

Multimodal blogging: My AI tools to expand your audience
A fun demo on how generative AI can transform content creation, and tools for my fellow writers on Substack!
This is a different type of post, covering products I’ve been building to make Interconnects the best and easiest place to consume AI content (via AI). Let me know if you have any feedback! Audio of this post is available on podcast players and video (my preference) is on YouTube.
A key part of being a creator is matching the content you create with the medium you use to distribute it. For a long time, the medium was largely decided for an individual subconsciously irrespective of the content they create. For whatever reason, people decide to be a YouTuber — it calls to them. In my case, I decided on blogging years ago, and now I’m okay at it so I stick to it. However, a lot of my content may not be consumed by the most new customers in the text format. Text works best for roundups and extremely detailed analysis. For many other ways of consuming technical content, from dunks to commentary, most consumers prefer video or audio when judged by the percentage of time spent there.
Before the proliferation of cheap and effective AI tools, conversion between formats was an extremely time-consuming process. Only professionals have the time or money to cross-modality boundaries. With AI tools we have today, yes not only those coming in the future, it’s seamless and effective to translate content into other forms. I’ve released the Interconnects tools for multimodal blogging that let you convert markdown to audio and video with a short grouping of Python scripts. The features are not free, though they could be converted to so with committed engineering on open-source models, but the price of $10-50/month is largely within the ballpark of fees that serious bloggers or content creators already spend on services and hosting.
I’m happy enough with my AI tools for generating audio + video from blog posts that I’m sharing this post in hopes that some more writers, particularly a few covering AI, decide to give it a shot. I’ve heard from multiple people that it’s much better than the built-in Substack voice. The key feature is that you can access it from the places you are used to consuming audio from!
The code with detailed instructions can be found on GitHub. For bloggers I already work with, collaborate with, or recommend, I’m also happy to spend some of my compute credits to experiment with building these features into your blog.
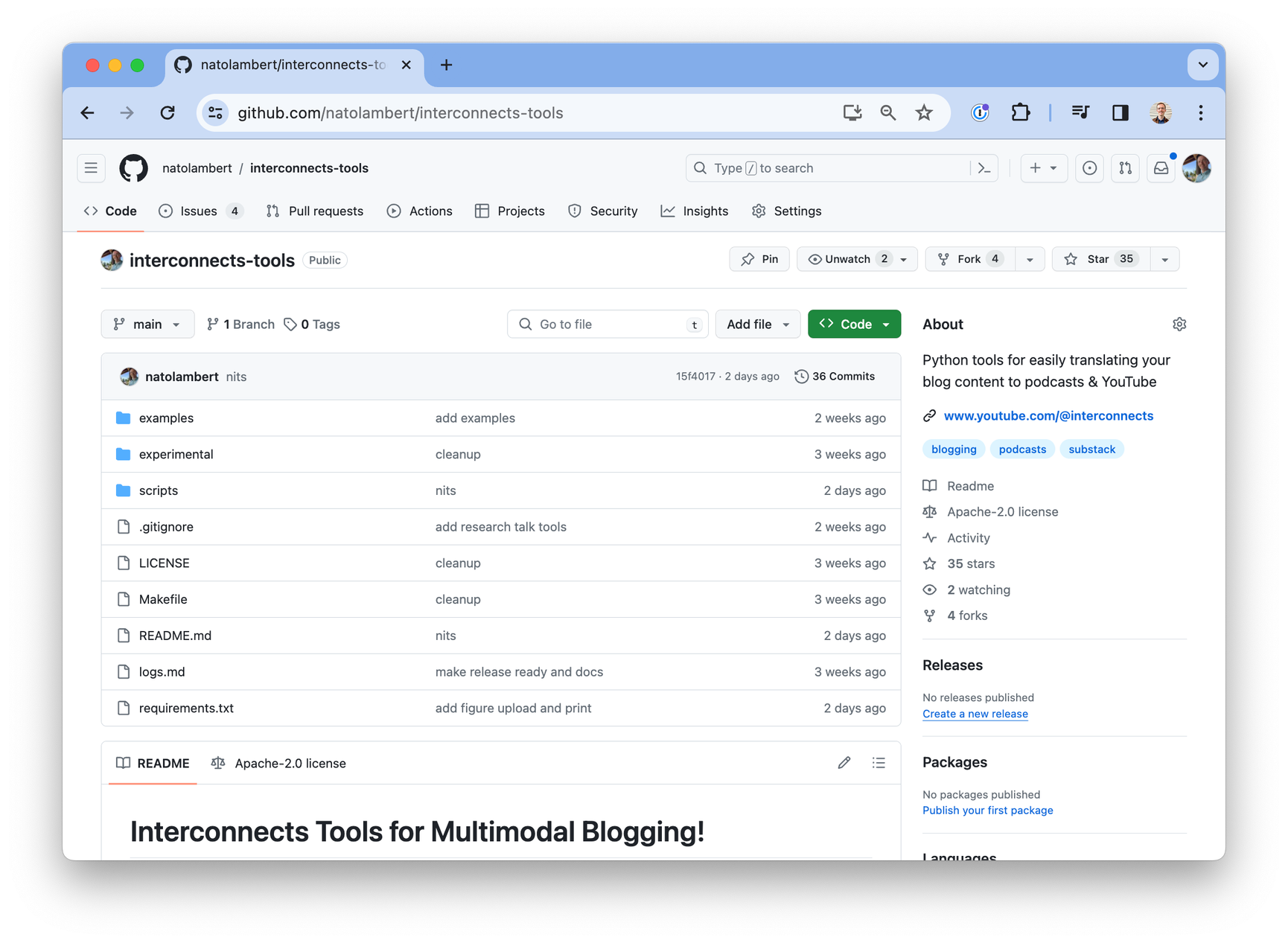
A summary of the workflow I’ve created, which takes 10 to 20 minutes to run due to DALLE rate limits (5 per minute) and video writing with MoviePy (also 10 to 20 minutes depending on length or resolution), is much, much easier to work with than any professional solution. It follows the motto of 90% of the functionality for 10% of the cost. In short, you need to run the four python scripts below.
create-config.py: parses the markdown file into a easy to use format.tts.py: generates audio with a 11labs text-to-speech model (TTS). It saves the raw subcomponents and returns generated_audio.mp3.ttv-generate.py: pings the OpenAI API for DALLE images and downloads needed files from config.ttv-merge.py: uses MoviePy and locally saved files to create an mp4 output.
Before we get to the details of what this does and examples, let’s start with the motivation for building this suite of tools.
Stratechery, passport, and wonderful customer experiences
Like many trends in the newsletter space, this initiative is downstream of Ben Thompson’s awesome work over at Stratechery. To give users a great experience and optionality on how they consume Stratechery’s content, Ben built Passport. In short, Ben has built more features for Passport than Substack has exposed to me as a writer and there’s not a newsletter that is easier to consume. Though, Substack has built them to likely be much easier to us1e and scale to many audience sizes.

Ultimately, Passport lets people subscribe to a newsletter and get different types of content (articles vs. updates vs. interviews) through different distribution channels like email, text messages, podcast players, or a subset of these. Interfacing my content with Substack isn’t seamless, such as how the articles will still have the button for the default voice or insert a large interface element to play the audio I upload. I am doing audio separately from a podcast feed within Interconnects on Substack because if I did this, I would have to duplicate every post as a podcast or use Substack’s podcast UI for text-centric posts.
While a lot of Substack’s short-term product features are probably around video (like making paid-only YouTube / TikTok channels), I suspect the long-term vision is for them to have the same set of tools as Passport or what I’ve built.
Passport does many magic things for Ben that I don’t have, such as making links in podcast show notes that automatically authenticate a user’s account or paid/free user splits on things like podcast feeds, but I’ll get there. Ben, if you’re reading, I’d love to beta-test your tools!
The videos from Interconnects can be found on YouTube and the audio can be found on my Transistor Podcast site (note, I didn’t backfill content due to usage costs and basic time hassles). If you compare the first video, below, to the most recent videos, there’s already marked improvement.
As with any AI tools, they’re still sensitive to prompting. In the case of audio, the prompt is the audio example used to condition the audio model on your voice. I’ve iterated with different audio clips of myself and different audio filters on the clips I provide as context for the text-to-audio model.
In the coming months, I will be experimenting with Eleven Labs Professional Voice Cloning off of studio audio from a recent podcast appearance. If this is another bump up, I suspect the efforts could be almost indistinguishable from human recording.
Wrap-up, features, and next steps
The thing is, I feel like these tools are just getting started. In the coming years, text-to-video models will be the norm and just as good as DALLE feels now, making the switch to true video (rather than frames per paragraph) seamless. Before this, there are plenty of short-term tools like making short-form content a possibility in the toolkit, adding text burn-in to videos of either the text or for quotes during interviews for sharing on social, and more flexibility in distribution to proper enforcement of paywalls.
Some of the small things that are already included in this code are:
Hosting of figures so podcast listeners have easy links from show notes,
Syncing of image transitions with new paragraphs for videos, giving a strong professional feeling,
The interweaving of images from posts in YouTube videos, which makes technical content watch like a research talk,
Automating research talks from a Google Slides deck and a written script directly to video (with an example here),
Automatically print chapter stamps,
As you zoom in, you’ll find even more ways to customize with the detailed file creation and organization approach. If you’re passionate about building this out into an even more advanced tool with different model backends and distribution angles, please get in touch. I’ll consider sponsoring the compute costs to do so.

At the end of the day, I’m one or two viral videos away from ending the year with more subscribers on YouTube than Substack. I’ll still value my Substack subscribers more given the direct relationship we cultivate, but I cannot deny the value in that growth funnel (especially as I now get more views from LinkedIn than Twitter on a monthly basis). Multi-headed distribution is the answer to turbulent platforms, which we’ve even seen affect Substack in the last few months. After launching about 5 articles in the audio format, I already got 100s of views on YouTube and 50+ listens on podcasts (which is by definition more loyal listeners that found the somewhat hidden links). This is hovering at about 1% of Substack’s view count, but one I’m very excited about growing. Please share any feedback if you have it!
As always, thanks to my paid subscribers who finance my fun experiments with these new AI tools! Again, you can find the code here: https://github.com/natolambert/interconnects-tools
Audio of this post will be available later today on podcast players, for when you’re on the go, and YouTube, which I think is a better experience with the normal use of figures.
Looking for more content? Check out my podcast with Tom Gilbert, The Retort.
Newsletter stuff
Quiet week from me this time around. I think I was too busy coding, which is always fun.
Elsewhere from me
On episode 15 of The Retort, Tom and I did a special crossover with ChinaTalk (a popular Substack covering all things China) on the many geopolitical threads of AI in 2024.
Models & datasets
Model merging is taking off. Really surprised that it is here, so I expect to have to do a post covering it.
Links
RLHF models are really starting to crack LLM leaderboards. 6 months ago, there was maybe 1 model in the top 100!
How AI generated product names are destroying the web (a big laugh).
Working on robotics? Some friendly academics are surveying researchers on painpoints if you have a few minutes.
Housekeeping
An invite to the paid subscriber-only Discord server is in email footers.
Interconnects referrals: You’ll accumulate a free paid sub if you use a referral link from the Interconnects Leaderboard.
Student discounts: Want a large paid student discount, go to the About page.
As some loyal readers may know, part of my long-term vision for Interconnects is to be the Stratechery of AI, but that is a story for another time.