

Stop "reinventing" everything to solve alignment
Integrating some non-computing science into reinforcement learning from human feedback (RLHF) can give us the models we want. Bonus: OLMo 1.7-7B.
Editors note: This week marks 1 year since the rebrand to Interconnects. Things are going great. I have so much to write about, engaged readers, and a few additions to the offerings.
The paid member discord is a wonderful small community that helps me spend less time on Twitter!
The audio of posts, created via 11Labs to sound just like me, for podcasts or in video on YouTube is becoming increasingly stable and has a solid, smaller audience.
The open models and datasets at the end of posts are getting consistent traction. When I find the right person, I want to move this into its own post series, but hang tight for now! And send me models!
Thank you for your continued support.
When solving alignment, particularly as it looks like reinforcement learning from human feedback (RLHF) is the leading tool to do so, we want to make sure we’re including opinions from people outside of the computer science academy. Reinventionism in computer science is one of the classic memes of the field — everyone knows there are only three problems or solutions academics reuse about once per decade in CS. When it comes to human problems, thankfully, we don’t need to invent new solutions for all the problems we’re facing. Many problems in the human feedback part of RLHF have existing fields of economics or other social sciences that have long-standing histories around solving one facet of it.
Broadly, people don’t really bat an eye when they see researchers like me reinventing best practices for PPO in the context of language models (relative to learning from scratch from control) because it doesn’t really matter. This week’s lesson was “Oh, PPO scales well with batch size, we knew this!” This type of thing is fine, and we’re in the early days of comparing the implementation details of the 2017 PPO to today’s RLHF. The problem arises when we carry this attitude into things where our tunnel vision solutions will not only limit our models but add further limitations to our models.
I’ve focused on reward models for a long time as the tool for transparency and auditing of the alignment process that people are ignoring. Reward models are the place in the process where a lot of the history and risks of RLHF converge to a particularly intriguing form of messiness. Reward models, because they’re often referred to as preference models, carry a ton of sociological weight in our framing. If we say we are learning a model of human preferences, that puts pressure on auditing bodies to ask “How so?”
As I discussed in my post where I described the different groups interested in the openness of LLMs, one of the core reasons for openness is so that scientists outside of AI, particularly outside of the biggest technology companies, can show that fields other than CS have contributions to make to the future of AI.
I so often get the question “What is left for academics to do in the space of LLMs?” This sort of thing is a perfect answer — study the emerging integration of two long-standing fields of science. Show that we can make the process for training our models more transparent with the goals, and then we can probably use it to actually make the models better.
Social Choice for AI Alignment: Dealing with Diverse Human Feedback
This is where my own personal mea culpa comes in: I had no idea there were entire subfields of economics, such as social choice theory, dedicated to understanding some of the core problems I’m interested in in the context of RLHF. I was invited to a workshop in December of 2023 on “Social Choice for AI Ethics and Safety,” in Berkeley and decided to go because some scientists I wanted to talk to would be there (e.g. Anca at Gemini and Hailey at Eleuther AI). I’m really glad I went, I was totally humbled at how much I was missing.
Social choice theory is defined by Wikipedia as
a branch of economics that analyzes mechanisms and procedures for collective decisions. Social choice incorporates insights from welfare economics, mathematics, and political science to find the best ways to combine individual opinions, preferences, or beliefs into a single coherent measure of well-being.
It has its traces as far back as 1299. It’s safe to say that most of the problems we’re worried about are just being re-cast in the context of computers. Social choice theory gives us many, many levers for redesigning reward models to be more intentional about how we are using preference data. It makes it clear at every step of the process that we are being intentional and adding potential bias to the system. Simple ideas from the modern RLHF data collection process, such as aggregating over multiple labels for one prompt-completion pair, expand into a much broader context.
To help encourage broader engagement in the AI alignment space, we wrote a white paper on how social choice theory can be integrated into RLHF practices. I won’t go into all the details, but I encourage you to get in touch if you’re interested. The core team is organizing another workshop where you can submit your work and get feedback.

I will go through the conceptual figures of the paper, as I think they can give readers a good idea of the sort of things we can consider changing in the standard RLHF process. Let’s start with some basic ideas in RLHF: who labels which prompt completions? Should we assign scores or rankings? Should multiple people label the same completion? Should the number of people per prompt be the same? All of these ideas can be studied from the angle of a social welfare function — “also called a social ordering, ranking, utility, or choice function—is a function that ranks a set of social states by their desirability.” What looks like an assumption in the RLHF process has an entire subfield around it.

Next, we can also zoom in on the idea of training a reward model. We know that our raters are all different people, so what if we collect features of the individual that labeled a preference and include them as inputs to the reward model? Given a human already labels every piece of data in the classic notion of RLHF, it shouldn’t be too much work to add a simple sign-in form to your collection interface. We can even look at how a group’s features would change a specific input, called cardinal reward modeling, which again derives from topics in social choice theory.
If we take this a step further, we can either simulate more user features at training time — sample over potential labelers — or even let users enter their features at inference time. This starts to lead to personalization, which is one of the final frontiers of alignment.
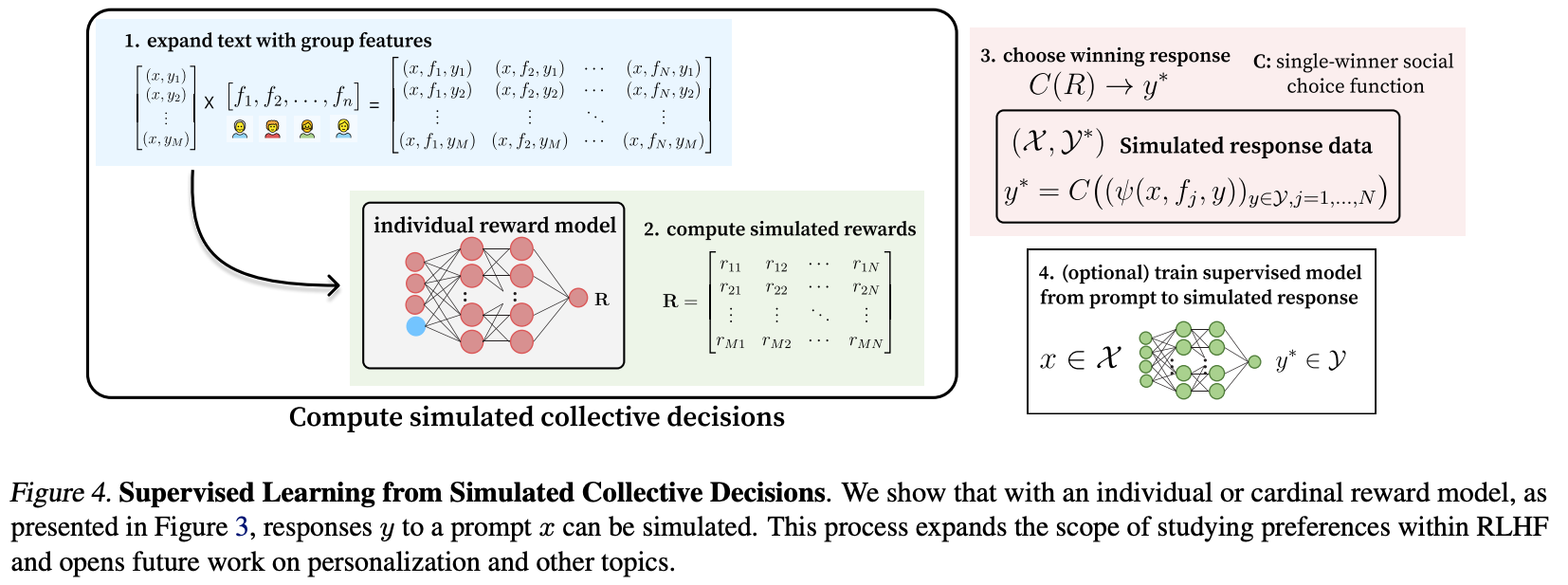
There’s a ton more to dig into in the paper, but I’m still learning it and don’t want to mislead anyone on the blog! Given that I was blindsided by this field, and I’m seen as a “leading figure in the alignment space” goes to show how much more we have to uncover. If you’re a social scientist reading Interconnects, speak up, and let me know what I’m missing. If you’re an alignment researcher, please take a look.
This group and work are far from the only people exploring this space. Recently, there was another position paper from a colleague of mine that addressed similar questions from a more technical angle. The paper, A Roadmap to Pluralistic Alignment, states the idea that “as a broader set of people use and rely upon AI systems, we need systems that can understand and cater to a broader set of needs.” It’s pretty obvious, and more specific to that personalization idea I mentioned above.
The authors propose a few ways to make AI systems and benchmarks more pluralistic. A summary from a colleague and author of the paper Nouha Dziri at AI2, edited for clarity:
Overton pluralistic models, which represent a spectrum of reasonable responses, synthesized into one response,
Steerably pluralistic models, which can be faithfully steered to reflect certain values, attributes, or perspectives,
Encourage pluralistic multi-objective benchmarks, and trade-off steerable benchmarks which encourage models to steer to trade-off objectives at inference time, and
Jury-pluralistic benchmarks, which explicitly model a population/jury to align to.
The breakdown here is much more tractable within the existing academic contexts of RLHF. This paper was also covered in Import AI 360 if you’re interested. I’m excited to see where all of this goes, as I see this style of work being most likely to mitigate some of the social bizarreness around reward models that I’m trying to address with Reward Bench.

OLMo 1.7-7B: A truly open model with actually good benchmarks
Today, we released a new version of OLMo 7B with some big data changes and minor additions of staged training (lowering the learning rate to 0 to converge to a nice local optimum). You can read more about the changes in the blog post here, but the big change is that we’re more compute efficient than Llama 2 models with totally open data and infrastructure. This bodes well for open models, even if we’re about 6-12 months behind when it comes to being 100% truly open. It’s going to be an exciting year!

Models, datasets, and other tools (2024 artifacts, 2023 artifacts)
T5 reproduction with open data from Eleuther AI is a big deal. T5 is a workhorse open model from Google, and reproducing old results with every part of the pipeline open goes a long way. reproduction!
WizardLM 2 was released, then removed because they “violated a release process.” I expect this to be close to the best open model in ChatBotArena (behind Cohere Command R+).
IDIFICS 2 — the next visual language model from HuggingFaceM4 is out. It looks really solid.
CodeQwen suite is out! Yay for more model options. Qwen has been solid for a while.
Links
DPO vs PPO paper came out, showing PPO is better, but I think the experiments are only okay. I agree with the core finding.
Housekeeping
Audio of this post is available (soon) in podcast form or on YouTube.
My real podcast is at retortai.com.
Paid subscriber Discord access in email footer.
Referrals → paid sub: Use the Interconnects Leaderboard.
Student discounts in About page.