

Open Language Models (OLMos) and the LLM landscape
A small model at the beginning of big changes.
Today, we’re releasing our first pretrained Open Language Models (OLMo) at the Allen Institute for AI (AI2), a set of 7 billion parameter models and one 1 billion parameter variant. This line of work was probably the main reason I joined AI2 and is the biggest lever I see possible to enact meaningful change in how AI is used, studied, and discussed in the short term. The big picture goal of my part of this work, and really all of my writing, is to try and make sure the right voices are heard in this process. This blog is my more polemic or passionate take on the process and will include links to a lot more documents and resources to learn more and get building.

Open Language Model (OLMo) 7B for some will look like another 7 billion parameter model, similar to Mistral and Llama. On many axes of the AI discourse in 2023, OLMo is very similar to these mentioned models, it is available for direct download, it can be fine-tuned easily on consumer hardware, it offers a broad base of capabilities and other things we are used to hearing. Yet to many, OLMo will represent a new type of LLM enabling new approaches to ML research and deployment, because on a key axis of openness, OLMo represents something entirely different. OLMo is built for scientists to be able to develop research directions at every point in the development process and execute on them, which was previously not available due to incomplete information and tools. Depending on the evaluation methods, OLMo 1 is either the best 7 billion parameter base model available for download or one of the best. This relies on a new way of thinking where models are judged on parameter plus token budget, similar to how scaling laws are measured for LLMs.
I didn’t write the title for the paper, but OLMo: Accelerating the Science of Language Models really aligns with my new e/science calling flag.
Key points and links:
Evaluation: OLMo is strong on a bunch of classic generation benchmarks, but lags slightly on tasks like MMLU and GSM8k. We have a lot of experiments to run on instruction-tuning, where those popular evaluations actually matter more.
Per-token capabilities: the right way to look at models in 2024 is per-token training efficiency. OLMo edges out Llama 2 by training on about 20% more tokens (2.5T vs 2T). It’s rumored that Mistral 7b is trained on 2-4x as many tokens as Llama 2, so we don’t compare too much to it. Pythia is trained on <50% of the tokens of Llama and OLMo.
Open training data: The exact dataset and tools for curating it are released under the Dolma project.
License: Models and code are released under Apache 2.0, with the dataset under the AI2 ImpACT license. This is close to an “open-source” ML model, but that’s an ongoing debate.
Artifacts: Collection on HuggingFace with links to models and dataset (Dolma). We release 4 7B models with different end of training annealing, hardwares (AMD and Nvidia), and final token counts from the same initialization.
Paper: The model paper is detailed and has lots of lessons on pretraining and base model evaluation (the Arxiv version coming soon). A technical blog post and press release are available separately.
There’s a second paper for data.Communications: A technical blog post and press release are available. Plus, plenty of popular news outlets are covering it.
Code: Training code, eval code, and fine-tuning code are all available.
Lots more coming soon: AI2 plans on releasing bigger models, fine-tuned models, demos, analysis tools, evaluations, and more this year.
And finally, for the ML hipsters of the world:
magnet:?xt=urn:btih:7b212968cbf47b8ebcd7017a1e41ac20bf335311&xt=urn:btmh:122043d0d1a79eb31508aacdfe2e237b702f280e6b2a1c121b39763bfecd7268a62d&dn=ai2-modelI do not recommend people access ML models through this form, and expect the method to fall overtime, but it’s fun!
My mental tracking of this story is pinned to a Tweet from a vocal voice in the open-source ML discussion, Stella Biderman:
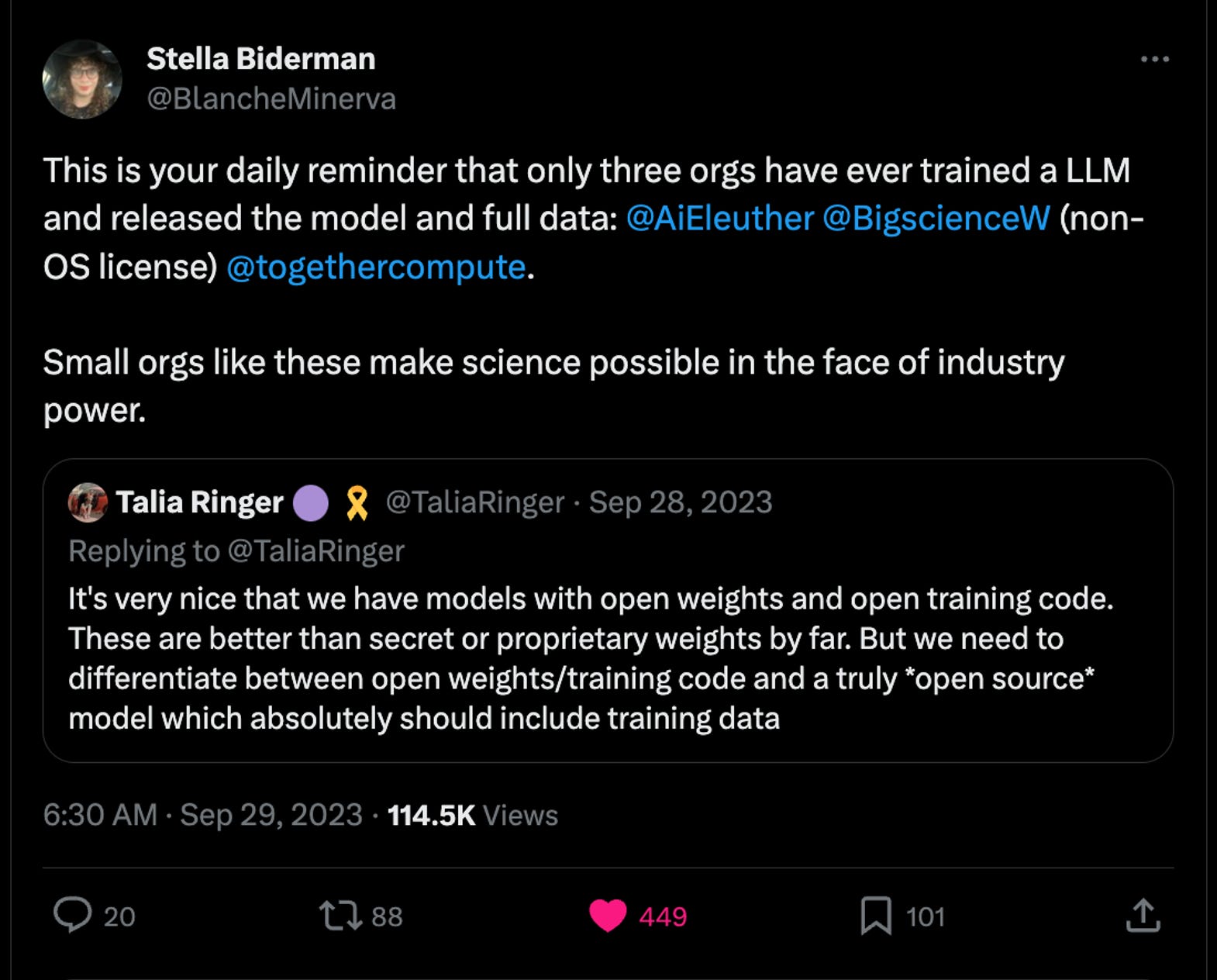
If I wanted to contribute to the narrative here, I needed to be at an organization willing to add their name to the list. With all the discussions around open models and all the good PR it brings companies these days, the short length of this list shows how hard it is to commit to the values needed to bring these artifacts to the light of day.
This is a landscape where models have been leaked multiple times and organizations releasing strong open models face real pressure from multiple government organizations. At a practical level, getting OLMo out before Llama 3 and the next Mistral models gives everyone time to catch up on what it means to be truly an open-source model.
OLMo represents the first time in a while (maybe before GPT2) that a state-of-the-art language model is fully transparent and open. While some communities may advocate for different behaviors, the release of the OLMo family represents the first time where many areas of study can be empowered to support a more well rounded discussion around the potential harms and benefits of LLMs. While many language models have been close to meeting the standards of “open”, and are perceived as open by the general public, such as Llama 2 and Mistral, they do not provide access to certain types of work that is needed to make clear arguments around the potential risks.
For example, both Mistral and Llama, do not disclose the data used at the pretraining or preference fine-tuning stage of development. The pretraining data hold is largely accepted to be due to ongoing litigation into the copywritten dataset Books3, which is under litigation in multiple judicial venues. In the OLMo family, we have the ability to easily add this data to our formula to quickly understand the potential impact of this dataset by sharing model performance without sharing the license-violating model itself. This informs policymakers on the value of this work to the parties seeking compensation for their materials and the importance of similar data to scientists training other models. Ultimately, OLMo helps unblock scientists who wish to study many details like this, but cannot due to lawyers and potential liability preventing access to valuable resources.
Realistically speaking, research on pretraining is the biggest pipeline stage where curious researchers will benefit from OLMo. OLMo was trained on Dolma, a dataset released openly by AI2 in 2023. Access to the pretraining data enables research on important new capabilities like attribution and methodological challenges like identifying test set contamination. Openness thrives in multiplicity so future models trained on the Dolma dataset by others would enable more controlled comparisons between models than are currently available.
If you’re doing research on LLMs, the likelihood of having a long standing impactful result working on OLMo is much higher than doing in-context and safety results on ChatGPT, where your results only stand until OpenAI deploys a patch.
By taking a bold, honest, and committed stance to openness, we can figure out in which ways open models are actually safer than their closed counterparts, and in which cases the prevailing narrative is supported. I’m excited to bring more on this later this spring.
Thought experiments
There are loads of low-level technical details that are on the near-term to-answer list with OLMo. Some of these are already done and are being added to a future paper and some of them are just important want-to’s.
What happens when you add instruction data to the end of the pretraining mix? Rumors are that Mistral did this, but more than boosting base model performance on reasoning tasks like MMLU, does it actually make the model easier or harder to fine-tune? The estimate I’ve heard is that you need .1 to 1% of the pertaining tokens to make this land.
How do tokenizers impact different subsets of capabilities? For example, encoding numbers is different than Llama (where each digit is represented individually if I recall correctly), so OLMo models may be behind in this category only for this change.
At a technical level, this is the difference of a BPE vs Unigram tokenizer. There are more stories on BPE failures and entire papers on tokenizer history.
Be careful though! If you release the model just with the Llama tokenizer, you’re bound in the license to use the Llama 2 license. Honestly, it’s a meme.
What changes if you have access to the full optimizer state for fine-tuning? When you just get the model weights alone, we know how IFT works. Can fine-tuning become more sample efficient if you continue Adam on the trajectory it was on?
I’m mostly a fine-tuning researcher, so I haven’t been as pressed by this, but if you use your creativity I’m sure you can come up with many more examples.

The LLM landscape heading into 2024
It still seems like it’s full speed ahead for opening models. Both Mistral and Meta admitted they may not open-source the models forever, but these two organizations are in an intense battle to be seen as the leader of open LLMs. There’s a big market opportunity to capture there.
On the other side of this are projects like OLMo, LLM360, Eagle, etc. that are releasing as much as they can. While it would be good for there to be siloing of scientific progress, the comparisons to these will regularly appear in news cycles. It’ll be lots very quickly on most journalists what it means for Mistral to be trained on 3x the number of tokens than OLMo and for Pythia to be trained only on 300B tokens. We’re learning a lot collectively and will need to keep our heads down during this.
There are also interesting battles playing out between OpenAI and Google in the ChatBotArena, but that signal isn’t enough to fit into. The basics of what people are voting on there are still unknown. For example, what if all the votes are just for models who go along with the most harmful requests? This is a thought experiment, but I suspect there’s a very measurable amount of prompts in that bucket. Overfitting to LMSYS may be the new overfitting to the open LLM leaderboard from last year. They’re important phases, as open models learn to develop new skills, but the big picture won’t change for me.
The few of us building OLMo and building off OLMo can keep plugging away. In 2025 and on, this will only grow in influence, necessity, and impact.
Audio of this post will be available later today on podcast players, for when you’re on the go, and YouTube, which I think is a better experience with the normal use of figures.
Looking for more content? Check out my podcast with Tom Gilbert, The Retort.
Newsletter stuff
Models, datasets, and other artifacts
The Qwen team released a promising VLM (multiple size scales).
codellama 70b was released, I think they’re just trying to start building excitement for Llama 3, which is coming soon.
H2O AI released another smaller base and chat model pair, Danube. A technical report is here
LLaVA, the leading open visual assistant model, was update to v1.6.
Another cleaned DPO dataset from Argilla / on Twitter.
Links
Cool tool to view LMSYS’s ChatBotArena dataset statistics.
Housekeeping
An invite to the paid subscriber-only Discord server is in email footers.
Interconnects referrals: You’ll accumulate a free paid sub if you use a referral link from the Interconnects Leaderboard.
Student discounts: Want a large paid student discount, go to the About page.
Finally code + data + weight.
Although to access dolma, one needs form agreement. Nice one!
Super excited for this! I love how OLMo and AI2 are a showcase of open source, open models, and transparency!