

What I've been reading (#2): More on Kimi K2, how to build a bad research center, Pretraining with RL, and sporks of AGI
A quiet summer is all you need.
Amid the chaos of my primary jobs in training language models and keeping up with the major releases, most of what I spend my time reading can fit into a few categories of understanding:
How AI companies operate,
How people use AI today, and
What is being solved at the cutting edge of AI tooling or training.
And, of course, I’ll end this post with all the extra stuff that caught my eye.
1. How AI companies operate
Moonshot’s Kimi K2 model deserved more time in the limelight. It was the first strike in a rapid-fire summer of Chinese AI models. There are a few posts I recommend on the area that I wish I could’ve written myself.
The first is this post from ChinaTalk, where they built on a translated interview with the Moonshot CEO they posted in March, quite ahead of the wave.

This post digs into Moonshot’s culture, features translated snippets of posts from Moonshot’s own researchers on “why they pursue the open model” or “why they chose their architecture.” Something good to know is that Moonshot has a very different business model than DeepSeek (self-funded hedge fund) or Qwen (backed by cloud giant Alibaba), as a venture-backed company. ChinaTalk expands on this:
Moonshot has no B2B offerings and does not build wrapper tools for corporate users, instead focusing directly on individual customers. From the beginning, Kimi’s selling point to Chinese users was its long context window, allowing users to upload dozens of documents and analyze long articles.
There’s a lot more great stuff coming out on the Chinese AI ecosystem that can be easy to miss. Some include this post from Kevin Xu on why China is structurally set up to win open-source AI right now (an outlet I rely on for much of my learnings in this space) or this in-depth WeChat post on the current landscape of Chinese AI companies. I’m also finishing up reading Apple in China and it has been utterly fantastic for understanding how the tech ecosystem works in China.
Kevin’s post had a great anecdote from what the DeepSeek moment in January did within China, that made it clear most of us are just totally ignorant of the operations of Chinese AI companies:
The only thing that the “DeepSeek moment” really messed with were the holiday plans of other Chinese AI labs, who were equally shocked by DeepSeek’s progress. One in particular, Alibaba’s AI team, apparently uttered a collective “holy sh*t”, called off everyone’s holiday travel plan, stayed at the office, and slept on the floor until a competitive model was shipped.
It should be a given that they’re just as motivated as their American counterparts, but it makes me wonder — what are the key differences?
In conversations with others about this question of “how to build a good AI research center” (or, how to build ATOM), I was pointed to a relevant old link, David Patterson on How to Build a Bad Research Center — a fun document that lists the common failure modes of ineffective research hubs.1 For anyone in research and frustrated with their job, do give it a skim and you’re likely to validate yourself. You’re welcome.
David Patterson has a lot of great stuff, such as his general advice after 50 years of work.
2. How people use AI today
Coding is the most well-known, productive use case for today’s language models. The weird thing with that fact is that, due to how complex the act and practice of software development is, understanding exactly what it means to effectively code well with LLMs is not that well articulated. A few weeks ago, I came across this post which I felt nailed it exactly right.
The post highlights a few clear examples on the sort of things LLM-assisted coding can enhance, such as learning fast or detecting bugs, but the best part was the clear advice that we can take to others who ask us:
Use the right LLMs (which have been Gemini 2.5 Pro and Claude Opus 4 — I wonder if GPT-5 makes the author’s list),
Provide large context — most people don’t give their tools enough information,
Refuse vibe coding most of the time.
I vibe code a lot, but only for projects I will never touch again after a day or week.
This is all in contrast to the famous METR study that showed many people were less productive with AI-assisted coding. I didn’t comment on this because it mostly felt like it wasn’t measuring comprehensively enough. I vibe code because I can make slower progress, or extra progress, without taxing my brain.
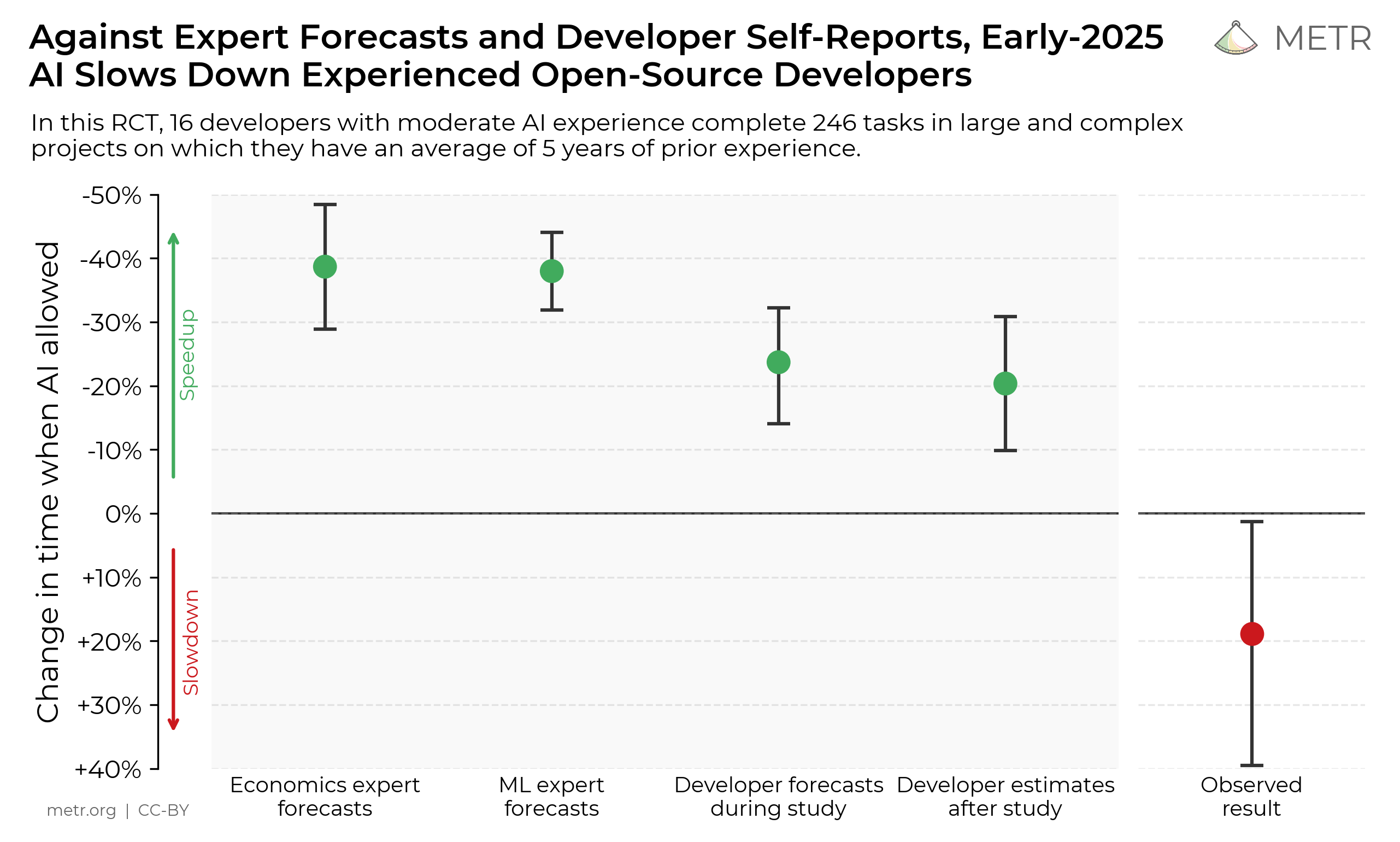
One of the developers in the study spoke out a bit on parts he found misleading.
This last collection for this section doesn’t directly relate to which tools people are using, but rather how much people are using AI — supposedly Congress is getting more AGI-pilled. Between this, the AI Action Plan, and countless people begging OpenAI to bring back GPT-4o following the GPT-5 release — we can clearly expect the coming months to keep getting weirder with respect to AI.
3. Tooling, techniques, and troubleshooting
This section is mostly going to be a list of places to dive in and learn more about a certain training topic. Even though most leading researchers are in closed labs now, there’s still a lot of great technical work that goes under the radar. Choose what suits you, from:
Long-context training: Arcee AI and Snowflake published blog posts on extending the context length of their models.
Fixing loss spikes at pretraining: The Marin project at Stanford shared how they updated their trainer after getting feedback on socials about how “spiky” their 32B model training was.
What weird fixes are needed to run new architectures in the open ecosystem: Daniel Han of Unsloth “fixed” (Twitter summary) much of OpenAI’s gpt-oss model. This normally involves precision or version issues, chat template misalignment, or other minor things as new architectures are getting implemented in 20+ libraries at once.
The most serious experiment I’ve seen on a fairly unserious topic — RL pretraining in avataRL.
For some of everything, read the SmolLM 3 report — one of the open-source friends of OLMo.
4. Extras
There are two posts that didn’t really fit into the core themes that I would still recommend.
The first is this from Sergey Levine, where he talks about how a few priors people had for scaling robotics — like training on vast video data — haven’t been good enough to kickstart a revolution. Where modern LLMs are operating in the same domain that they’re trained on, in text, robots don’t have the same convenient reality, making the need for real-world data far higher.
He calls the attempted shortcuts people take in robotics:
surrogate data, a spork that tries to get the benefits of large-scale training without the cost of large-scale in-domain data collection.
The second is a piece by Ben Recht in partial response to my first post on The American DeepSeek Project. This was a feel-good read for me — if you’ve been fighting the same fight as me in search of more openness, or have considered it, I suggest giving it a read.

Enjoy! Let me know if I missed any hidden gems.
