

Olmo Hybrid and future LLM architectures
The latest Olmo model and discussions at the frontier of open-source post training tools.
So-called hybrid architectures are far from new in open-weight models these days. We now have the recent Qwen 3.5 (previewed by Qwen3-Next), Kimi Linear last fall (a smaller release than their flagship Kimi K2 models), Nvidia’s Nemotron 3 Nano (with the bigger models expecting to drop soon), IBM Granite 4, and other less notable models. This is one of those times when a research trend looks like it’s getting adopted everywhere at once (maybe the Muon optimizer too, soon?).
To tell this story, we need to go back a few years to December 2023, when Mamba and Striped Hyena were taking the world by storm1 — asking the question: Do we need full attention in our models? These early models fizzled out, partially for the same reasons they’re hard today — tricky implementations, open-source tool problems, more headaches in training — but also because the models fell over a bit when scaled up. The hybrid models of the day weren’t quite good enough yet.
These models are called hybrid because they mix these new recurrent neural network (RNN) modules with the traditional attention that made the transformer famous. They all work best with this mix of modules. The RNN layers keep part of the computation compressed in a hidden state to be used for the next token in the prediction — a summary of all information that came before — an idea that has an extremely long historical lineage in deep learning, e.g. back to the LSTM. This setup avoids the quadratic compute cost of attention (i.e. avoiding the incrementally expanding the KV cache per token of the attention operator), and can even assist in solving new problems.
The models listed to start this article use a mix of RNN approaches, some models (Qwen and Kimi) use a newer idea called Gated DeltaNet (GDN) and some still use Mamba layers (Granite and Nemotron). The Olmo Hybrid model we’re releasing today also falls on the GDN side, based on careful experimentation, and theory that GDN is capable of learning features that attention or Mamba layers cannot.
Introducing Olmo Hybrid and its pretraining efficiency
Olmo Hybrid is a 7B base model, with 3 experiment post-trained checkpoints released — starting with an Instruct model, with a reasoning model coming soon. It is the best open artifact for studying hybrid models, as it is almost identical to our Olmo 3 7B model from last fall, just with a change in architecture. With the model, we are releasing a paper with substantial theory on why hybrid models can be better than standard transformers. This is a long paper that I’m still personally working through, but it’s excellent.
You can read the paper here and poke around with the checkpoints here. This is an incredible, long-term research project led by Will Merrill. He did a great job.
To understand the context of why hybrid models can be a strict upgrade on transformers, let me begin with a longer excerpt from the paper’s introduction, emphasis mine:
Past theoretical work has shown that attention and recurrence have complementary strengths (Merrill et al., 2024; Grazzi et al., 2025), so mixing them is a natural way to construct an architecture with the benefits of both primitives. We further derive novel theoretical results showing that hybrid models are even more powerful than the sum of their parts: there are formal problems related to code evaluation that neither transformers nor GDN can express on their own, but which hybrid models can represent theoretically and learn empirically. But this greater expressivity does not immediately imply that hybrid models should be better LMs: thus, we run fully controlled scaling studies comparing hybrid models vs. transformers, showing rigorously that hybrid models’ expressivity translates to better token efficiency, in agreement with our observations from the Olmo Hybrid pretraining run. Finally, we provide a theoretical explanation for why increasing an architecture’s expressive power should improve language model scaling rooted in the multi-task nature of the language modeling objective.
Taken together, our results suggest that hybrid models dominate transformers, both theoretically, in their balance of expressivity and parallelism, and empirically, in terms of benchmark performance and long-context abilities. We believe these findings position hybrid models for wider adoption and call on the research community to pursue further architecture research.
Essentially, we show and argue a few things:
Hybrid models are more expressive. They can form their outputs to learn more types of functions. An intuition for why this would be good could follow: More expressive models are good with deep learning because we want to make the model class as flexible as possible and let the optimizer do the work rather than constraints on the learner. Sounds a lot like the Bitter Lesson.
Why does expressive power help with efficiency? This is where things are more nuanced. We argue that more expressive models will have better scaling laws, following the quantization model of neural scaling.
All of this theory work is a great way to go deeper, and frankly I have a lot more to learn on it, but the crucial part is that we transition from theory to clear experiments that back it up. Particularly the scaling laws for designing this model were studied carefully to decide on the final hybrid architecture. The final performance is very sensitive to exactly which RNN block is used and in what quantity.
In scaling experiments, the results showed that for Olmo, the hybrid GDN (3:1 ratio of layers) > pure GDN (all RNN layers) > standard transformer (all attention) > hybrid Mamba2 > pure Mamba2. The crucial point was that these gaps maintained when scaling to more parameters and compute. A visual summary of the different types of architectures studied is below.
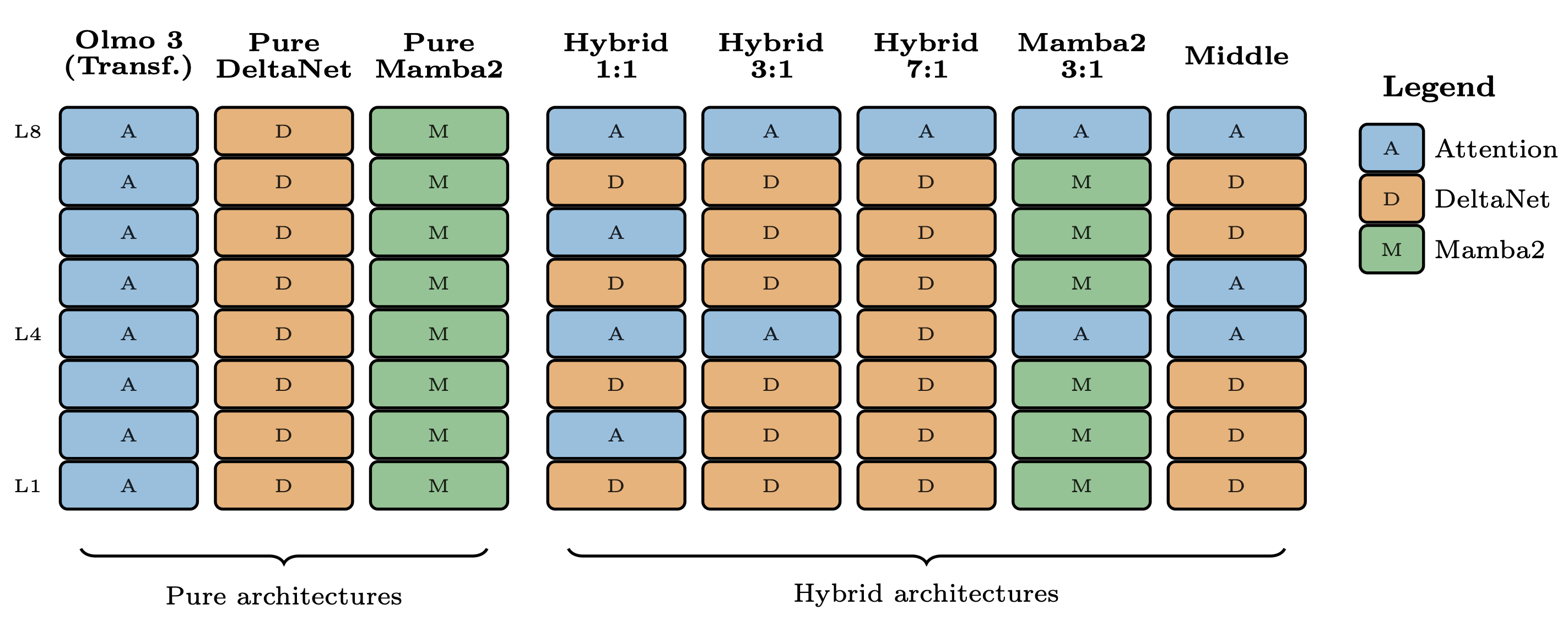
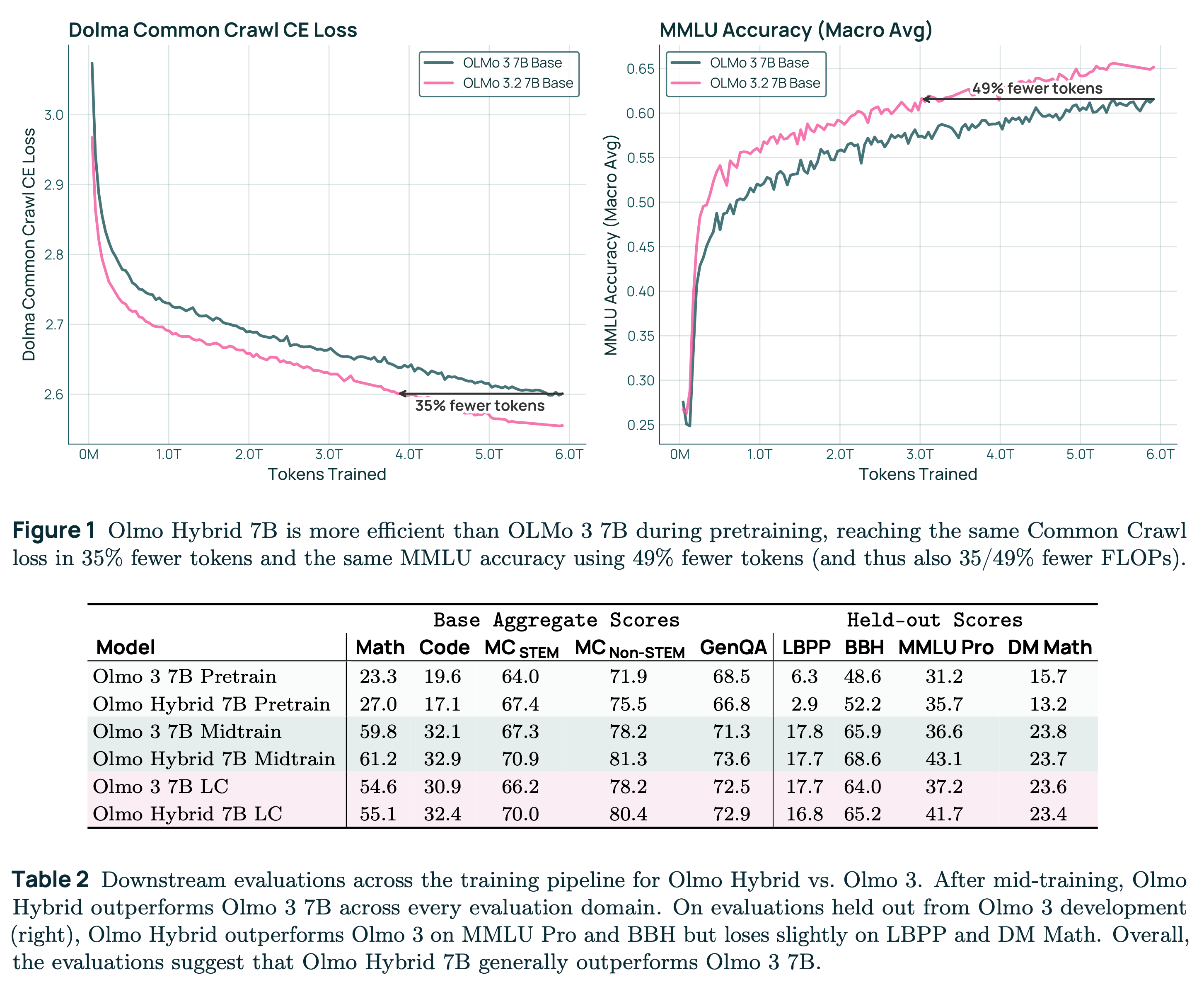
In terms of this specific model, the pretraining gains were giant! Relative to Olmo 3 dense, it represents an about 2X gain on training efficiency. When you look at evaluation performance for pretraining, there was also substantial improvement in performance, particularly after long context extension (the final 2 rows of Table 2 in the paper, highlighted below).
The journey to post-training Olmo Hybrid
Most of the experience in post-training Olmo models has been climbing up a steep curve in base model capabilities with minor tweaks to architecture. Our recipes from Tulu 2, Tulu 3, and the Olmo 3 reasoning work (building substantially on OpenThoughts 3) all worked in a fairly straightforward, off the shelf manner. Olmo Hybrid is our first experience in post-training a substantially different architecture, and the results were mixed.
1. Benchmark performance
Following the Olmo 3 recipe, we got some substantial wins (knowledge) and some substantial losses (extended reasoning) relative to the dense model. All together these still represent a very strong fully open model — just that the pretraining gains didn’t translate as obviously. The results are below.
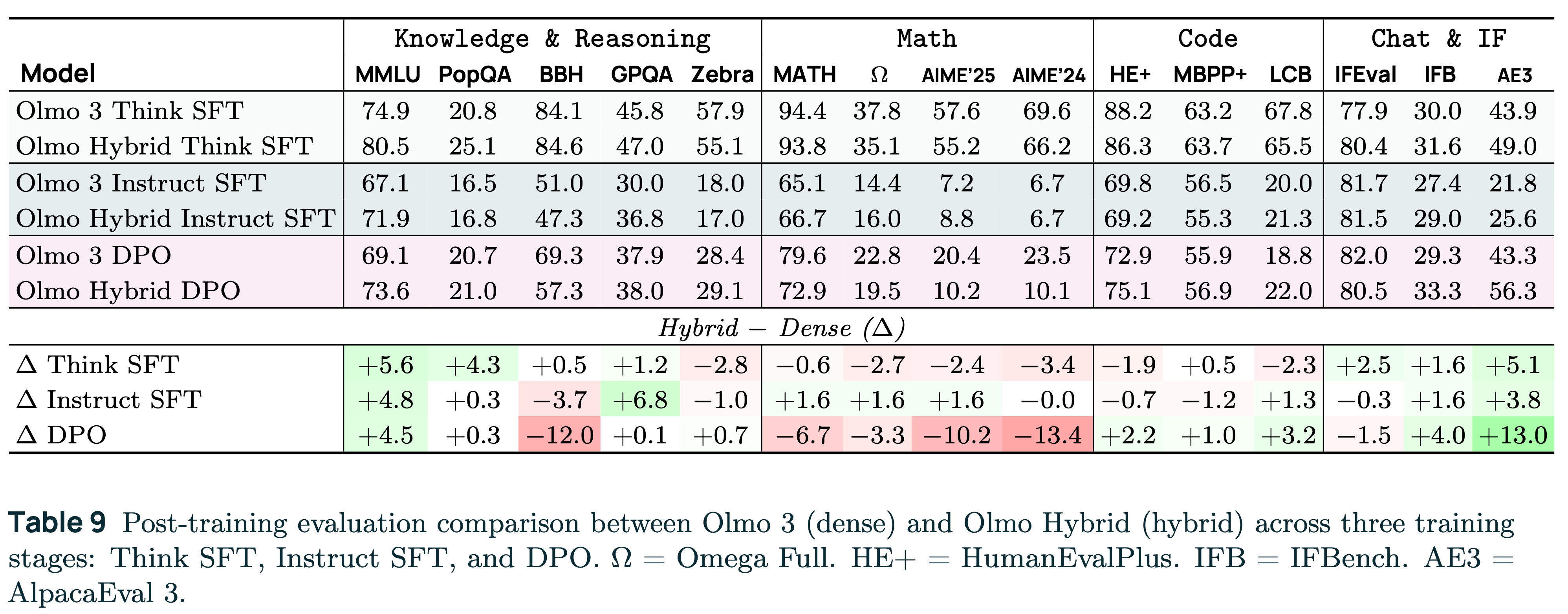
The exact reason why this happens is a research question. Our best guess is that the Olmo Hybrid base model is just a sufficiently different student model, where most of our post training data at early stages is learning from stronger “teacher” models (a recap of this method, called distillation, appeared recently in Interconnects).
There is a lot of other research ongoing in the community around what makes a strong teacher model — generally, the best overall model is not the best teacher. In other words, training on data outputted from the model with best evaluation scores today is unlikely to unlock the ceiling in performance for your new base model. A second factor, which is even less explored, is how different base models likely need different teachers to learn from. This is why Olmo Hybrid could perform very differently, where it’s behavior is downstream of an architecture-based learning change, where the pretraining data is almost identical.
There’s A LOT more work to dig into here, some empirical work in generating better data and other work in understanding how different training stages fit together. I am confident this Olmo Hybrid base model is solid and more performance can be extracted, but it takes more careful work adapting existing datasets.
2. Open-source tooling
The frank reality of new architectures for open models is that the open-source software tooling support is horrific. There’s the paper-cuts that people are familiar with, e.g. random errors in popular libraries (as people experienced with GPT-OSS) that slow adoption, but there are also deeper problems.
A large part of the potential benefit of hybrid models is the reduction in memory usage for long-context generation, which is crucial for reinforcement learning and agentic tasks. It should be a huge win for post-training! This, unfortunately, is far from the case, and will likely take another 3-6months to get right for this batch of GDN models.
The core problem is that the open-source inference tools, e.g. VLLM, are relying on far less developed kernels (and other internals) when compared to standard transformers. This comes with two challenges — throughput slowdowns and numerical issues. Numerical issues can be combatted with a variety of inference flags. Quoting the paper again:
The two key flags in VLLM we needed to get maximum performance with the post-training model were
--disable-cascade-attn, which disables cascade attention (an optimization for shared prompt prefixes), and --enforce-eager, which turns off CUDA graphs. These two flags have been used in our RL setup dating back to Olmo 3, but are new additions to evaluations. Scores for the released models drop precipitously without them. We also evaluated our final models with the hybrid model cache in the richer FP32 datatype, to improve stability via--mamba_ssm_cache_dtypefollowing NVIDIA.
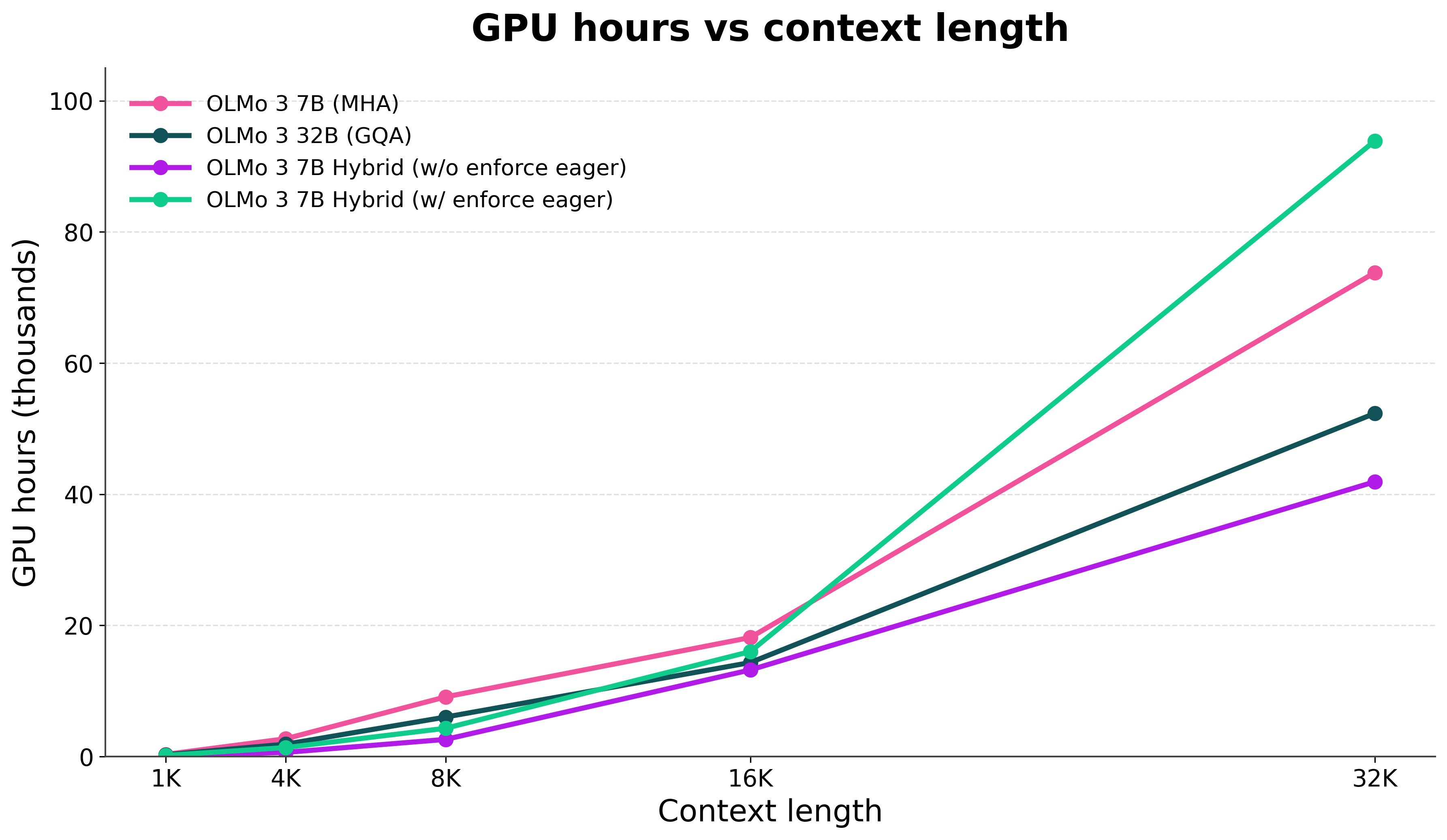
Essentially, we used these to make sure the model was numerically stable. The downside is that the inference throughput plummets, so the potential gains in compute efficiency are erased. A comparison of numbers is below.
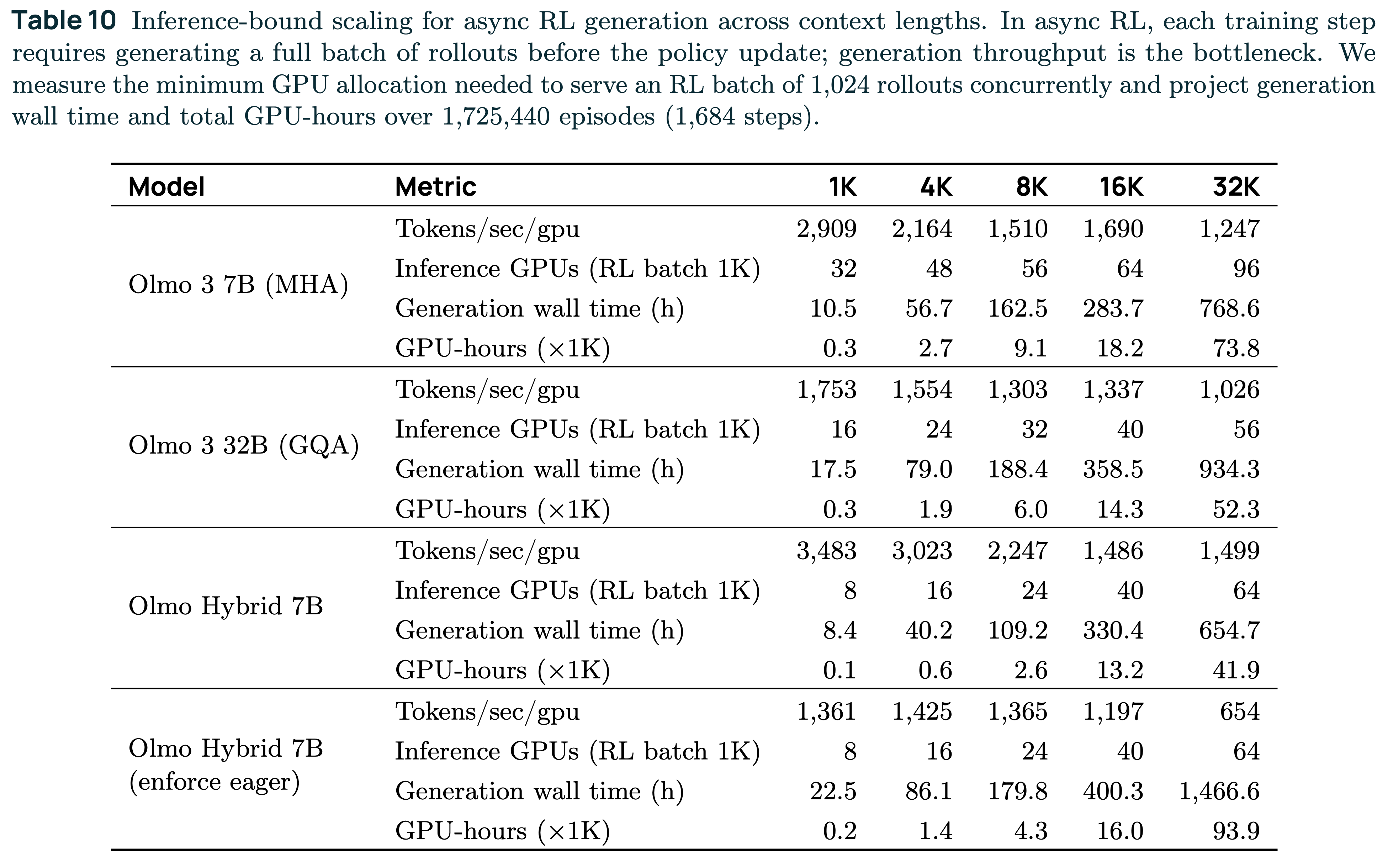
Effectively, the 7B hybrid model today takes more compute to train with RL than our 7B dense model (that doesn’t even have a common memory saving technique, GQA). The total compute estimate from the table at different context lengths is below (more visuals in the slides from my recent CMU talk).
The good news is that these are solvable problems — and improving the tooling could even improve benchmark numbers — but it’s going to take a good bit of time and hard work in the OSS community.
This leads to my final question. If I’m optimistic about the open ecosystem evolving to support these models with ease, motivated by the better fundamental scaling of the architectures and a large cluster of leading open model builders already using it, are closed models like GPT and Claude built like this?
To be clear, this answer is a total guess (which I don’t normally do), but with the evidence I have I’d put the chance of one of the 3 frontier models being an RNN being around a coin flip. I’ll let you know if I learn for sure either way. If the scaling advantages hold at frontier scale, the economic case becomes hard to ignore, but they could already have architectures that are efficient like RNNs, but with even more benefits.
I’m going to follow up this post with more architecture discussions, particularly on why Mixture of Expert (MoE) models are a major headache to post-train, so make sure to subscribe if that sounds interesting to you!
Thanks to Will Merrill and Finbarr Timbers for some discussions that helped inform this post.
and still my most-viewed interview on YouTube, as the first one I did.
This is *FINALLY* answering the question everyone has been thinking after reading the new model releases this year: why these hybrid attention layers? And apparently, more expressiveness is the answer?
I am more than excited to hear the post-training challenges for MoE models: if we can inference with sharding, couldn't we do the same with post-training as well?
Thank you for reading the article rather than text-to-speech. This has been more than refreshing.
Thank you for your time and attention concerning this recent discovery.
https://substack.com/@sublius/note/c-224332811?r=724p51&utm_medium=ios&utm_source=notes-share-action