

Latest open artifacts (#12): Chinese models continue to dominate throughout the summer 🦦
A new flagship Qwen model, Qwen3-235B-A22B-Instruct-2507, and a general rise in ecosystem quality in Artifacts Log 12.
Edit 07/21: Added a note on how bad the license for the Hunyuan-A13B-Instruct model by Tencent is.
Back in February, we observed the growing presence of Chinese companies on X to spread awareness of their models as part of a concerted effort to grow their market share in the U.S. For example, in the last couple months, Nathan has gotten DMs from 3 of the leading Chinese frontier model laboratories on Twitter asking to collaborate or promote their work (and zero from Western companies).
This has only continued — even small subdivisions of Alibaba like Tongyi are growing their presence. Another direction is how Qwen has launched a new page for tinkering with their models on Qwen.ai, which feels similar in functionality to Google's AI Studio, as a landing page for those building with Qwen.
The recent Kimi K2 launch is a case study of this — days before the launch, the Kimi account messaged several people in the AI space, even smaller accounts, and offered them pre-release access to the model. This isn’t new for Western companies, but is noteworthy as it becomes standard practice internationally. The way Kimi cleverly captured Western interest is by being the only provider (to our knowledge) to offer an Anthropic-compatible API. Scripts to use K2 in Claude Code quickly emerged. With the capabilities of the model, this yielded immediate adoption and praise on social media.
Zooming out, this is part of a larger trend where the quality of the open artifacts we are covering are maturing rapidly. In terms of overall quality, this issue of Artifacts Log is the most impressive yet, and this extends far beyond text-only models. A year ago, it felt like a mix of half-baked research artifacts and interesting ideas. Today, there are viable open models for many real-world tasks.
In the last issue, we introduced more metadata for this series, highlighting the base models used to create the artifacts we highlight. We extended our database to include the rest of our issues, where you can see the original dominance of Meta’s Llama in Artifacts Log, where now Qwen has been the default for many months.
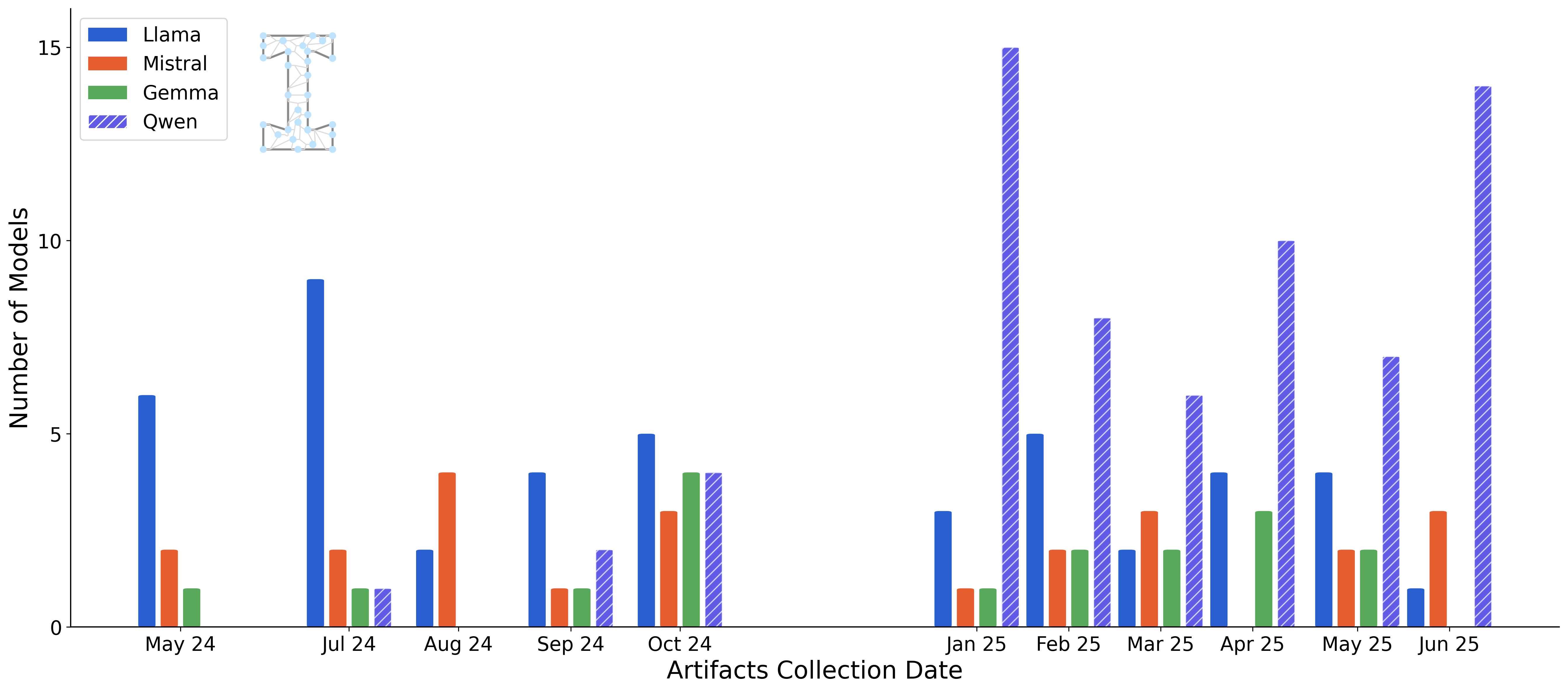
More analysis like this soon, but onto the post!
Our Picks
Qwen3-235B-A22B-Instruct-2507 by Qwen (released earlier today): While the dual-thinking mode wasn't introduced by Qwen, they helped popularize it with a simple mode switch by including either
/no_thinkor/thinkin the prompt. To the surprise of some, Qwen is abandoning the concept after talking to the community and released an update to the big (now non-reasoning) MoE model. The scores are impressive (beating the Kimi K2 model we recently hyped as a major release), including 41.8 on ARC-AGI.
It turns out training a hybrid reasoning model is more challenging technically than it is worth relative to the upside of downstream serving (where training two separate models, one thinker one not, is much easier).
The best part of this release is that it has come with multiple reports of strong vibe tests. Historically, Qwen has been known to be among the benchmark-maximizing labs — there are a few papers that have come out recently highlighting signs of data contamination in Qwen base models — but the Qwen models are improving in the robustness of normal testing. We’ve written multiple times on Interconnects about how labs will first shoot for strong benchmarks to get on the map, and then move to models that are more precisely those that people want to use. Quoting from our Qwen 3 post:”We'll start to see if Qwen has taste/vibes. They have the benchmarks complete, and now we'll see how they compare to the likes of R1, o3, and Gemini 2.5 Pro for staying power at the frontier.”
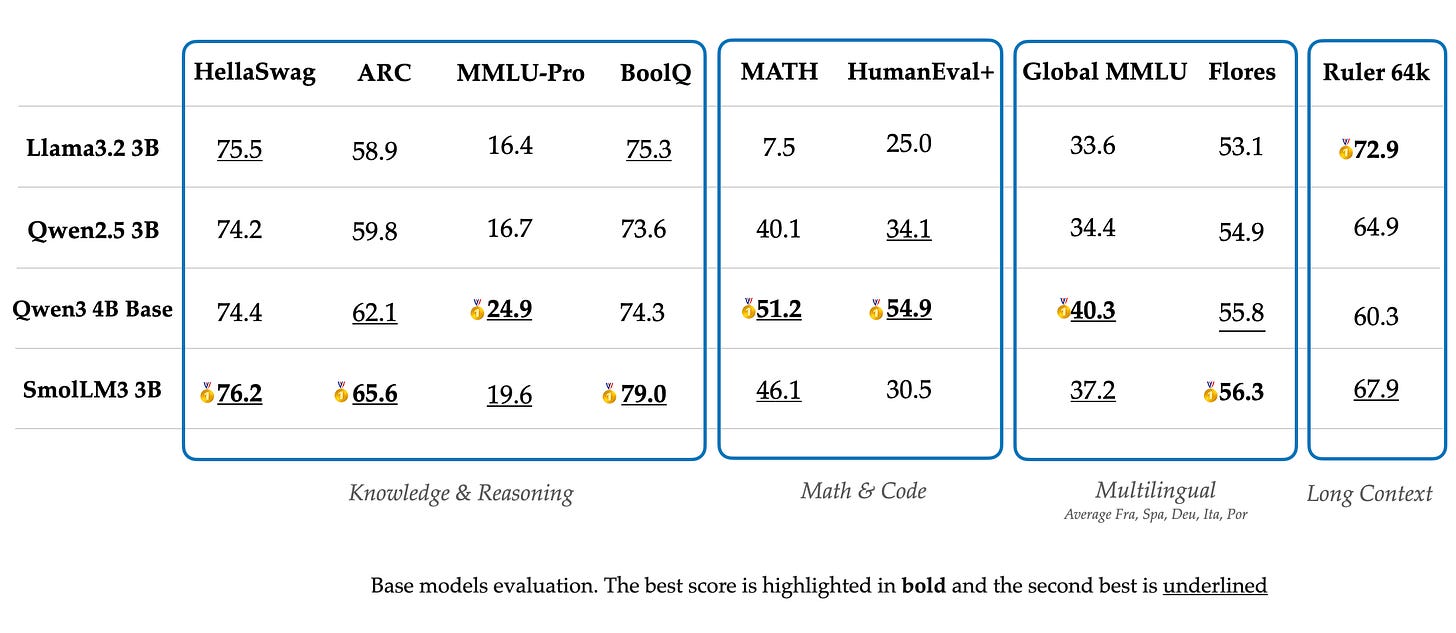
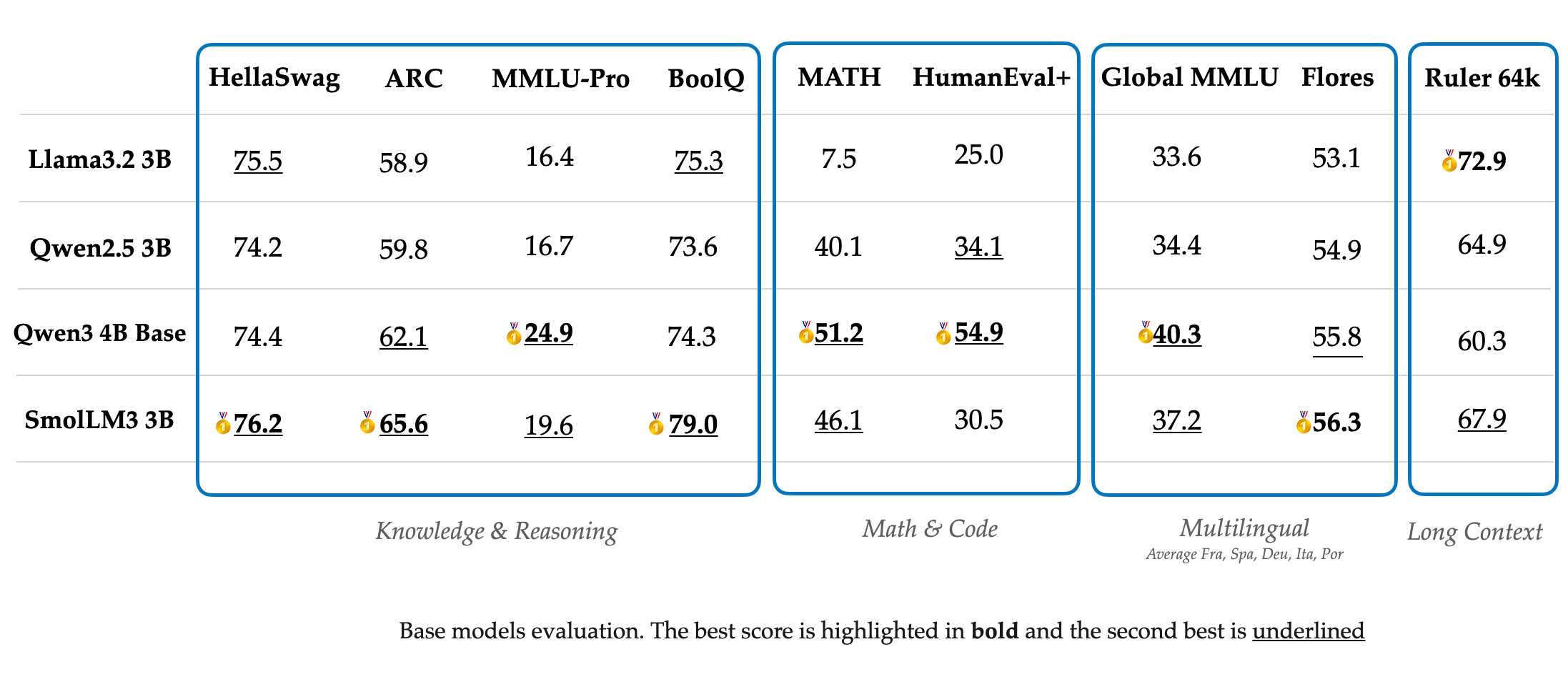
Qwen team members mentioned a new flagship thinking model is on the way and joked about coding models coming soon. The evaluation scores are below relative to other models without a <think> section. Again, as we mentioned in our Kimi K2 post, these models are trained extensively with reinforcement learning still, but the goals of the model are more constrained. These instruct, non-thinking, models are best for when the user wants a fast time-to-first token or other automation tasks.
The evaluation summary is here:

SmolLM3-3B by HuggingFaceTB: HuggingFace has released a new version of their SmolLM series alongside a very detailed writeup of all the decisions made, including details about all the used datasets. Similar to other models, it supports a thinking and non-thinking mode. We played around with it and were impressed by the quality, it really is a model on the level of the small Qwen3 models and comes with all artifacts released — one of the few “open-source” models today.
Kimi-K2-Instruct by moonshotai: It is hard to understate the impact of the model, which we've covered already. The new update is that they released a technical report today, with a bunch of nice methods, but nothing incredibly surprising. K2 has proven itself to be a capable model on various, unusual benchmarks, matching Opus on LMArena while becoming one of the most used models on OpenRouter.
FLUX.1-Kontext-dev by black-forest-labs: After the GPT-4o image release, a lot of people (especially on social media) claimed that omni models are the future and that specialized image models will be unable to catch up. Avid readers of the Artifacts series know that this is not the case, see Step1X Edit as an example. BFL has now released their editing model based on FLUX.1-Kontext-dev. Fun fact: FLUX.1-Kontext-dev is the model with the most fine-tunes / adapters on HuggingFace, despite its non-commercial license.
![FLUX.1 [dev] Grid](https://substackcdn.com/image/fetch/$s_!FFf9!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F5c10e668-30e3-444e-be74-a13cdde81dd3_2939x2100.png "FLUX.1 [dev] Grid")
Hunyuan-A13B-Instruct by tencent: Tencent releases both a 7B dense and a 80B total / 13B active MoE model. It also features 256K context, has very solid benchmark scores (including function calling). Aside from that, people actually use it and are impressed by it! We sound like a broken record, but Chinese labs and companies continue to outbid each other in the open model space with very solid models.
Edit: Unfortunately this model is up there in terms of bad licenses. A portion of it states: “You must not use, reproduce, modify, distribute, or display the Tencent Hunyuan Works, Output or results of the Tencent Hunyuan Works outside the Territory. Any such use outside the Territory is unlicensed and unauthorized under this Agreement.” Here, the territory is everywhere but the EU, UK, and SK.
![FLUX.1 [dev] Grid](https://substackcdn.com/image/fetch/$s_!FFf9!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F5c10e668-30e3-444e-be74-a13cdde81dd3_2939x2100.png "FLUX.1 [dev] Grid")
Models
Flagship
ERNIE-4.5-21B-A3B-PT by baidu: Baidu followed up on their promise to release their flagship model, ERNIE, in various sizes, both dense and MoE. The models are licensed under Apache 2.0. However, the model got mixed reactions on social media, with some people being surprised with the quality, while others are disappointed with its performance on tasks outside of usual benchmarks.
pangu-pro-moe-model by IntervitensInc: A MoE trained by the Huawei Pangu team on Ascend NPUs. However, the model release is overshadowed by allegations of them being upcycled DeepSeek / Qwen models.
EXAONE-4.0-32B by LGAI-EXAONE: LG also continues to release new models. This iteration adds a dual-thinking mode, a 3:1 local:global attention and a focus on tool calling. However, it is released under a noncommercial license.
General Purpose
Apriel-Nemotron-15b-Thinker by ServiceNow-AI: ServiceNow is also joining the ever-growing list of companies training their own reasoning models.
micro-g3.3-8b-instruct-1b by ibm-ai-platform: A 1B model building upon the 8B Granite model, featuring only 3 hidden layers.
DeepSeek-TNG-R1T2-Chimera by tngtech: The German TNG has thrown the new R1 into the model soup (because DeepSeek released an updated R1 model on May 28th), improving performance over the original Chimera model even further.

AI21-Jamba-Large-1.7 by ai21labs: An update to the hybrid SSM-Transformer model series from AI21.
FlexOlmo-7x7B-1T by allenai: A new model by Ai2, where different organizations can train experts on their data to improve a shared model. The blog provides more details about the model and its training process.
Phi-4-mini-flash-reasoning by microsoft: A hybrid model to speed up inference.
OctoThinker-3B-Hybrid-Zero by OctoThinker: The OctoThinker team has released a comprehensive paper about their mid-training process.
OpenReasoning-Nemotron-32B by nvidia: A new version of NVIDIA's reasoning model, using the same prompts as the previous version, but with traces generated by R1 0528.

Multimodal
Ovis-U1-3B by AIDC-AI: Another omni model by another subdivision of Alibaba.
GLM-4.1V-9B-Thinking by THUDM: An extension of zAI's GLM-9B-0414 to also support images as inputs. This is one of the longer-tail of very strong open weight model laboratories from China.

