
Eval scores obviously aren’t everything, but they’re the first step to building meaningful adoption. Otherwise, you can also check out their linear attention model (paper, similar to Qwen-Next2), some intermediate training checkpoints, or multimodal models.
Experiments, software, & other
InclusionAI has a lot of projects going in the open source space. Here are some more highlights:
Language diffusion models: MoEs, sizes similar to Ling 2.0 mini and flash (so they likely used those as base). Previous versions exist.
Agent-based models/fine-tunes, Deep Research models, computer-use agentic models.
GroveMoE, MoE arch experiments.
RL infra demonstrations (Interestingly, those are dense models)
AWorld: Training + general framework for agents (RL version, paper)
AReal: RL training suite
Chapters
00:00:00 A frontier lab contender in 8 months
00:07:51 Defining AGI with metaphor
00:20:16 How the lab was born
00:23:30 Pre-training paradigms
00:40:25 Post training at Inclusion
00:48:15 The Chinese model landscape
00:53:59 Gaps in the open source ecosystem today
00:59:47 Why China is winning the open race
01:11:12 A metaphor for our moment in LLMs
Transcript
A frontier lab contender in 8 months
Nathan Lambert (00:05)
Hey everybody. I’m excited to start a bit of a new series when I’m talking to a lot more people who are building open models. Historically, I’ve obviously talked to people I work with, but there’s a lot of news that has happened in 2025 and I’m excited to be with one of the teams, a mix of product, which is Richard Bian and some technical members from the Ant Ling team as well, which is Chen Liang and Ziqi Liu. But really this is going to be a podcast where we talk about how you’re all building models, why you do this. It’ll talk about different perspectives between US, China and a lot of us going towards a similar goal. I was connected first with Richard, who’s also talked to other people that helped with Interconnects. So we can start there and go through and just kind of talk about what you do. And we’ll roll through the story of building models and why we do this.
Richard Bian (01:07)
Hi. Again, thanks so much, Nathan. Thanks so much for having us. My name is Richard Bian. I’m currently leading the product and growth team of Ant Ling, which is part of the Inclusion AI lab of Ant Group. So Ant Group is the parent company of Alipay, which might be a product which many, many more people know about. But the group has been there for quite some time. It used to be a part of Alibaba, but now it’s a separate company since 2020. I actually have a pretty mixed background. Before I joined the Ling team, I’ve been doing Ant open source for four years. In fact, I built Ant open source from a technical strategy, which is basically a one-liner from our current CTO all the way into a full-fledged multifunctional team of eight people in four years. So it has been a pretty rewarding journey. And before that, my last life, I’ve been spending 11 years in the States working as a software engineer with Microsoft and with Square. Again, it was a pretty rewarding past. I returned back to China during COVID to be close with my family. It was a conscious decision. So far so good. It has been a pretty rewarding journey. And I really love how Nathan you name your column as Interconnects and you actually echoed when you just began the conversation just now. I found that to be a very noble initiative. So very honored to be here.
Nathan Lambert (02:48)
Hopefully first of many, but I think you all have been doing very interesting stuff in the last few weeks, or last few months, so it’s very warranted. And do you two want to introduce yourselves as well?
Chen Liang (02:58)
Me first. My name is Chen Liang and I’m the algorithm engineer of Ling Team, and I’m mainly responsible for the floating point 8 training during the pre-training. Thank you.
Ziqi Liu (03:16)
My name is Ziqi Liu and I graduated, a PhD from Jiao Tong University in China. And I’ve been working at Ant Group for about eight years. And currently I’m working on the Ling language model. That’s it.
Nathan Lambert (03:45)
Nice. I think the way this will flow is I’m going to probably transition. It’ll start more with Richard’s direction. Then as we go, it’ll get more technical. And please jump in. I think that we don’t want to segment this. I mean, the border between product growth, technical modeling, whatever, that’s why AI is fun is because it’s small. But I would like to know how Inclusion AI started and all these initiatives. I don’t know if there’s a link to Ant OSS. I found that in prep and I thought that was pretty interesting and just kind of like, how does the birth of a new language modeling lab go from idea to releasing one trillion parameter models? So like, what does that feel like on the ground?
Richard Bian (04:18)
There’s actually one additional suffix for that in eight months’ time. In fact, we kind of began all of this initiative in February this year. So just to begin with for the audience who probably didn’t know much about Inclusion AI, Inclusion AI basically envisions AGI as a humanity’s shared milestone, not a privileged asset. So we started this initiative back in the February of 2025, inspired by the DeepSeek Research Lab. So the DeepSeek Research Lab and their publication, in fact, motivated a lot of people. I believe not only in China, but globally. Taking one step more closer to the AGI initiative by showing it’s probably not an exclusive game for only the richest people who can afford the best hardware and the best talent. So the way we’re kind of looking at it is like why we named that Inclusion is because we actually have that gene with the company. So the decision was actually made, of course, the decision was made beyond my pay grade, but it was actually very well informed internally for the mission and vision that we want to be more like DeepSeek, which is a research lab with a dedicated effort of pursuing AGI. In fact, I mean, if you kind of think about Ant Group with our business model, like we’re a Fintech company, to some extent, very similar to a combination of Square, Stripe, and many other companies in the States, we have a very broad range of businesses which focus not only on the financial vertical, but on medical insurances and the technical services as well. So a lot of those businesses. In order for us to actually be able to support those businesses, I would say long-term success in the next five to 10 years is going to be critically important for us to be able to really focus on the fundamentals of AI. And we feel that the language model is a key to that door. We cannot give up on that initiative.
Nathan Lambert (06:52)
There’s a lot here and I agree with this. And I think that it’s like, the Ant Group is a big large tech company. And I think large tech companies being able to train AI as like most of the audience here is going to be like, yes, they definitely should be doing this. It’s a transformative technology. I think the two things to double click on are, we’re going to have to define like what you think of as AGI and why you’re pursuing this. Because it has to go deeper than like a term that we are doing. I know like DeepSeek is very ideological in their pursuit of intelligence. So I think it’s good to do that. And then I will also double click on the question of like, why open models and like, because DeepSeek is doing like open and as strong as they can, they’re text only. We’ll talk about this later. But it’s like, let’s do each of these individually to kind of ground the motivation.
Defining AGI with metaphor
Richard Bian (07:51)
Sure. I guess, I mean, for AGI, the way we are looking at it is like, I don’t think there’s a definitive answer to that. I mean, if we kind of search Google or any other search engines, it will give you a line, which means something. But it doesn’t mean anything, honestly, to me personally, just by looking at the definition. I would probably use a metaphor. People are probably very familiar with the navigation era. It’s a glorious navigation era back in the 1400s. Now, I think it feels more like all the ships are just leaving Lisbon last year, or maybe like two years ago.
Nathan Lambert (08:18)
I like it. I agree with this more than most of the definitions, because a lot of the definitions are grounded in like work or something.
Richard Bian (08:26)
The one I’m kind of looking at is like, all the ships are leaving Lisbon. Some of them are heading west, knowing for a fact that, hey, India is over there. But now we all know the truth that India is on the east side. But it doesn’t matter. It’s the whole American continent. So the way I’m kind of looking into the definition of AGI right now is like, I personally have a very firm belief that human intelligence and machine intelligence, to some extent, have their similarities. Humans are trying to, to some extent, explore the limit of human intelligence with the help from the machines. So when everything was beginning, we were kind of using all of this as a co-pilot mode. But moving forward, there are all of these theories indicating that there might be an intrinsic point that the machine intelligence, it goes all the way back from the tooling time. They believe that machine intelligence might, at one point, exceed human intelligence. So I guess we’re looking to that pivoting point. Before we reach there, honestly, I don’t know where we’re going and how long we can go towards that particular direction. But clearly, there are some common consensus right now, including maybe MoE (Mixture of Experts) as architecture, including the pre-training, even to some extent, we’re seeing a diminishing return. But pre-training is still pretty important. And reinforcement learning, to some extent, is probably another general agreement that this might not be wrong. We don’t know if this is right, but it might not be wrong. So there are all of these exploratory directions that we believe in. So we’re just kind of sailing there and see how that goes.
Nathan Lambert (10:20)
I love this. And I think the crucial question is for Chen or Ziqi is like, the team like, how do you build team alignment around this? Is this something that you feel like you walk into the office or get on a call and everybody’s in agreement? Or is this like a vision that you’re still building or trying to sell? Like, to what extent you could say, because I think there’s a big difference between like, I buy the vision for Inclusion AI, but it’s like, how real is this when you’re across the org?
Richard Bian (10:49)
I can maybe share my feeling and Ziqi and Chen can chime in. Of course, at the very beginning, there’s skepticism. It’s by human nature, right? So the way we’re looking at it is like, I think DeepSeek gives a very clear indication that this might be working. There has been this hazy, chaotic era of 2024, which nobody has the tools to navigate. So people are very cautious about sailing. You see ships going out and came back crippled, and you begin to worry about what’s going on there.
Nathan Lambert (11:34)
I think there’s a big difference between the US because I think in the US everybody was bought in. And I’ve talked to a few more labs in China and it’s like there’s so much emotional energy on the DeepSeek moment in China that I think in the US people forget about it where it’s like, I could see this in the sequence of releases as well because it’s like everybody had a few months after DeepSeek like all these labs in China have started releasing models and I just think that it’s good to have you say this, is a shared sense of people so people can internalize like how much has been mobilized. And that’s kind of a culturally salient point.
Richard Bian (12:04)
It’s motivating. To some extent, there was this very famous navigator called Zheng He back in the Ming dynasty. So I think basically when Zheng He was able to pretty much pull through the trip all the way to India from China, people began realizing that, hey, not only the Portuguese can do this kind of long journey sailing, the Chinese can do that too. And we’re exploring different parts of the map. You know, toward the end of the day, nobody knows the whole picture. So the way I’m kind of looking at it is like, first, I’m very bought into the mission to some extent that it kind of feels like, you know, even though we begin sailing late, but we do have our own kind of taste to this game. So we will be able to contribute. And you did ask about the question, you know, like why we chose to be open, right? To some extent, I cannot really believe that open is a choice, just like how the leaders in this game are not the most open player in the game, right? But if you’re kind of thinking about playing poker, the trick leader has their own strategy, which is all understandable. For us, because we’re joining the game at this stage, I guess the best strategy would kind of feel like, A, really trying to follow suit to the right direction to minimize the mistakes we’re making at this moment because we’re so late. Second, stay open and stay polished. So keep a very open mind about what’s going on in the surroundings. And that’s probably the best we can do. That’s my two cents.

Nathan Lambert (13:51)
To provide some color and I’ll have a whole note in the page that I release with this for people listening. The first Ling model, which is like their text only model, very, you could see iterations from DeepSeek and the architecture was in April and then a big updated Ling 1.5 in July. And then in September or recently was Ling 2.0, which also came with a multimodal Ming and a reasoning Ring model. And I think like by this September release is when like me and a couple of people that work at Interconnects were like, Holy crap, like this is a, this is like very much a real deal model. And to kind of ramp in that period of time is not easy. Like there’s a lot of companies in the US that are trying to do this right now. A few companies in China have shown that they can do this. And it’s like, I guess if you want to explain this kind of Ling, Ring, Ming series of models and like if this is a clear strategy behind this or if this is what works like, how did you evolve through the first models through the summer to today to kind of get to this point?
Richard Bian (14:56)
Sure. So I mean, first and foremost, I think the foundation model is really important. To some extent, I’ve been working with many people on the system side, because Ant Group has a very solid cloud-native infrastructure team. So the team has been, when we talk about this, we’re kind of beginning using the metaphor. The model is really like an operating system. It’s not like the operating system itself, but it’s more like the kernel. Right, so only a few people can actually write kernel code, even nowadays. Just like how there’s the most talented people who can actually work on the model team right now. We feel that it’s not only a key leading to the technical future, but it’s also a key leading to the user experience future. Because we do see the, I personally believe in the trend of technology brings in new interactions which will lead to new product, which will lead to new business models, which will lead to potentially new organization structure, rinse and repeat. So we kind of like really choose to do the fundamental model of the Ling series because of that. And the Ring series is an obvious next, given the relationship between V3 and R1. It definitely indicates about how we can potentially take a very polished, well, actually, a very intelligent individual, unpolished, and put some reinforcement learning on it to make it a much better individual in one clear vertical direction. We’re going to be touching on some of those kind of technical aspects in our conversation next. But that has been a very clear direction.
Nathan Lambert (16:48)
Do you see this evolving with kind of feedback from within Ant Group, which is like, you’ve also released this diffusion language model. A diffusion language model is very interesting. I’m going to just go out on a little bit of a side rant because I’ve heard, I was talking to people about these and it’s like very hit or miss with me, whether or not I think they’re going to be big. Because we see that tool use and reasoning is a big thing. So the whole idea of a diffusion language model is you generate a very long sequence at once and that could save on costs because you don’t have this kind of quadratic memory increase and you do very long sequences. So I saw that I was optimistic. And then you see the idea of tool use, which is like, you have to be able to chop up the reasoning. And I was like, I’m really bearish on diffusion models for language again, because you have to be able to search and execute code. But then I was hearing that in like user facing products, like code diffs, where if you’re generating a website and you did take a prompt and go to a huge diff on a code base really fast, then language diffusion is actually really nice. And the motivation of the question is like, do you have this feedback loop in your modeling where Ant Group is trying to use these things for products and might like have a bit of a feedback of like this latency isn’t fast enough or like this area you need to move it to, or is this kind of like a separate play of just build the best models you can and figure it out later?
Richard Bian (18:12)
That’s a very perfect question. We use this metaphor that we’re probably also doing this reinforcement learning in real life by trial and error. Almost kind of feels like, so I think Nathan, you nailed a very good question. And there are some very clear consensus about coding agents, tool use and people kind of going down a path and pursuing their own business models and begin making revenues. So that’s one type of usage patterns for language models. We do that and we see some very clear, I would say feedback loops in that direction. So that’s one pillar. And the second pillar is about the not so clear aspect. By saying the not so clear aspect, it’s like, I believe everyone in the Silicon Valley and in Seattle is still scratching their heads trying to understand about, hey, when can I break even with all this investment? Are we really generating enough user values kind of back to, I’m a product person. So all of those kinds of words keep coming back into my head. And, you know, at this moment, consciously speaking, it’s very hard to come to the conclusion that, you know, all of this is valuable enough for the end user. But, you know, we’re trying to explore the directions for that. I would say a lot of the, you know, generating the whole website, you know, what Labo did, it’s an interesting form of product. But at this moment, we don’t know if it’s A, sustainable as a business model, B, if this is the best type of product we can offer to the user. So all of those are iterative. Within company, we do have some of those explorative products that use our models, not only the Ring model, but Ming as well, like the multimodal. And you mentioned about the, so that’s the second pillar. And the latter is more like the last pillar, because Ant Group does have a research institution called Ant Research. So the model is a joint collaboration between the research and the Ling Team.
How the lab was born
Nathan Lambert (20:16)
I guess there’s another like org chart question, which is like, where in the structure of the big tech company that is Ant did this Inclusion AI slash Ling and all of this grow? Like, is this within cloud that there’s a new modeling or research org or is it kind of separate? Like, do you feel like this is a part of the bigger company or are you kind of insulated from this?
Richard Bian (20:42)
You can actually search on Google and find information about Ant Research which is a joint research lab focusing more on a lot of these frontier technologies like graph, deep learning, reinforcement learning, before all of this. So that’s the background of Ant Research. And second, when we begin forming the AGI initiative of Inclusion AI, we begin getting very serious. So we begin putting all of these resources together to some extent physically, but more from the organizational ways of saying that all of these teams of financial models and research lab institution and the user experience expert focusing on exploratively looking into the next big application that people will actually use. So all of this, we kind of began forming this internal, I wouldn’t call that organization, but more like this internal initiative directly driven by our CTO. So it’s very serious effort. It’s very serious to the extent that, you know, it feels more like when the team actually formed the original DeepSeek initiative. So all of these people, you do nothing else but only focusing on this and this is the only important thing for this.
Nathan Lambert (22:01)
It’s like so much of this is that the mystique I feel like is that in the West, we don’t get what would normally be gossip of what is happening in the Chinese tech ecosystem, which I don’t think this is hard to see if you have friends that work at Ant Group, because it’s probably you’re moving hundreds of people’s jobs around and people talk. Whereas like in my circles, it’s like, Meta is doing another reorg. And then you hear about it in the news a few days later. So it’s just like, I don’t know. That’s my reflection hearing all of this. And I’m mostly learning that all of these orgs end up similar in size. And then you have to prioritize resources per researcher and all of these normal things. I’m going to start transitioning into this section we had prepped on actual modeling things, which is mostly on pre-training, which is fun. I think that state of affairs on my pre-training knowledge from AI2 is that we’ve scaled, done plenty of dense models and some architecture things from up to like 32B, some experiments at 70B that one didn’t work out. MoE is work in progress. So I’m personally very interested in architectural decisions that enable MoEs and long context.
Pre-training paradigms
I think the kind of basic thing is just like, if you’re pre-training, I mean, this is for Ziqi is like, what does your, how do you feel like your trajectory is as a researcher as you’re going through these months? This could be just like, what does your work feel like when you’re trying to boot up like a DeepSeek style, very ambitious lab building new infrastructure and getting models off the ground. And then we’ll kind of go into some more specific discussions around like Ling 1T later and stuff like this. But it’s like, how is building this?
Ziqi Liu (23:45)
Our architecture indeed refers to OpenAI’s scaling law or DeepSeek’s scaling law. They really do a good job. In our Ling scaling law, the non-embedding training FLOPs play the central role of our scaling law. So we set up our own framework that provides foundation for a standardized experimental pipeline. So there are many questions when we start conducting scaling law under the MoE architecture. So the first question is, can we find simple rules for finding optimal hyperparameters with respect to training FLOPs, which are not sensitive to the structure of MoE. Similar to DeepSeek, we first discovered the optimal critical hyperparameters with respect to training FLOPs and the MoE architecture. We find those optimal hyperparameters are not that sensitive to the structure of MoE, like the activation ratio and something others in a mild condition, but more related to the training FLOPs. So this is our first finding. And then we found activation ratio is critical and can consistently improve if we reduce activation ratio.
Nathan Lambert (25:14)
Can you say more about this? I mean, most of pre-training is a lot of different things, which you’re accumulating FLOP efficiency while getting model performance. And then it’s like Chen, you also were saying you focused on FP8 stability, FP8 and training stability in general. So I’m kind of curious of like any major, like, what is your biggest impressions of focusing on kind of this narrow thing in pre-training, which is getting more memory by using lower precision while maintaining stability. So if you have any like high level takes on pre-training stability at that precision, then I’ll zoom into more specific questions on scaling up from there.
Chen Liang (26:00)
At first we heard about the floating point 8 from DeepSeek. They used floating point 8 training through the training of DeepSeek. And we also tried the recipe of them, the block-wise INT8 in the Megatron. And we find that actually the MFU (Model FLOPs Utilization) is not very high. And sometimes it’s even slower than the BF16 (bfloat16) training. And we find that the main costs are the quantization and dequantization. So actually, the floating point 8 is not as fast as they claimed, actually. And we profile the whole training data and try to minimize the quantization and dequantization process.
Nathan Lambert (26:50)
What is getting quantized and dequantized?
Chen Liang (26:53)
If you want to try the floating point 8 training, it’s actually due to GEMM (General Matrix Multiply) in the linear layers. And you want to quantize the weights and the inputs to FP8 (E4M3) type. But the other structure, they compute in the BF16, BFloat16 type. So when you get into the linear layer, you need to quantize it to the floating point 8, and then do the GEMM. And the GEMM output is the BFloat16. So this is the way you need to quantize and dequantize to adapt the other structure.
Nathan Lambert (27:43)
And then what does your work actually look like in getting this? So you find it to be not as fast. Like, what do you actually do to change this?
Chen Liang (27:50)
In the MoE layer, it’s got the FC1 (Fully Connected 1) and FC2 (Fully Connected 2), right? And in the middle of them, they’ve got the switch gated function. So FC1, switch gated function and FC2. And the output of FC1 is the BFloat16. And we fuse the operation of the switch gated function and the quantization function. So we fuse them, the two operations, into one. And so it saves some time. And the MoE layer is a batched operation. So you need to actually do the activation function on all the experts. So that’s a lot of time.
Nathan Lambert (28:52)
For people listening, FC is fully connected, which is just the standard neural network layer. So I might be being silly, but generally the idea with MoEs is that you have the feed forward layers, take up the most parameters and you get more efficient by adding MoEs. And within the MoE, kind of gated to each expert, is it actually standard that it’s like fully connected, MoE gate, fully connected? And it’s kind of alternating because I know this normally like attention block, MoE block is like the higher level of abstraction. And it’s this fully connected, MoE gating and then fully connected, is that actually industry standard? And I just had like a lapse in my brain.
Chen Liang (29:37)
This structure is conventional actually. Some experiments have explained that the switch gated can make your gradient stable during training. So it’s actually a standard architecture.
Nathan Lambert (29:51)
When you’re actually experimenting on this, is this the sort of thing that when you’re doing it at your like first models were about 300B total and you had smaller models? Like, is this a sort of thing done where you get this performance at every scale? Or do you have to revisit this when you’re doing something like Ling 1T, which is this latest model with way more parameters? Because I think the root of my question is like, are the numerical problems you get from scaling like whack-a-mole, where it’s like an old problem that you fixed becomes a problem again? Or is it an entirely new type of thing that comes up when you’re going to big models?
Chen Liang (30:26)
We do the experiment on the size of 100 billion parameters first. Also the situation can be, we can learn from the situation. That size, not just the 1T.
Nathan Lambert (30:43)
And I remember reading, I saw that you guys did QK norm for this as well. Is this just like, you also found this to be standard and work for you because we’ve had some issues with long context and doing QK norm kind of hurting performance there. We still have some ablations to track down.
Chen Liang (30:47)
We actually do the experiment of the QK norm on BFloat16 and the result comes out. The loss is better than if you didn’t apply the QK norm. And actually the one big thing is that when you do the floating point 8 training, if you do not apply QK norm before the rotary embedding, the gradient of the linear QKV may be underflow. Most of the time, it’s underflow because without the QK norm. So if we want to apply the floating point 8 training, you need to add the QK norm to avoid the quantization error. Since the quantization error is propagated from the last layer to the first, and if the last layer got more quantization error, until the first layer it’s amplified error.
Nathan Lambert (32:07)
Let me try to talk through this because I’m mostly working post-training and I’ve heard all these terms and I want to make sure that we’re presenting a fairly clear picture to people. So in attention, you have queries, keys, and values. And these are big matrices that store many different things. And like generally with pre-training, the magnitude of the variables matters a lot because what you’re saying about like gradient flow. And if you have variables that are like too small, you might have no signal and too big or one thing. And what we’re saying is that, God, I guess what’s the order between, when you have, I guess there’s complicated things, which is like where the rotary embeddings are applied relative to the attention computation. And what we’re saying is that you have to put QK norm ahead of the rotary embeddings in this attention module, because then otherwise your gradients are too small when you’re scaling this or with FP8.
Chen Liang (32:53)
During the forward process, you got the QK norm and the rotary embedding, and then you go forward. But during the backward, but if you do not apply QK norm, the Q times K matrix may have large values. And during the backward, the large value may bring a large gradient. And when you do the quantization, actually divide the data by the max of the per channel, the max of the column. So some small values will be divided nearly to the zero. So when you do the dequantize, it cannot find the real value before the quantization.
Nathan Lambert (33:52)
That makes sense. I see. Like, what are you actually looking at to figure this out? Are you looking at like intermediate activation values when you’re scaling? Because I like training loss will only show you so much, or are you like seeing that the training loss is better or worse and then going to investigate this later?
Chen Liang (34:08)
The first is the loss is not right compared to the BFloat16. And we print the quantization error during the intermediate layers and find that without QK norm in the linear QKV, the gradient is too large.
Nathan Lambert (34:34)
I think that this is very good. It gives people a sense for like what the different things moving around when you’re looking at kind of pre-training research is. And then the other side of things, if you make a change and then you have a loss spike, you’re like, okay, then you have like a numerical stability issue. I guess like a loss spike that you can’t skip. So I’m guessing you have things where if you have a loss spike, you can skip some of them. But there’s some numerical stability you can’t get around. This is fun. I’m going to kind of keep rolling through this. I think that you’re also talking about how you have like different pipeline for training your MoE, which you described as like a heterogeneous fine-grained pipeline. I think that this is like, I would read this as matching your training architecture to your compute architecture in order to get a speed up. Because I think with MoEs and the communication bottleneck. So I think that it’s like, if you want to talk about the parallelism strategies you did to get pre-training to be efficient. I think it was also really interesting because it covers multiple layers of the stack and how you design models.
Chen Liang (35:39)
It’s actually a common way, not just for our model. So actually the modern parallelism is just data parallel, tensor parallel, pipeline parallel, and context parallel. And our optimization is only focused on the pipeline parallel. As you can see from the paper, we do not use TP during our pre-training. So the common way to do the pre-training is they name it one forward and one backward type. Let’s see. We just focused on one machine with eight cards. And every card, actually, we name it as a stage. So we got stage 0 to stage 7. And every stage does the forward and the backward after it does the forward and sends the forward data to the next stage and they get the backward data from the next stage, right?
Nathan Lambert (36:49)
So that’s like an eight step pipeline. That’s like a pipeline parallel that you’re describing.
Chen Liang (36:53)
And every stage, they do communication from the prior stage and do the communication with the next stage. And the 1F1B got a problem that the stage 0 and stage 7 always got the most computation load because stage 0, you have an embedding layer. And it’s an index select operation. So it’s close. And stage 7, you got the LM head layer and the loss function. And you also got a large GEMM. So you need to times the hidden states to transfer the hidden states to the vocab size. And the vocab size is always large.
Nathan Lambert (37:45)
How much fine-grained work are you doing to change which part of the model is on each stage? Because that seems like what it would be then. You either have to change the model or you have to change how you split up the model. It’s like your two options.
Chen Liang (37:58)
The common way is just you split the LM head layer and embedding layer and just divide it by the GPU number. So it’s natural that the stage 0 and the stage 7 got much more computation load, since you just ignored the balance of the system when you split the layers. So it’s the common one. So our optimization’s main concern is just to alleviate the computation load of the stage 0 and stage 7.
Nathan Lambert (38:25)
I see. I guess I don’t fully follow like what has happened. I’m trying to be like very clear of whether or not I understand it. Because I think that’s like in a dense model, I think pipeline parallel really makes sense, but you have like a smaller model. And then as you’re getting bigger, it’s like much less of a model. I don’t know what it means to necessarily like de-load the specifically the embeddings or the loss function and how much of a change you can make. But I think that might be like a me limitation. It might be hard to get to, but you can, I’m curious if you want to try.
Chen Liang (39:14)
Actually, it’s quite the same as the dense model. The only difference is that per GPU, you can imagine that during the pre-training, if we got the 32 experts and we use like four machines to gather the expert data, it’s just you can view this four machine as one machine. So in this view, it’s the same like the dense model. So just imagine the dense model. You split the layers according to your GPU cards. And let’s assume that every machine got two layers of the dense model.
Nathan Lambert (40:11)
So I get that. And then it’s like, it’s just like, then you have to shift things around to make it so the loss is less of a bottleneck in the last layer or the final part of this pipeline parallel being the bottleneck is kind of potentially fundamental.
Chen Liang (40:24)
Yeah.
Post training at Inclusion
Nathan Lambert (40:25)
I see. I mean, the next question that I wanted to ask is going to be very related to this, which is like, what are your, how do you scale this to make RL work at the same scale? So the different problems that you have for doing pre-training versus RL with a large scale model. I don’t have the title of the paper, but you’re like in this Ling 1T paper, there’s a ton of RL details. And it’s like, is this kind of just like the next sequential problem that you got to? And then there’s just a lot of, not necessarily similar solutions, but like you’re doing your problem solving in the same way to make RL work rather than pre-training in terms of throughput.
Chen Liang (41:03)
It’s actually got some common tricks like we mentioned in the paper that the VPP (virtual pipeline parallelism). It actually means that the machine, you got double layers than the original one, than the original 1F1B, same things. But the difference is, let us assume that the stage 0 machine got four layers. But actually, during the time, two layers are doing computing and two layers are doing communication. So that’s what they call VPP.
Nathan Lambert (41:47)
What does two layers computing and communicating mean?
Chen Liang (41:50)
In other words, some layers are doing computing and some layers just prepare the data. They get the data.
Nathan Lambert (42:00)
I see, so it’s like some machines.
Chen Liang (42:03)
So when you train, during the computing, communication bandwidth is idle, right? So they utilize this to just like the exploration is the exploration. And our optimization is just to split the pipeline more precisely.
Nathan Lambert (42:31)
So I think I’m seeing that. So it’s within a node. You have very fast communication between eight GPUs. And then in pre-training, you’re kind of doing all sequentially, but in RL, you need to kind of sync this. You need to communicate more between your like generate, you have to move your weights to be able to generate when you’re doing RL. There’s like this sync step. And then I’m thinking what you’re saying is like, you have this chunk on eight GPUs and then you can split this. So half of them are doing compute and half are doing communication at the same time. So it kind of alleviates the bottlenecks. I see. For context and how like there’s a lot of different ways of doing RL infrastructure, it’s just the abstractions that like what we’re doing is much easier where we’re looking at approaches where we have GPUs that are set for generation and training, and that we are primarily looking at ways to make those both faster and then be able to throw the like training GPUs, we sync the weights to the generators and the generators just keep going where this is like it’s much more deeply embedded in the architecture where you have like one cluster where you’re kind of splitting the GPUs and what work is happening across each of the across like the per node basis when you’re doing this RL training. And I’m going to go look at this in more detail.
Chen Liang (43:48)
Yeah.
Richard Bian (43:56)
Just to add a little bit more flavors to this, the reason why we kind of didn’t really cover a lot of post-training details in this interview is because we have some additional technical papers or technical reports we’re writing at this moment about the system.
Nathan Lambert (44:14)
That makes sense.
Richard Bian (44:15)
So it was to some extent intentionally vague, Nathan. But I mean, first thing first, the current paper of Ling 1T and Ring 1T does have the fundamental intro for our system. It’s called a system. I believe the article has been published on ant-ling.medium.com/ on the medium technical paper as well as on Ling Team. So the paper is also available in English on Ling Team as we publish all the details. So specifically, there are several things which we did for the RL aspect. One is about the system itself. You can imagine that we do have an optimized internal hybrid engine which does all the things you described. And the second part is we’re exploring the reward model system. So this reward model system essentially requires some additional design to reach a certain level of parallelism. And the way we’re kind of looking into that is we’re really trying to set up meaningful rewards by doing a parallel structure for that. Last but not least, we have the term called LPO (Language-level Policy Optimization), right? It’s a linguistic unit. So we decided to choose sentence intentionally. So it’s kind of like a different approach from GRPO (Group Relative Policy Optimization) and the GSPO (Group Sequence Policy Optimization), like the session approaches or the token approaches that some of the other labs are using. We intentionally chose language as a linguistic unit to explore the meaning of this. So far, we’ve been seeing very motivating results from doing that. The training stability and the generalism is actually, we see some pretty clear numbers indicating that the LPO can be a very viable option for RL training. So let’s maybe save some of those interesting dessert for our next conversation. And we would love to really be able to share a lot of those details, given your background in post-training. I will try to maybe invite some of the experts from that domain into our next conversation.
Nathan Lambert (46:10)
I think the LPO thing is interesting, that there’s kind of a natural abstraction in a sentence. So in the language model generates, you just split every generation per sentence or per punctuation mark. It’s very linked to kind of these ideas of process reward models that people have looked at and understand to have natural inductive biases for a long time. And there is still some research doing this. So I’m happy to see that you’re doing it. And it’s kind of, I think of it as like value models and other things in RL that are just out of vogue and are likely to come back in some form in the near future, which is cool. In the ecosystem, where do you see open models going? I think it’s like, I guess the high level question is like, I mean, this weighs heavily on myself personally, it’s like, do you think that it’s like a big cake that you can eat out of and everybody does like, is it like, you see a clear path to having models that are meaningful? Does it worry you that the list of handful in China, it’s like, I mean, we know DeepSeek, we know Qwen, we know Kimi Moonshot, we know GLM 4.5, Meituan is releasing good, very strong models right now. You guys are like, the conviction that this is like a winning thing and you have your niche and there are more models coming soon. Like, is that easy for you to see? I mean, you had your metaphors at the beginning that I thought were great. So I think that’s kind of partially answered, but it’s like, it’s a very competitive space. So is that like easy for you to see through and just keep pushing ahead?
The Chinese model landscape
Richard Bian (48:15)
Thanks again for the invitation for really having this conversation. I did actually have my lines at the very beginning. I kind of call myself as a global citizen. Some of the current, I would say, really pains me in that regard. So when I’m kind of looking at it, so first thing first, I’ve been doing open source for years. You did ask about Ant OSS. You can actually find Ant OSS on Twitter. And there’s also a website for that. It’s opensource.antgroup.com. So Ant Group actually has a very long history of doing, as we call nowadays, the traditional or the classic open source, quote unquote, which I believe will be there forever. And you did ask a very specific question about open source models or open models. Last year, this time, it has been a very heated conversation in the open source ecosystem. So people in the open source domain are saying that, hey, this is open-weights. It’s not open source at all, which makes perfect sense. Because if you think about the nature of open source, it has at least three entities which are critically important. One is code itself, and the other one is community, aka the developers and people around it. And the last one is license, which pretty much provides a common consensus of the, I would say, the most common denominator as people agree upon, which is legally viable. But coming to that license requires years of effort. So like last year, you do see the OSI is trying to come out with a definition, and people are having a very convoluted feeling about it. And we see the Linux Foundation and data release this model openness framework, which is a very viable way of measuring the models. But that’s sad. Even nowadays, we only see one class one, which is a model from BAAI in China, which means by that standard, the rest of the models don’t meet it. And funny enough, last year, when I say we’re open sourcing our models, you’ll see people begin pointing fingers. Hey, you’re not open sourcing your models. Be careful about the words. But this year, all the labs are saying we’re open sourcing our models, and nobody is pointing fingers at all. Because it’s just like getting to a situation that we should maybe care less about this, but more about the direction, or what’s next. So I definitely want to spend more time discussing about that. So first thing first, I will say I did use the metaphor of saying the LLM is more like kernels. So if we kind of think about how many Linux kernel developers are on the planet now, it’s probably less than 1,000 people. So when people are saying that, hey, LLM is not really open source because nobody can contribute to it, yes, that’s correct. It’s very similar to the kernel. Theoretically, you can contribute to the kernel. But in reality, there’s only so few people who know about it. Most of the people are really kind of working around the ecosystem. They’re not the kernel developers, but we are currently at the stage of building the kernel itself. So that’s basically maybe my first point. It takes time. The reason why the open source definition is so convoluted at this moment, maybe just because it’s the first or the second year of a new era of neural development.
Nathan Lambert (51:54)
I agree. I think it’ll take like a decade. It’s like we’re in the first couple of years. I reiterate strongly with what you say where it’s like, it’s much better that people are actually using these models than just getting annoyed about definitions. And it’s like, we’ll figure out the definitions much more quickly if people actually want to use and contribute to these things.
Richard Bian (51:58)
And then the next part coming after this is like, I’m just sharing a very interesting story because I mean, my previous leader, he was working on Kubernetes and containers. So I have a background of being a full stack engineer as well as an engineer working on the data infra of the platform. So one day we did have a conversation about, I was saying, hey, you know, this MySQL infra, because I stopped. MySQL is not infra. MySQL is application. I was like, OK, thank you. That’s very helpful. But it’s kind of interesting, right? Because if you think about why that particular conversation actually happened, it’s because if you’re perceiving this from the infrastructure perspective or if you’re perceiving this from application perspective. My hunch feeling is we are going towards the next stage as we speak right now. I think we are at the transition period of having this MySQL moment. So other gigantic sandbox, gigantic runtime at this moment, that seems more application related. But five years down the road, they will become infrastructure. So the way I’m kind of looking at it is like, first thing first, I’m very optimistic about that. We will have open source. We will have an ecosystem in the AI era. In fact, I think Matt White from PyTorch, I think he introduced this new license called OpenMDW license, which kind of begins treating.
Nathan Lambert (53:53)
It’s an underrated license. It’s a very, very reasonable license.
Gaps in the open source ecosystem today
Richard Bian (53:59)
It’s very reasonable. In fact, I mean, we’re writing some Chinese articles trying to, I mean, I’m working with Art Eagles to do that. It deserves better visibility and more promotion. But kind of back to our original topic, I guess is, again, it will take quite some time for this information to rinse and repeat and consolidate. But I guess at this moment, I do see three gaps, which will prevent us from going to the next step. One is a proper license structure and a proper governance around the license. I think the OpenMDW is a good start, but it will take time. Second, I do believe data is the new code. So I guess how you’re contributing to the LLM is really through the data of pre-training and your data and reward models in post-training. But at this moment, there’s no Git for data. And the Git for data is not as straightforward as a Git for code because data can really be something which is very fundamental. So for instance, I mean like.
Nathan Lambert (55:07)
It’s often impermanent too. So like a lot of multimodal data sets are released as links and then the links die. So it’s like even like we try to, like people at AI2 try to release a fully reproducible data set and 10% dies in the first three years or something like.
Richard Bian (55:12)
And you might be having a lot of, I would say, overhead cost behind the scenes. So I mean, thanks so much for doing that. I mean, when people do that, we’re kind of raising our hands and saying hallelujah, right? Thank you. But it’s a difficult job, right? Because there might be legal battles behind the scenes. There might be a lot of, I would say, data cleansing. And the worst come to worst is really just more like, so I sometimes use this metaphor like, you know, I say, buy Coca-Cola stock. And Warren Buffett is saying, buy Coca-Cola stock. It’s literally the same word, but they mean something intrinsically different. I can’t really get my buy Coca-Cola. But I mean, that’s also a legal problem. So it’s like, in Git, we can say this, your public study was in main is before my public study was in main. But in data, you can’t really say that. So there’s definitely some technical challenges associated with that. Last but not least, the reward model associated with our contribution and the causality of our contribution to the model to the actual rewards. So for instance, if I’m writing a PR on GitHub, people see my PR and they merge my PR, great. I did my contribution. But you know.
Nathan Lambert (56:43)
I see.
Richard Bian (56:46)
Our conversation today is really meaningful. It can be a good, I would say, data corpus for reinforcement learning to some extent. But when people do that, they will not tell you, they will not tell me, they will not tell anyone of us.
Nathan Lambert (56:54)
I’m lucky enough to be big enough and visible where I accept that like me being in it is now good because it reinforces that I’m visible. Just a technical note on language, you were saying reward model as in the thing that rewards people for participating. Reward model is also like a technical thing, which I’ve done a lot of work on. So I was slightly confused, but if there was anybody else that was confused, that’s been clarified. To kind of zoom out, I think that listening to you, it’s like, wow, you’re one of a few people that is totally up to date on the open source definition stuff in the world. And I’m sure there are people all over that are thinking about this. I think you’ve spent a lot of time in both cultures and it’s like, where do you feel like people in my seat versus your seat may see things differently with like what open source AI means, what AI means generally, or like anything in this space that you feel both in your job or your life with respect to AI.
Richard Bian (57:58)
It’s a lovely question. I think it might be too big of a question, too. So I’ll probably answer that through two focuses. One is about open source ecosystem overall, like my feeling of being an engineer by training and global citizen, how I perceived open source ecosystem in general. And the second part is about the Chinese AI ecosystem. So we can tailor on that. So I will say first thing first about the open source ecosystem in the West and in the East. The first thing first, there are definitely more similarities than differences. I’m not sure if you read the book called Alchemist. It’s one of my favorite small books.
Nathan Lambert (58:42)
I haven’t actually read it. I do own it, unfortunately.
Richard Bian (58:45)
Well, congratulations. You have a nice book on your waiting list. It totally worth it. Another fun fact is I used to be working at Square. And the Square’s core payment system is called Esperanto. When I was looking at the word, I was like, what does that mean? And days after, I learned that Esperanto is basically this terminology related to world language. So there was a time people are inventing this term called Esperanto, hoping to connect the human beings altogether by speaking the same language. But clearly, it didn’t work. But now, Python is probably the real Esperanto to my best knowledge. So that’s why I’m saying that there are definitely more similarities than differences, because in open source domain, people are working together. Python code, JavaScript, speak English, they share their ideologies and meanings about technology. It’s all good.
Why China is winning the open race
Nathan Lambert (59:47)
A spicier way to phrase this question is like, why are there so many more open research labs in China than the US? I think like both, US arguably has like a bigger market cap, but fewer in people tech ecosystem. And it’s like, why is, it’s like, I listed what I thought was like 20 reasonable, like there’s like twice as many reasonable contributors in the Chinese ecosystem than in the US. Do you think there’s a reason for this or is it just kind of how the dice fell?
Richard Bian (1:00:11)
Well, I mean, I have my perceptions. Allow me to maybe use a disclaimer. So this is only my perception, not my company’s. So it kind of feels like there are definitely, there might be as many AI research labs in the States too. For instance, I mean, only through you, I learned about AI2. And I mean, I used to be living in Bellevue for years, but I didn’t know such an institution exists. So this is how uninformed I was. And I would imagine that there will be very much similar people like myself who are underinformed in that regard. Truth being told, we do see more open AI labs in China this year. I would say there are two reasons behind that. One is model effect. I would say that people are kind of perceiving the success of DeepSeek as a role model. That’s, I would say, a general consensus. It’s probably also a global consensus at this moment. People appreciate their engineering excellence and their willingness to share their findings. Because again, if we’re just out of Lisbon, we would appreciate the ship who came back and tell us, hey, this is the wrong way. Go that direction. We’ll probably appreciate that. So it’s not a zero sum game. So we cannot really speak on the other’s behalf, but we clearly see Alibaba with Qwen and Ant Group with Inclusion AI, we’re doing the same thing. We know it’s a long journey, it’s all the same. So when you’re outside of Lisbon, the best strategy to do is to be open and be helpful. And people appreciate the individuals who actually help you journey rather than the individuals who applaud you after you became famous.
Nathan Lambert (1:02:05)
I think I approach AI with this sort of curiosity. I think the, I don’t know how this would be a good test is like, there’s a very, the colloquial term of the hour in the Bay area and like tech circles in the US is like locked in. And if you apply this to what the AI companies think, it’s like the AI companies in the US are really, really like, at least acting as if they are locked in on a discovery in the near future that’s going to be transformative. A lot of it is probably for fundraising, but it’s like, I think that’s like, I have a lot more to learn and I will talk to more people like yourself to pick up more of this from talking to Chinese researchers. But I think this might be a recurring theme of like a lot of the US companies have this marketing that is really just different as how you’re describing it. And it’ll be interesting to see if that keeps coming up. Because if you’re so focused on like a one to two year thing, you’re not going to like sharing is a very different action to give. And then it’s like, it’s very different.
Richard Bian (1:03:07)
From a single perspective, I mean, just being told that by spending quite some time on both sides, I would say what we observe nowadays is reasonable, but definitely not ideal. So I would say first and foremost, you know, the chip leader is actually having a different way of playing the game, which is reasonable. I would say that, you know, if you’re the chip leader, there’s no guarantee that, you know, we’re going to be playing the same game. That being said, you know, it’s, we don’t talk about such a hypothesis because you cannot prove or disprove it. But that’s basically the first thing. And the second thing is we’re definitely seeing there are intrinsic, I would say, risks with the direction we’re going. So you hear people talking about the transformer architecture, we’re actually raising. You know, with all the names, they begin claiming that the pre-training might be dead. We hear terms like that. Reinforcement learning is the way to go. But in the latest interview with Andrej Karpathy, he shared this in a very humble and noble way, saying that, hey, this might be a good way to go, but let’s not mythify this. It might not be the golden desire, or it might not be the silver bullet. It’s a good methodology. Let’s go down that direction and explore, rinse and repeat, hoping that we’ll be able to find it. So if we’re at this stage of the game, I would say I would definitely choose the game to be more, I would say, open-minded. That’s one thing. And from a strategy perspective, be less about zero sum and more about where. So in game theory, there are all these kind of different games. One very typical mistake people make is they will treat a stag and hare game as a prisoner dilemma game. Those games look very similar in their own Nash equilibrium, but they’re different. So I guess, I mean, we do see certain companies are playing more like, hey, you know, you win, I lose. Can’t comment on that because, you know, there are a lot of reasons behind it. But, you know, the way we’re kind of looking at this, there are definitely more rooms, even as like Columbus was the first one finding the American continent. But then we begin to know that there’s this kind of North America and South America. And there are a lot of settlers, a lot of places. Right, so you don’t want to be the first pirate on Atlantic Ocean to kind of begin shooting down the other ships before you even reach and disembark. So that’s basically my way of seeing it. Last but not least, I guess I mean like.
Nathan Lambert (1:05:37)
There were a lot of settlers out there other than just Columbus. To finish your metaphor.
Richard Bian (1:06:03)
I think at this moment, there’s also another intrinsic risk associated with the whole business model. We hear a lot of those discussions regarding how Nvidia is actually making a lot of money by just selling the hardware. I also saw a line yesterday which I really like. It’s like, hey, do people still remember Cisco in 2000? I was like, that’s a very powerful line.
Nathan Lambert (1:06:27)
I think a lot about how Claude Code is very different than the likes of GitHub Copilot. And it’s like the different products that you can make with a given model has very, very big Delta in terms of what the user gets out of it. So mostly the floor is yours to comment on anything fun with product, which is probably a lot of your actual day job. I get, this is not my day job. And I get the sense that people that care about AI have to do a lot of work like this of like vision, creating a vision. And I’m guessing product might be closer to what you spend your time on.
Richard Bian (1:07:01)
Thanks so much, Nathan. I really enjoyed the conversation today. So the Model as Product team is very new. It’s brand-new. It’s only one month old. And as far as I know, we are the first company building such a team in China, if I’m not mistaken. But I have a hunch feeling that’s how people in OpenAI are working nowadays. So people are kind of working in small squad teams with seven to eight people. It’s a combination of algorithmic engineers, system engineers, UX engineers, product developers, evaluators, and so on. So we’re all working together.
Nathan Lambert (1:07:41)
Did you launch this before or after Sora? Because Sora is a complete vindication of this, which is like the genius of Sora is adding your friends to the videos versus just having a good video model. So you may not have realized it, but I think you have a great example of reinforcing this hypothesis. And I think more of them will come because I think, I don’t know, I’m soapboxing, but I think 2026 will be there will be more things that we can’t predict like Claude Code and Sora every year that start to work. So I think it’s a good approach.
Richard Bian (1:08:12)
That’s precisely how it works, right? Because working in open source for years, I guess one thing I learned is like, you know, if you just begin selling, I mean, there’s, you know, one of my favorite speakers is Simon Sinek, and he has a very popular YouTube video talking about leadership. So in there, one of his lines is like, leadership is volunteering. I really love that line. So basically, I’m pretty much one in my time and my predictions of trying to build such a team. So what our team does is like, because we are the Ant Ling team, right? So we care a lot about the model itself. That said, there are a lot of models out there. So in order for it to promote the model nowadays, it’s intrinsically difficult because people will say, oh, OK, here’s another model. Oh, it’s an open model from China. Oh, there are so many open models from China. It’s big, great. I remember that. But what’s next? So how can we use it? So we were kind of looking at just how we discuss about MySQL. If MySQL is a platform or an infra or product, I would say that we really want to think model as product now. Because you have all these models. But the good news is you also have the infrastructure, which allows you to switch models very easily, like open routers and all these model service providers, they actually allow you to do that very easily with very low overhead. You can use one model for part of a scenario and another model for the other part, which is good. It essentially means that if you have a good enough model, so I mean, thanks so much for our engineers who are actually building such a model for us to use and, you know, pretty much work upon. Without such a model, it’s impossible to do anything. So now with such a model, it almost feels like you have a very smart individual with IQ equals to 120, but he’s not very well-trained with anything. So what we’re trying to do is we’re trying to really find, during the interview with the model, and say, hey, what are you good at? But do we really know what the models are good at? Honestly, at this moment, it kind of feels like the evaluations are not really there. There’s a long way for benchmark evaluation. We don’t have enough time for that. But I believe that eval-driven heuristic is probably going to be very interesting in 2026. We’re going to essentially use an eval-driven way of finding what the models are good at. It can be very specific. It can be very niche for creative writing, for example, in drama, storyline. It’s very specific, but it can build a very good product on that. We’re trying to find all of those. But at this moment, we need the evaluation data set. We need all of this in order for us to be able to find it. And on the other hand, we need to find the user value. Because even as of 2025, you begin seeing a lot of new products coming out, but only a few things settled. So it almost kind of reminds me at the very early stage.
A metaphor for our moment in LLMs
Richard Bian (1:11:12)
I don’t know, Nathan, if you remember the product called Foursquare from the very early days.
Nathan Lambert (1:11:32)
I don’t think I was a man of the internet at the time, but I’ve heard of it as being like a canonical reference many times. It comes up in a lot of the readings that I do.
Richard Bian (1:11:38)
So the TLDR for that is Foursquare is basically one of the earlier applications when you have an iPhone. All it does, it gives you a location of your current phone, and you’re able to do a check-in action in there. So for instance, if you go to a restaurant, you can do a check-in at this restaurant. So what it does is actually it’s a demo of the location API of iPhone. And all it does is data labeling and a demonstration of how you can use the location API to be useful. But without Foursquare, you would not really have Uber or like DoorDash and all of those. So Foursquare was pretty much the demo, which led to all of these new products. And another way of putting that is like, you don’t have to be a taxi driver to build Uber. So that’s basically how our team is. We have a very small team. We have a very small team with engineers, product managers, and operational folks. So what we’re trying to do is we’re trying to essentially build Foursquare by really focusing on what the model is good at and what are the core capabilities. So I think there are definitely some of these demoable core capabilities which kind of begin surfacing. One of them is unlimited memory. Unlimited memory is basically this new capability which only AI and gen AI can fully utilize. But do we, so for instance, you have this kind of new products like the cloud note which you can put behind your phone, right? You can put a note there. Oh, I think there’s a company called unlimited.ai (editors note: called limitless) if I’m not mistaken, which is basically the necklace you can put. And people kind of building like watches, rings, glasses, and all of this in hoping to gather the data and trying to pretty much put all these kind of new contexts into the model. I kind of condense those into two core capabilities. One is unlimited memory. It memorizes everything. But in order for us to do that, you can’t really save all the data, right? The data is huge. You have to compress it, being able to find out a nice way of compressing them, and a very nice way of retrieving them. So data compression, data retrieval, called hot storage for all of this data, they’re all new challenges. But the capability is real. So with Unlimited Memory, it will really enable this contextual engineering work, which you can use in Model 4, but it’s not there yet. So it can be a Foursquare moment for the LLM. And the second one is, I would say, the proximity awareness. So for instance, we’re speaking in the room. There are a lot of these kind of new applications which are recording our meeting. What they’re really recording is the meeting, yes. But what they’re also recording is who is sharing the meeting with you. So theoretically speaking, you have sufficient amount of data. You can begin building the new LinkedIn in the gen AI era. It’s all possible, but we’re not there yet. So my team.
Nathan Lambert (1:15:00)
I think there’s a lot of pushback on privacy in the US to these things, but demonstrating the capability is obviously a huge merit of like, if we can figure out the privacy concerns, you have X on the table of new potential things. And I think it’s good. I encourage a lot of people to, it’s the right approach to things, which is like as the models get better, what potentially can work. I’m not a new person to saying this. A lot of people have.
Richard Bian (1:15:27)
Maybe just like two final words. One is like, I guess now is probably the best time to be more, I would say, first principle. Like, people say that a lot, but I actually have a three-year and ten months old boy at home. I guess one thing which really motivates me, what kept me being optimistic is my boy, because his growth is very well aligned with the timeline of the model. I’m seeing a lot of similarities in terms of how the revelations of human beings are kind of aligned with how the models are being trained, both pre-train and post-train. So I’m seeing there’s a long way to go. We don’t really have any understanding about, I would say human intellectual intelligence about where that’s coming from. So it’s a long journey and it’s good to really kind of think more fundamentally as the first principle. And the second line is I would say Inclusion AI and Ant Ling team, we’re being very serious about this. We don’t think this is a zero sum game and we don’t think this is Red Ocean. So I would say we’re open. We’ll stay open for as long as we can. And we’re doing all this kind of explorative approaches and I will probably make a call to action as someone who I’ve been benefiting a lot from globalization, including education and being able to work with smart people like you, Nathan. I hope the world will stay that way, at least as far as technology and open source is concerned. So that means work with us and Inclusion AI will be here. We’ll keep exploring and appreciate everything you’ve been doing for us. Thank you so much, Nathan. I really, really enjoyed this conversation today.
Nathan Lambert (1:17:15)
I look forward to seeing your new models. I have this, I’ve been so busy. I have one of these DGX Spark computers on my desk and I haven’t downloaded any real big model to it. And it’s like, I have to try downloading something like a hundred billion parameter model to see how it works. So maybe one of them will be your model. Thanks!
The first mention I found was a GitHub repo commit from February.
Qwen-Next uses Gated DeltaNet + Gated Attention.

