

Why reward models are key for alignment
In an era dominated by direct preference optimization and LLM-as-a-judge, why do we still need a model to output only a scalar reward?
We’re entering an era of model adaptation research where some people who are regularly bashing the reinforcement learning from human feedback (RLHF) hammer on models won’t even know what a reward model is. 2024 is the year when most folks are going to embrace that we may not need RL for RLHF thanks to the simplicity and success of Direct Preference Optimization (DPO). The thing is, this is actually making reward models more prevalent, but less likely to be used. Reward models give us an entirely new angle to audit the representations, pitfalls, and strengths of our LLMs without relying on the messiness of prompting and per-token computation limits. Reward models tend to not need prompting and only generate one token given any input text, a simplicity I expect to have a compelling impact in the next few years.
In the canonical RLHF framework, reward models are a large language model (LLM) tasked with approximating part of the traditional environment in an RL problem. The reward model takes in any piece of text and returns a score.1
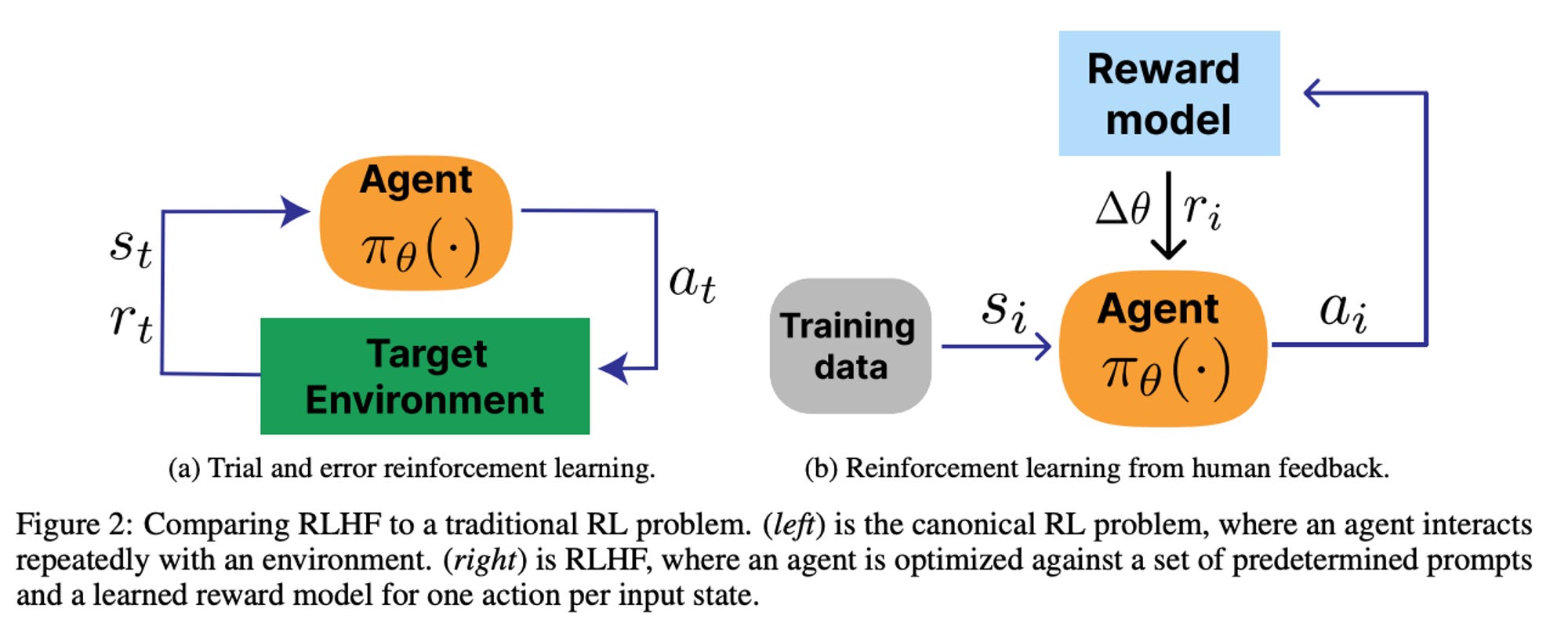
In an RL worldview, the environment is the single most important part of solving a problem — it’s the reason it's assumed to be static. RLHF unpacks the RL framework in a way that makes it much messier, but that is exactly why we need to be extremely particular about our reward models. We can construct static comparisons for a reward model, e.g. for bias or specific viewpoints, that calculate the specific preference between any two sides (which returns are higher score). With synthetic data, we can test almost anything. When testing a generative LLM, a lot more would go into it.
If we can effectively query our environment from the RL point of view at any made up state, we really should be. In practice, reward models are seen as intermediate artifacts of the training process rather than this core piece of the framework, almost completely ignoring this potential signal. The reward model is engineered in order to improve the downstream model post-RL optimization.
The core thing to remember about DPO in all of this is that its loss function is derived directly from the loss function for a pairwise reward model, its implementation as a reward model is much more tedious. Second, the reward is a ratio of log-probs rather than an explicit score. Technically it requires keeping track of the instruction model it was fine-tuned from, but most of the details are open research questions. Everything is a reward model in the era of DPO being more accessible and therefore successful, but no one is going to take them seriously because it’s even easier to argue they’re just an intermediate training artifact. In fact, the policy derived by DPO is actually the secondary artifact in the optimization.
For example, we don’t know the most basic things about how reward models work. Something I’ve learned recently is that it is common to heavily down-weight truncated responses in PPO training because incomplete responses have wildly varied rewards. An experiment I’ve been iterating with is to look at the per-token reward of a sequence. Taking an off-the-shelf reward model from the HuggingFace hub, we can test this:
Reward: 1.344 | Substring: I
Reward: 1.152 | Substring: I love
Reward: 2.174 | Substring: I love to
Reward: -0.385 | Substring: I love to walk
Reward: 0.176 | Substring: I love to walk the
Reward: 2.305 | Substring: I love to walk the dog
Reward: 1.619 | Substring: I love to walk the dog,
Reward: -0.201 | Substring: I love to walk the dog, what
Reward: 1.255 | Substring: I love to walk the dog, what do
Reward: 2.377 | Substring: I love to walk the dog, what do you
Reward: 1.179 | Substring: I love to walk the dog, what do you like
Reward: 1.298 | Substring: I love to walk the dog, what do you like?
Looking at this it is really not clear why certain scores are higher. Look at the third to last line! Obviously, companies like Anthropic and Google have much better reward models than this, but this is the type of filter we’re pushing our model updates through when doing RLHF. A lot can go wrong.
Some people working on models don’t like to see the darkness underneath the LLMs we’re building. In an era of models like Sydney that show true personality and Llama 2 Chat that was known for timidness, reward models still show some of this dichotomy. It’s an untapped vein of insight that to date is mostly untapped. My list of reward models on the Hub still only has about 10 models that can actually be run (it doesn’t include DPO models, which are slightly different).

It’s time to take my calls for accessing reward models a little more seriously. I’ve pointed out how weird it is that we have so few of them (including none from top training labs) and why the problem specification is messy (which turned into a great paper). The truth is reward models are simply a wonderful way to learn about the representation of language models. Reward models can let us peak behind the curtain of the content represented by stochastic parrots.
The clearest way that reward models can be useful is because the loss function classifying between two classes, good and bad, is very simple. People have been training classifiers in NLP for a long time. My optimistic take here is that it gives us an easy way to understand preference data, as we can use the same data to train a reward model classifier as we would with DPO or other RLHF updates.
Today, generative reward labels are very popular. The largest application of this is in LLM-as-a-judge evaluation tools like AlpacaEval and MT Bench. These require prompting a model to choose which response is better. There’s more research exploring these alternatives as applied like a reward model in the optimization loop, but I worry about not having a scalar output from the model. This is also a weakness of DPO, where every pair is pushed all the way into good or bad buckets. From an RL perspective, the gradations of reward offered by a scalar reward is a huge performance win.
In the long term, I expect generative reward models to be just as good or better given the investment in generative LLMs as infrastructure. Other open models are being released to remove some of our collective dependencies on GPT4. Until we understand reward models and preference data, I’m not sure how far these can go.
To summarize the other benefits I have in mind and may not have commented on at length:
We get to move beyond the opaqueness of compute over many tokens. It seems like different goals to have a model generate meaningful text and be reliable at outputting specific special tokens for reward, but scaling laws may just solve this.
We don’t need to ask models for opinions on answers and to explain their reasoning (as done in MT Bench), so there’s less anthropomorphization.
We get clarity on the ambiguity of the RLHF process that kicked off this entire post-ChatGPT wave. Intermediate checkpoints are good for accountability. We need to show that they’re not encoding human “preferences,” but rather a specific notion of reward.
We can get a better understanding of how models trained with DPO encode information. It’ll encourage more research into how reward is encapsulated in these models and showcase how tricky it is that we need access to a reference model to fairly compute reward.
We get a clear new problem space to study RLHF. Most of the papers I see on reward models right now are about overoptimization. Overoptimization papers are about designing a robust reward function, not a good reward function.
I’ve begun working on understanding reward models and I’ve already had fairly clear insights on the varying performance characteristics of different preference datasets out there. So long as RLHF is mostly giving us benefits on one or two vibes-like evaluations, the additional signal goes a long way.
I’m behind on the RLHF literature series I started but have more RLHF content in the pipeline. I want to write a follow-up to my article How RLHF actually works with a focus on specific tasks other than safety RLHF is used for, have some interviews planned, and major projects I’m hoping to release in Q1. Thankfully, it’s been a quiet-ish winter in terms of barnstorming open model releases, so I’ve been in a more sustainable rhythm of writing and building.
Audio of this post will be available later today on podcast players, for when you’re on the go, and YouTube, which I think is a better experience with the normal use of figures.
Looking for more content? Check out my podcast with Tom Gilbert, The Retort.
Newsletter stuff
Elsewhere from me
On episode 19 of The Retort, Tom and I discussed the deep links between VR hopes and AI.
Models, datasets, and other tools
Reka released multimodal models (21B and 7B), API only, strong evals, including chat versions, no paper.
CohereForAI released Aya, multilingual instruction fine-tuning paper and model (fine-tuned from mT5).
Links
Yoav’s review of “Grandmaster Chess without Search” looks like a good read into some of the future of RL.
Huge RL paper from friend of the pod. Costa, which is creating a centralized leaderboard across libraries.
Synthetic data for LLMs slides from Rishabh Argawal at Google (announced on Twitter).
Housekeeping
An invite to the paid subscriber-only Discord server is in email footers.
Interconnects referrals: You’ll accumulate a free paid sub if you use a referral link from the Interconnects Leaderboard.
Student discounts: Want a large paid student discount, go to the About page.
This figure could be arranged slightly better, with the reward model on the bottom, but alas perfection is a moving target.
How does KTO (Kahneman-Tversky Optimization) factor in? It seems to me more adaptable to real world data and seems on the surface to be able to learn a more nuanced reward model.
@Nathan - There is a paper that I recently read about using per token rewards - "Some things are more CRINGE than others: Preference Optimization with the Pairwise Cringe Loss" May be you have looked at this. And, the other paper I am currently reading is the LiPO where we have ranked list of human preferred choices.