This article was written with a colleague from AI2, Jacob Morrison.
Since I’ve been working on AI there hasn’t been a topic that so many brilliant people have reacted to with a general response of WTF as that of model merging. The general idea of taking two model weights and smushing them together to get a new, sometimes useful, model out is having its moment in the sun. It’s a new way of experimenting with LLMs, which is especially useful to the GPU poor.
Model merging blew up over a year ago, and even probably before ChatGPT, when people realized they could merge different Stable Diffusion variants to fit their style of choice. Here’s an example from September 2022 on GitHub. There are countless | tutorials to do this and it’s easy to see the largest use case is anime models. While it’s a domain that is hard to directly monetize when designing an AI startup (unless you’re named Character AI), a large amount of value is going to be created by folks happily creating AI girlfriends. The question as to if you think people should be allowed to or recommended to do this is an entirely different discussion.
It’s not hard to find countless examples of this. There are HuggingFace organizations dedicated to “waifu and husbando research” that have more models and datasets than plenty of Fortune 500 companies. The Waifu Research Department is the most entertaining and visible example, which has a bunch of models that look like fine tunes on different anime characters.
As you keep digging here, it’s obvious that this transitions rapidly from toy projects to porn models. As for the models on HuggingFace that I found, most of them are unsavory, but not directly malicious. The same tooling can be used to create directly harmful (and likely illegal) content abusing the name and likeness of famous individuals with enough images of them on the web.
It’s easy to explore the space of model merges with a simple search of the term merge on HuggingFace. The ones of interest for this article are the recently emerging models that are attempting to get the best of both worlds from two fine-tuned models, e.g. a create code model with a great general chat model.
Interconnects is a reader-supported publication. Consider becoming a subscriber.
This post covers:
Some intuitions on what model merging is doing,
Why people are doing this,
Links to some models & resources, and
A visual literature review.
How and why does model merging work?
Editors note: in going fast and writing this, we may not have clearly differentiated the links and differences between weight-averaging in pretrained and model merging. I still think they’re linked, and the article still applies, but some research is TBD. I missed a taxonomy defining 2021 paper on Fisher-Weighted Averaging that builds indirectly on what I wrote. See this Twitter thread for expanded context.
Averaging for pretraining was inspired by generalization and the conversation today is more about capabilities, but these numerically are almost the same thing.
The Twitter exchange led to finding the 1992 reference, “Acceleration of Stochastic Approximation by Averaging,” which I thought was the real starting point for parameter averaging. This actually wasn’t the first. It turns out this above paper is also references revisionist, with the earliest pointer being an 1988 paper from Hubbert, Efficient estimations from a slowly convergent Robbins-Monro process. History got re-written when deep learning took off.
The recent paper that seems to have accelerated the modern push towards model merging, one of robustness and generalization, was published in 2018 and is titled Averaging Weights Leads to Wider Optima and Better Generalization.1 The authors introduce stochastic weight averaging (SWA) as an alternative to SGD or Adam in model pretraining.
There are two important ingredients that make SWA work. First, SWA uses a modified learning rate schedule so that SGD (or other optimizers such as Adam) continues to bounce around the optimum and explore diverse models instead of simply converging to a single solution… The second ingredient is to take an average of the weights (typically an equal average) of the networks traversed by SGD.
At an implementation level, they’re fairly simple ideas, but like with everything in ML, the details matter. Regardless, it’s the beginning of the model averaging wave. The post continues with intuition and great visualization of neural network loss landscapes (emphasis mine):
[B]elow, we show a visualization of the loss surface in a subspace of the parameter space containing a path connecting two independently trained SGD solutions, such that the loss is similarly low at every point along the path. SGD converges near the boundary of these regions because there isn’t much gradient signal to move inside, as the points in the region all have similarly low values of loss. By increasing the learning rate, SWA spins around this flat region, and then by averaging the iterates, moves towards the center of the flat region.
From the PyTorch blog post, which was created in collaboration with Javier Ideami (losslandscape.com)
At the core, techniques for model merging and weight averaging search for more robust solutions. Quoting the PyTorch blog for the last time:
We expect solutions that are centered in the flat region of the loss to generalize better than those near the boundary. Indeed, train and test error surfaces are not perfectly aligned in the weight space. Solutions that are centered in the flat region are not as susceptible to the shifts between train and test error surfaces as those near the boundary.
All model merging techniques we’ve seen today are about the same shifts in loss/parameter spaces, but on much more complex models and tasks than the CIFAR tasks where they originated. For more detailed intuitions on SWA and the foundations of model merging, I recommend checking out the authors’ paper, particularly sections 3.5, Connection to Ensembling, and 3.6, Connection to Convex minimization.
In fact, I reached out to the author of SWA and many other great deep learning works, Andrew Gordon Wilson, who provided this great intuition for what’s happening in weight averaging:
Averaging works in cases where the parameters you are averaging are oriented around a local region of low loss, helping to move the solution to a more centred "flat" solution. A flat solution, at a high level, corresponds to parameters that can be perturbed without significantly increasing the loss. These solutions generalize better, in short, because they provide a better compression of the data: they can be represented with fewer bits of precision. It's actually quite intuitive!
The bigger the model class, the larger these regions of low loss will be, because there are many more parameters that will be consistent with the data, and therefore the greater opportunities to benefit from averaging. Really big models are also hardly trained to completion, so averaging many checkpoints, or across multiple fine tuning runs, can help find more refined solutions more quickly. This is very related to a procedure called SWALP, which provides training in low precision by combining weights that have been rounded up with those that have been rounded down. Model soups works for exactly the same reason as SWA (and was very inspired by SWA) --- the fine tuning runs each have the same warm start and end up exploring a local region of space.
I’ll get to model soups and other methods later in this post. Another intuition that’s popular today is a theory of linear mode connectivity of model weights. Roughly, it can be explained as the following: Models that start from a similar position, or are fine-tuned in similar ways, end up in the same “region” of loss space, and linearly moving between them can usually get you a similar good (if not better) model. Now that we’ve gone far enough back, the links between SWA and the popular linear connectivity are quite evident – they’re just using slightly different language across the literature.
The last core question is: Can the weight-averaged models be fine-tuned to the same capacity as normal transformer models? In the literature, there don’t seem to be pointers that it can’t be done, but it depends on the quality of the merge and where in the loss landscapes we were studying the final model is.
Huge credit to Prof. Wilson for the quote and other links.
Aside: merging vs. ensembles vs. mixture of experts
It’s mostly a coincidence that model merging got popular roughly at the same time as mixture of expert (MoE) models. Lots of people online are merging different fine-tuned models, each with different strengths, and calling them “experts” that contribute to a final model. While this may be a more intuitive way to use the phrase mixture of experts, it’s not what it means. In fact, in the Mixtral of Experts technical report, the authors show that the routed feedforward layers in an MoE model don’t specialize to particular information. This gets even more confusing, as people are learning routing layers over learning LoRA adapters for a model, which is even closer to a mixture of experts model, but is likely to have very meaningfully different capability and deployment considerations.
Forcing multiple models together to become a MoE model like this is something that was much less supported by the literature, but crazy things are happening! The last thing, ensembling, is when you have multiple models and a method for mixing the outputs. They’re successful across many areas of ML, but come with an unavoidable inference cost penalty.
Why are people doing this?
What we have not established is how much performance, or what performance, exactly comes from model merging. In short, people have found everything from slight bumps on validation set accuracy to the integration of new behaviors or styles from a merge target.
Where the capabilities were first discovered is shared in the Reddit post, What is the point of the endless model merges? As is the case with many of the subcommunities for ML on Reddit, the answer was pretty reasonable:
A couple months ago, people discovered that merging custom models (like for anime) with the base SD1.5 or 1.4 gave really interesting artistic results that weren't possible with either model. Some merges are still useful but 90% of them you can't really tell apart anymore. People doing new training for their models are the real heroes.
This reveals the core truth of things: “People do model merges because it's easy. Just a few clicks of a button and you can release a new model. Training new models is hard, and so very few people do it; the tragedy of open source.”
When there’s an end goal in sight, it’s easy for people to throw a bunch of CPU time at merging models and seeing what happens. It’s the opposite problem of top research labs, where there are very few core people who need tons of resources to make real progress. On the internet, there are millions of people who will happily press go and see if they get pretty pictures out.
This is certainly a very weird area of investigation in ML, even for today’s standards. I found some great advice in this mergekit tutorial document (found via Twitter, as usual): “It sounds counterintuitive but the most effective solution is to load the individual AI models that you are using for your merge and ask them what their strengths are.”
Model merging, while once the domain of deep learning and generalization nerds, now is the domain of people just trying to find out what works. Alchemy strikes again. Merging takeslots of trial and error but does not take fancy clusters restricted to industry labs. It’s obvious we’ll continue to see a ton of it.
Until recently, merging different architectures (e.g. Llama 2 and Mixtral) was not on the table, but that’s changing in open-source and academia. This ended with Frankenllama (blog post here from August 2023): a 22 billion parameter Llama base alternative, was created to fill in the gap made by the 34 billion parameter model not being released. This blog post is indicative of the energy-making model merging real, with plenty of takes like “Parameter Sizes Aren’t Real” and “I’ll Do It Myself.” The model itself isn’t great, and can be salvaged with some fine-tuning, but is extremely indicative of what is going on in the wild west of LLMs.
I grabbed some examples from a Frankenmerge summary post:
Goliath 120B (Twin and Euryale, each which are Llama 70B’s)
MythoMax — a blend of Hermes, Chronos, Airoboros, and Huginn models.
Toppy — OpenChat, Nous Capybara, Zephyr, AshhLimaRP-Mistral, and more.
NeuralBeagle14-7B (on HuggingFace, announcement on Twitter) was a breakthrough extremely strong 7B model by merging 14 sets of weights (family tree below, from a visualization tool by the author).
Tools & Links
Mergekit: the most popular tool for using this tool (which is simpler than most LLM libraries when you dig into it) and a Google Colab for those wishing to lazily use it.
Of any subfield of ML I’ve dove into, model merging may have the consistently best figures. The applications of model merging are remarkably similar – pick an ability to focus on, merge with some tweaks, and benefit!
Full model merging and recent methods
What’s been getting the most attention has been these methods merging full weights like Llama and Mistral together. The literature has been charging towards this for years.
This paper may have introduced the term “model merging” along with the most popular methods that are being explored today. You can see the introductory figure below.
This paper introduces a new state-of-the-art ImageNet model through a simple finding that “averaging the weights of multiple models finetuned with different hyperparameter configurations often improves accuracy and robustness.” The key difference between this and an ensemble is that no inference time penalty is incurred!
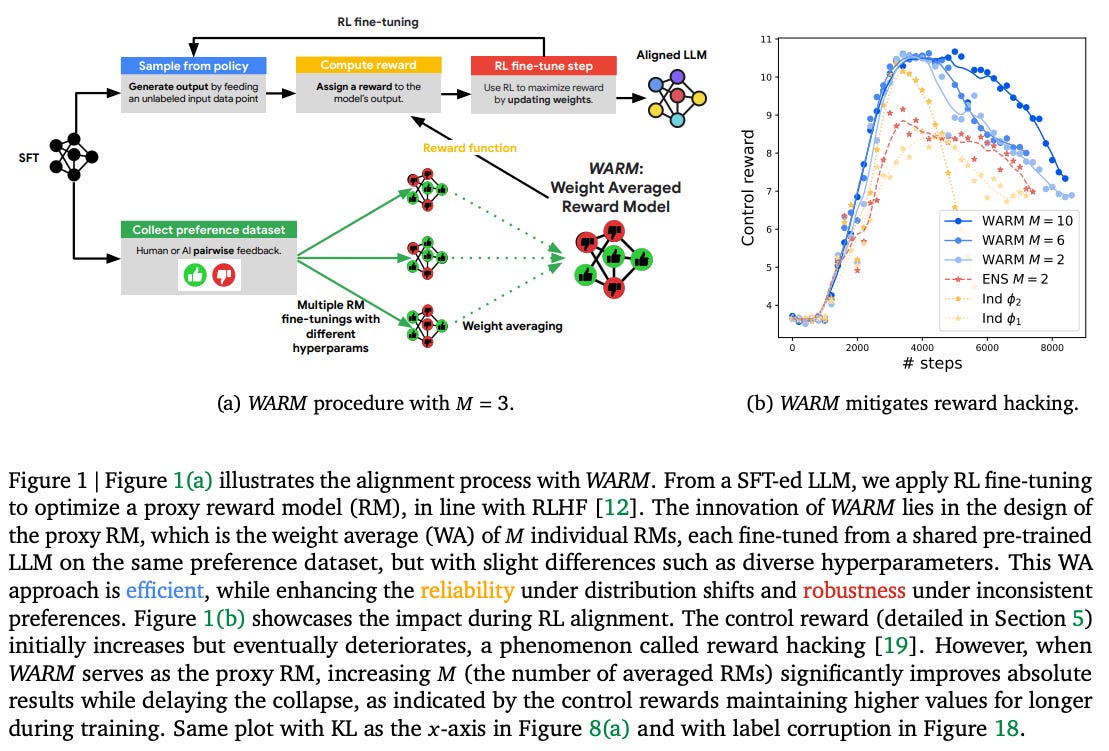
This paper shows that instead of needing to train many models on linear scaling of reward functions with a multi-objective RL approach, one can simply fine-tune multiple models with respect to each reward of the rewards and merge them. The actual reward functions are quite buried in the Appendix (don’t do this for core details!), but they tend to be quality evaluators by different reward models.
Jun. 2023: TIES-Merging: Resolving Interference When Merging Models This paper attempts to resolve parameter inference in model merging – where sometimes model merging results in dramatic performance drops in unexpected regions of performance. The abstract summarizes it quite intuitively:
In this paper, we demonstrate that prior merging techniques inadvertently lose valuable information due to two major sources of interference: (a) interference due to redundant parameter values and (b) disagreement on the sign of a given parameter’s values across models. To address this, we propose our method, TRIM, ELECT SIGN & MERGE (TIES-MERGING), which introduces three novel steps when merging models: (1) resetting parameters that only changed a small amount during fine-tuning, (2) resolving sign conflicts, and (3) merging only the parameters that are in alignment with the final agreed-upon sign.
They show it does well on T5 models compared to other methods, which is a start.
Oct. 2023: Model Merging by Uncertainty-Based Gradient Matching This paper seems to be addressing the same problem in TIES-Merging, but with a different solution. The paper has a lot of math that’s mostly over my head, but expect iterations on these methods in 2024. They evaluate on sentiment classification.
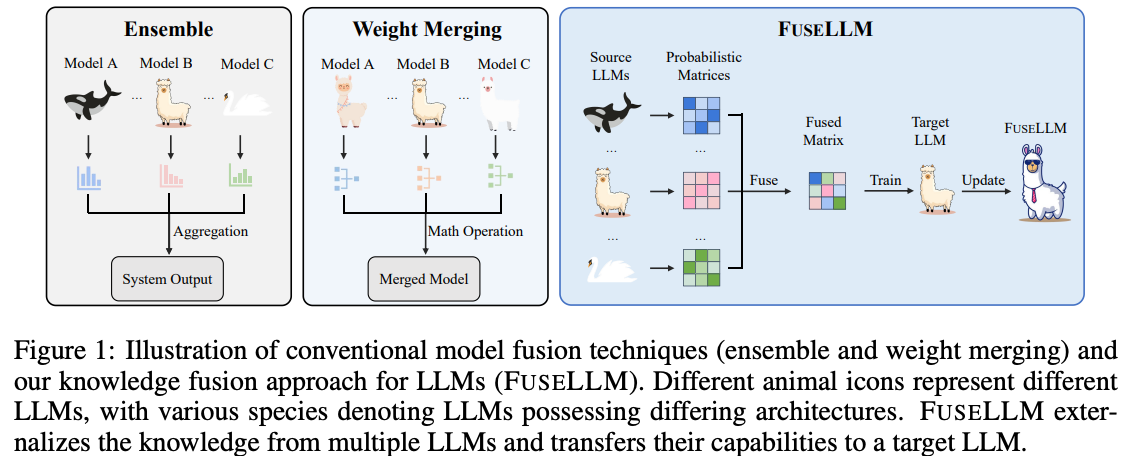
Jan. 2024: Knowledge Fusion of Large Language Models This paper isn’t quite model merging, but it’s inspired by the same direction. They collate probability information from popular models, select the strongest areas, and use that information as a training signal for a stronger model.
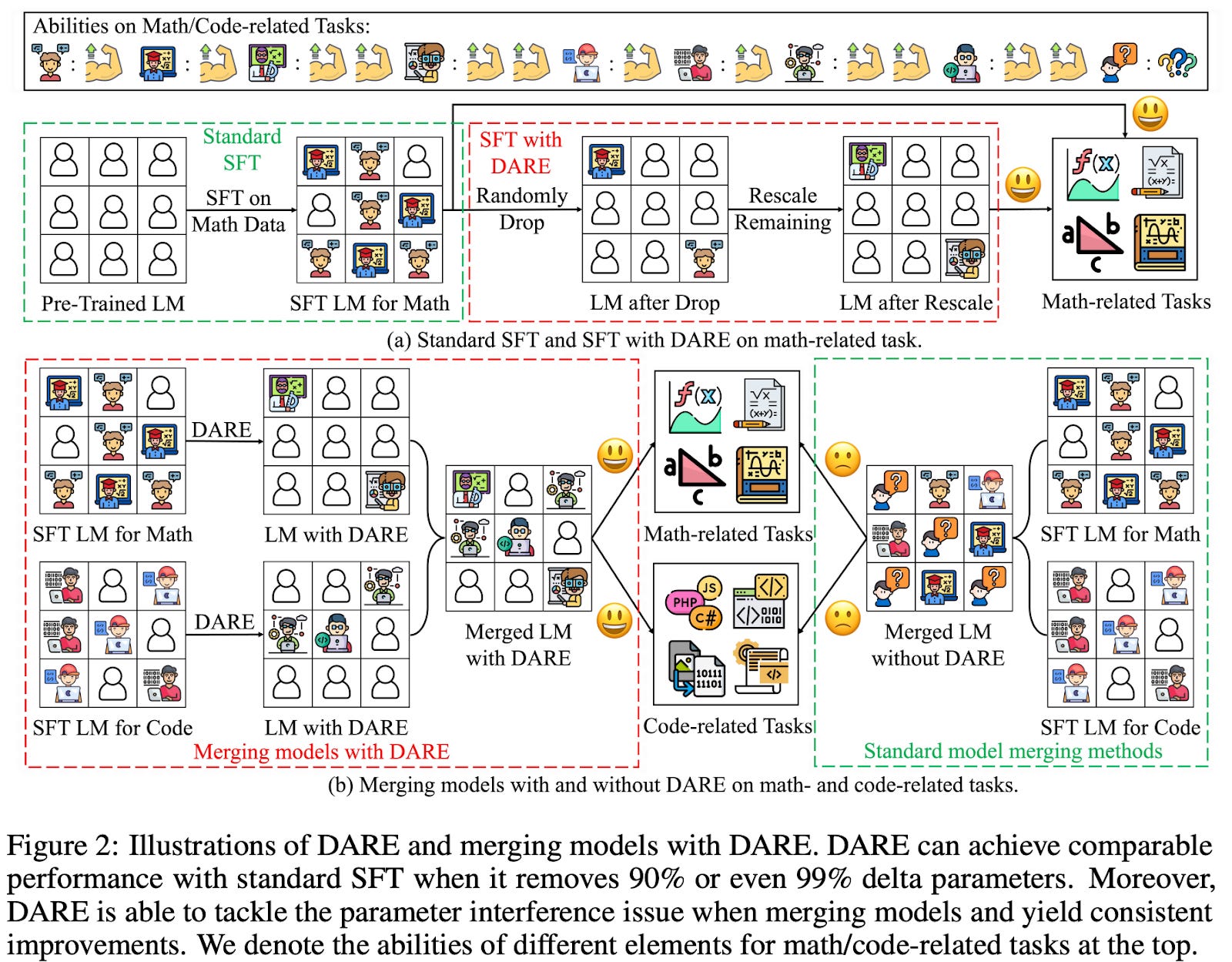
Nov 2023: Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch If you fine-tune a model, subtract out the base model (to get parameter deltas) and remove ones that didn’t train much, you can get the “most important” parameters for learning a task or distribution. You can then add these easily back into a model to give it some new abilities.
Not going to say I understand this figure, but it’s cool:
Weight averaging during pretraining
More work has continued from the SWA days. An explanation from Sunny Sanyal on the area as of today, edited for clarity:
Weight Averaging (as in tail averaging) works in LLM pre-training; by works I mean trains the model faster and generalizes better. Here's my intuition of why LLM's are trained with large batch sizes which necessitates high learning rates: In optimization time high learning rates causes many oscillations that affects the validation loss (generalization). To solve this issue we employed weight averaging to cut off this oscillation post optimization time.
Jun. 2023: Early Weight Averaging meets High Learning Rates for LLM Pre-training An updated method to build on SWA for the domain of training LLMs, focusing on higher learning rates and checkpoint averaging. Seems like a great resource for understanding how the field has shifted in the days of LLMs.
LoRA merging
This section is just showing that the crazy ideas the community experiments with are being validated in the literature.
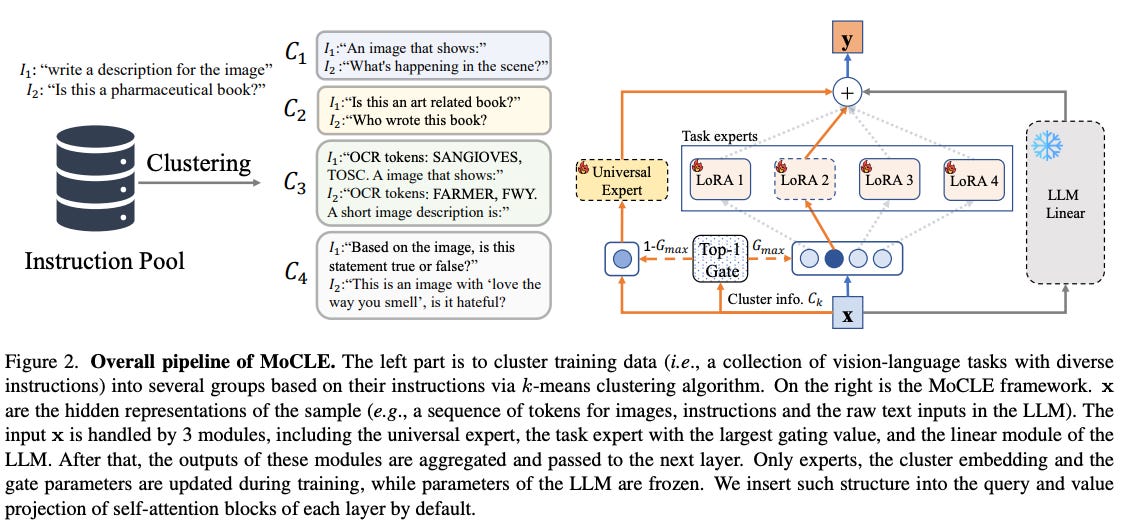
Anon. accepted to ICLR 2024: MoLE: Mixture of LoRA Experts This paper is similar to the above, and many mentioned models or creating not-actual merged expert models, where they join many LoRA adapters for different language abilities.
Applications (robotics)
I was pointed to some work on model merging for robotics, so I had to include given my background. Credit Daniel Lawson.
Sep. 2021: Robust fine-tuning of zero-shot models Fine-tuning a zero-shot model on a specific task, and doing a weighted average of the zero-shot and fine-tuned model can give you good performance on both
Feel free to send me more papers if you think they need to be included!
Audio of this post will be available later today on podcast players, for when you’re on the go, and YouTube, which I think is a better experience with the normal use of figures.
Looking for more content? Check out my podcast with Tom Gilbert, The Retort. On episode 17, Tom and I discuss his story through grad school and the shifting sands of the AI grad school process.
Newsletter stuff
Models, datasets, and other tools
A new 7B parameter non-attention LLM with even stronger abilities than Mamba (not sure if they compared to Striped Hyena)! Meet Eagle, built on the RWKV architecture.
Lumiere from Google showed awesome video capabilities. This scaling was only natural, as the model is just diffusion models getting BIG to handle entire sequence at once. It’ll help a ton with coherence of AI generated video based on how diffusion models iteratively refine the sample.
GPT4 Turbo addressed for laziness. The blog post’s directness is why you have to respect OpenAI a lot of the times. Curious if this needed a new pretraining: “Today, we are releasing an updated GPT-4 Turbo preview model, gpt-4-0125-preview. This model completes tasks like code generation more thoroughly than the previous preview model and is intended to reduce cases of “laziness” where the model doesn’t complete a task. The new model also includes the fix for the bug impacting non-English UTF-8 generations.”
Bard is moving up the LMSYS leaderboard. Rumors seem to be that this is from the model having access to the Google search API, while the other models do not. Regardless, Google is gaining momentum this year towards the Gemini Ultra launch. I still think LMSYS’s leaderboard probably skews towards role-play and code more than many other benchmarks, but you can’t beat user aggregated data.
A activation steering | repository popped up. I’ve been following this idea a bit recently, as it’ll soon be added to the in-context learning suite for RLHF. TLDR: by adding to activations in a targeted way you can influence model behaviors much like prompting.