Latest open artifacts (#16): Who's building models in the U.S., China's model release playbook, and a resurgence of truly open models
A month with SOTA releases with (truly) open model releases left and right.
This holiday season, remember you can give the gift of Interconnects (or reimburse your subscription with your company’s learning budget)!
Before we get to the coverage of many truly open models (Stanford’s Marin, Gaperon, Nathan’s Olmo3, etc.), many OCR models, and some frontier models from China’s AI Tigers, we wanted to share a simple list of the AI labs releasing serious open models in the U.S. This list is easily compiled from the backlog of these posts, but having it all in one place is very helpful with the surge of interest in both Chinese and American open model ecosystems.
Who’s building serious open models in the US
The U.S. has a comparable number of labs releasing high quality models as China (which is ~20 labs), but many American labs are releasing smaller models with more restrictive licenses, resulting in a far more muted impact. This list includes each notable recent model from them. All of these are pretrained by U.S. companies. To start, the clear players, listed alphabetically:
Ai2 — Olmo: Open-source leader, to date fully open, smaller dense models mostly. E.g. Olmo 3 32B Think, the best fully open reasoning model (and best fully open LM ever made). Always developer friendly Apache 2.0 licenses.
Arcee / Datology / Prime Intellect — Trinity: Newer startup fully committed to this. Range of MoE models, Apache 2.0 coming soon.
Google — Gemma: One of the most consistent players. To date models have been smaller and dense as well. E.g. VaultGemma 1B. Often solid custom licenses, sometimes minor downstream use restrctions.
HuggingFace — SmolLM: Tiny models, fully open, great community. E.g. SmolLM3-3B.
IBM — Granite: Small to medium sized models, underrated, strong and consistent releases. E.g. Granite-4.0-h-1b with a new hybrid-attention architecture. Developer friendly Apache 2.0 licenses.
Liquid AI — Liquid Foundation Models: Hybrid architecture, solid small models. .g. LFM2-VL-3B, their first vision-language models. Very similar licenses to Apache 2.0, but with restrictions on companies making $10M per year or more.
Microsoft — Phi (+ others): Solid models, can go under the radar, but consistent. E.g. Phi-4-mini-flash-reasoning, a small reasoning model. Often fairly permissive licenses too, e.g. MIT.
Moondream — Moondream Models: Solid vision models, originally on device, but dominant and consistent in their niche. E.g. Moondream3. Solid licenses and very engaged in community feedback, e.g. recently made it clear synthetic data use is okay.
Nvidia — Nemotron: Arguably the open leader in the U.S. after Llama 4. E.g. Nemotron Nano 9B v2, a 9B model matching or surpassing Chinese models in that size range. Increasingly open licenses recently, including more open data releases.
OpenAI — GPT OSS: A new entrant but incredibly important they’re involved. E.g. gpt-oss-120b, OpenAI’s first open weights language model since GPT-2. Good Apache 2.0 licenses, we hope they continue releasing more models.
Reflection — TBD: but if you can convince someone you’re worth $2B to do this, I believe you.
ServiceNow — Apriel: Solid reasoning models and other contributions. E.g. Apriel-H1-15b-Thinker.
Stanford University — Marin Community Models: A new entrant in fully-open models like Ai2, scaling up after releasing their first 30B base model. We hope they have strong post-training soon!
Of the above, we’re watching Ai2, Nvidia, Arcee, and Reflection the closest, as the players with the most mind-share and momentum on the ground.
Unclear: Companies making fewer contributions currently but have in the past.
Meta — Llama: The original, but priorities are changing. Crickets since the Llama 4 fiasco.
Reka — Flash: A few solid models, no updates in a bit.
xAI — Grok: Many promises of releasing past models, yet to be useful to the community.
This is a list of groups making solid language models in the U.S. Other labs that would easily be included in a more “Western” ecosystem list would include the likes of Cohere (with solid models, though normally non-commercial licenses), Mistral (with smaller models, normally Apache 2.0), and AI21 labs. There are other types, such as multimodal generation models and biology-focused models that are massive breakthroughs but not listed.
Download this U.S. model maker list as a PDF below:
In case you weren’t aware: Paid subscribers get access to the members-only Discord, which not only hosts an active community, but also bots covering even more releases in real-time. It also gives a glimpse into the current work and experiments of many labs who (briefly) forget to set their models to private. An example is below. Sometimes we say this is the best perk you get for upgrading to paid — consider it!
Artifacts Log
Our Picks
MiniMax-M2 by MiniMaxAI: Probably one of the surprise releases this month: Minimax, whose previous models were usually behind the claimed performance, really took a leap forward with M2, putting them squarely into the spotlight. They also speedrun the (Chinese) model release playbook, something we observed in the past and was perfected by the likes of Alibaba (Qwen), Moonshot (Kimi) and Zhipu (GLM):
Build a social media presence, mainly on Twitter. This increasingly means that researchers are also active aside from the corporate / brand accounts.
Release a new model with (Western) launch partners and ecosystem support on day zero, from vLLM to OpenRouter and tools like Cline. To really get it off the ground, offer free access to the API for a limited time.
Offer a coding subscription which is compatible with Claude Code (or fork a CLI) while undercutting their pricing.
Develop your own tooling and train the next model to work even better with it.
This strategy, of course, is working: Zhipu reportedly has over 100K international API users and 3M chatbot users.
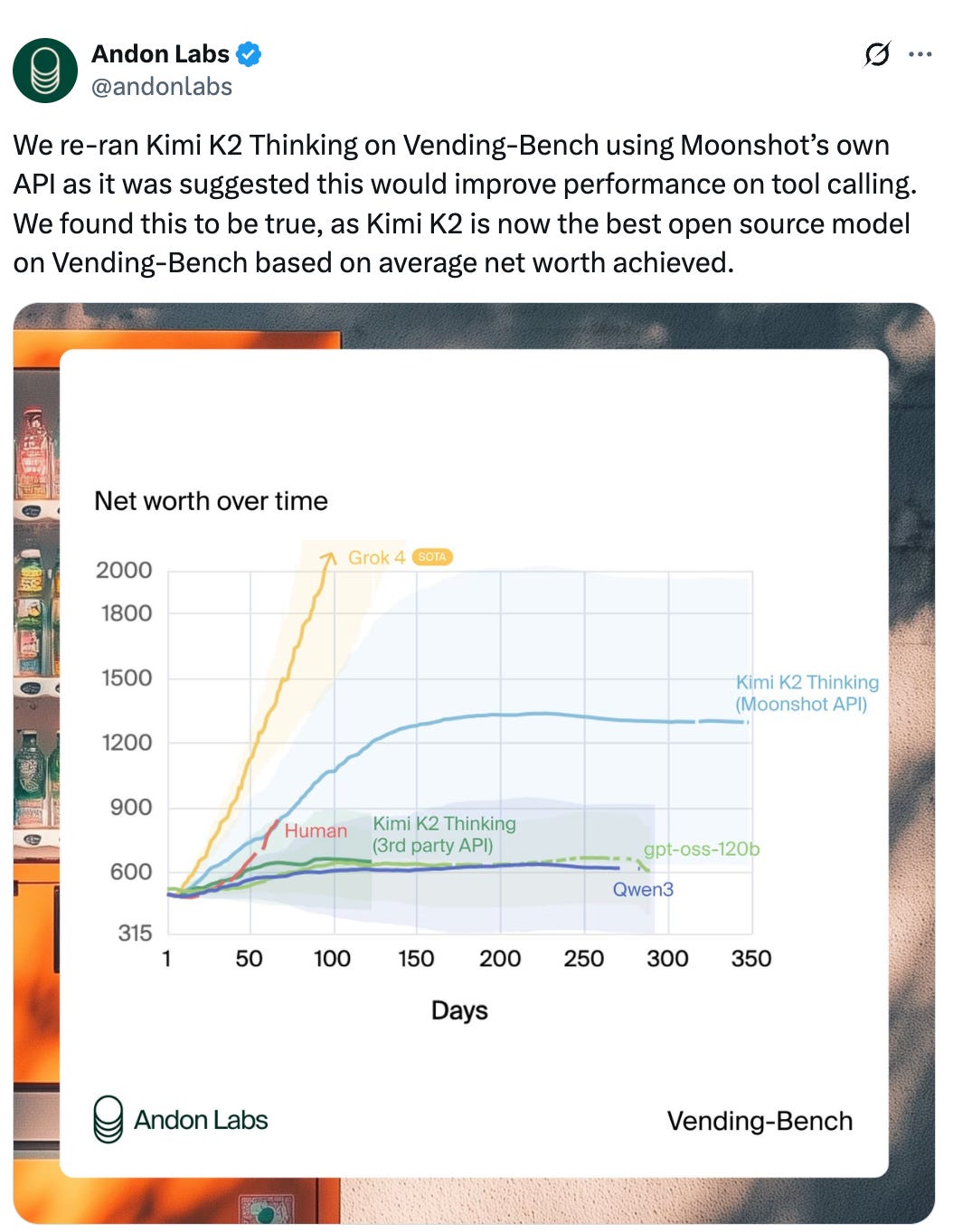
Kimi-K2-Thinking by moonshotai (more coverage here): The best open model, competitive with some of the best closed models. However, independent evaluation is a problem as third-party API providers struggle to implement the model correctly, something which we have seen, for example, with the release of GPT-OSS. As an example, running the agentic “Vending-Bench” from Andon Labs with a third party provider as opposed to the official API makes a huge difference:
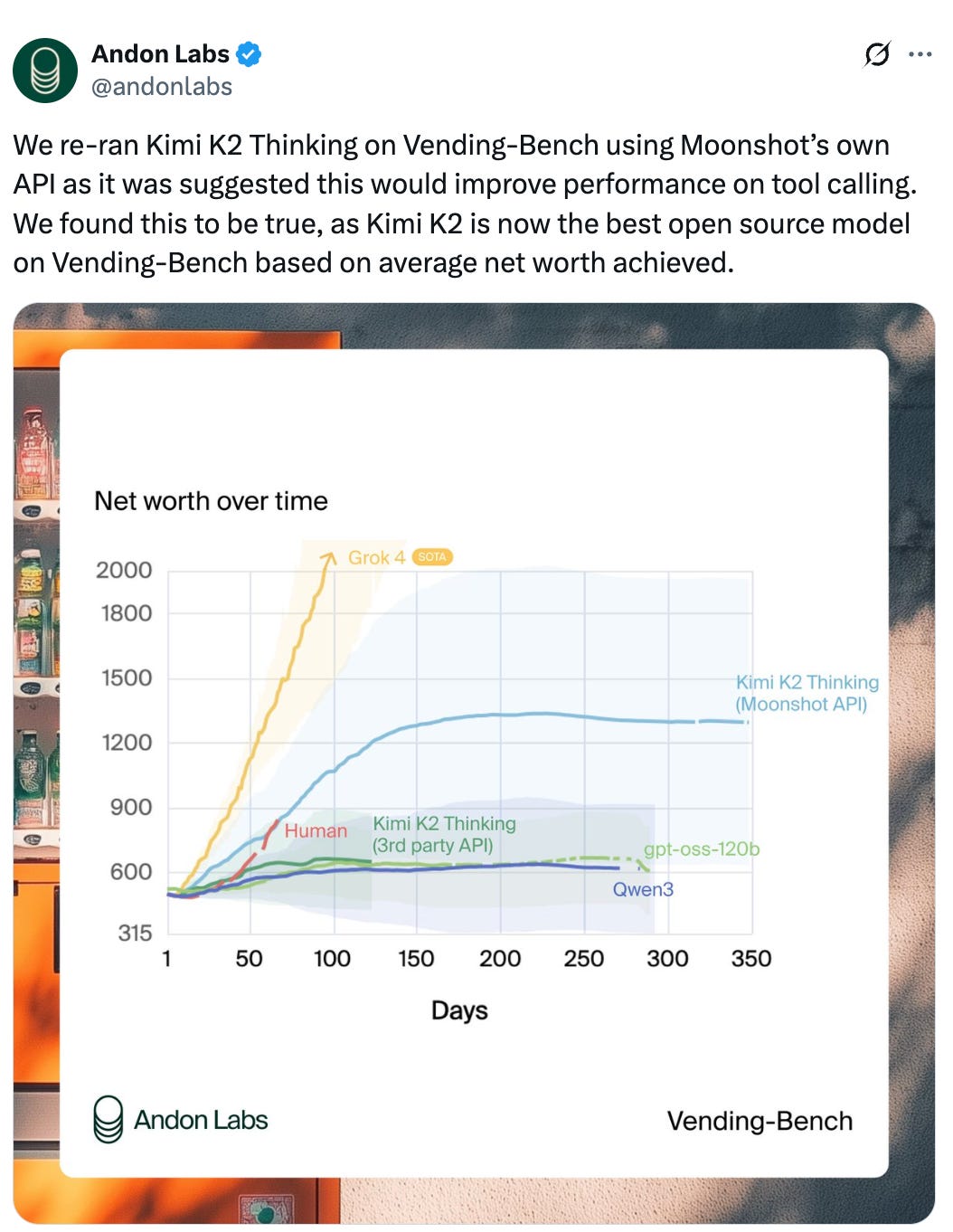
This is a huge problem plaguing open models. Moonshot also documents the tool calling accuracy in a repo, where a lot of providers perform sub-par, including vLLM with a schema accuracy <90%.
Qwen3-VL-32B-Instruct by Qwen: The 2B and 32B version of Qwen3 also get an update. Similar to the 8B version covered in last month’s artifact, the 32B vision model has better text benchmark scores than the initial release of the 32B text-only model.
Olmo-3-32B-Think by allenai: A series of truly open models, covering everything from data to all models from the model flow. In case you somehow missed it, check out the coverage of the model:

Models
Flagship
granite-4.0-h-1b by ibm-granite: Of course, IBM can’t stop training tiny models and to add them to their model families. The new Granite models feature hybrid attention and MoE architecture first time.
marin-32b-base by marin-community: A truly open model by Percy Liang’s Marin.
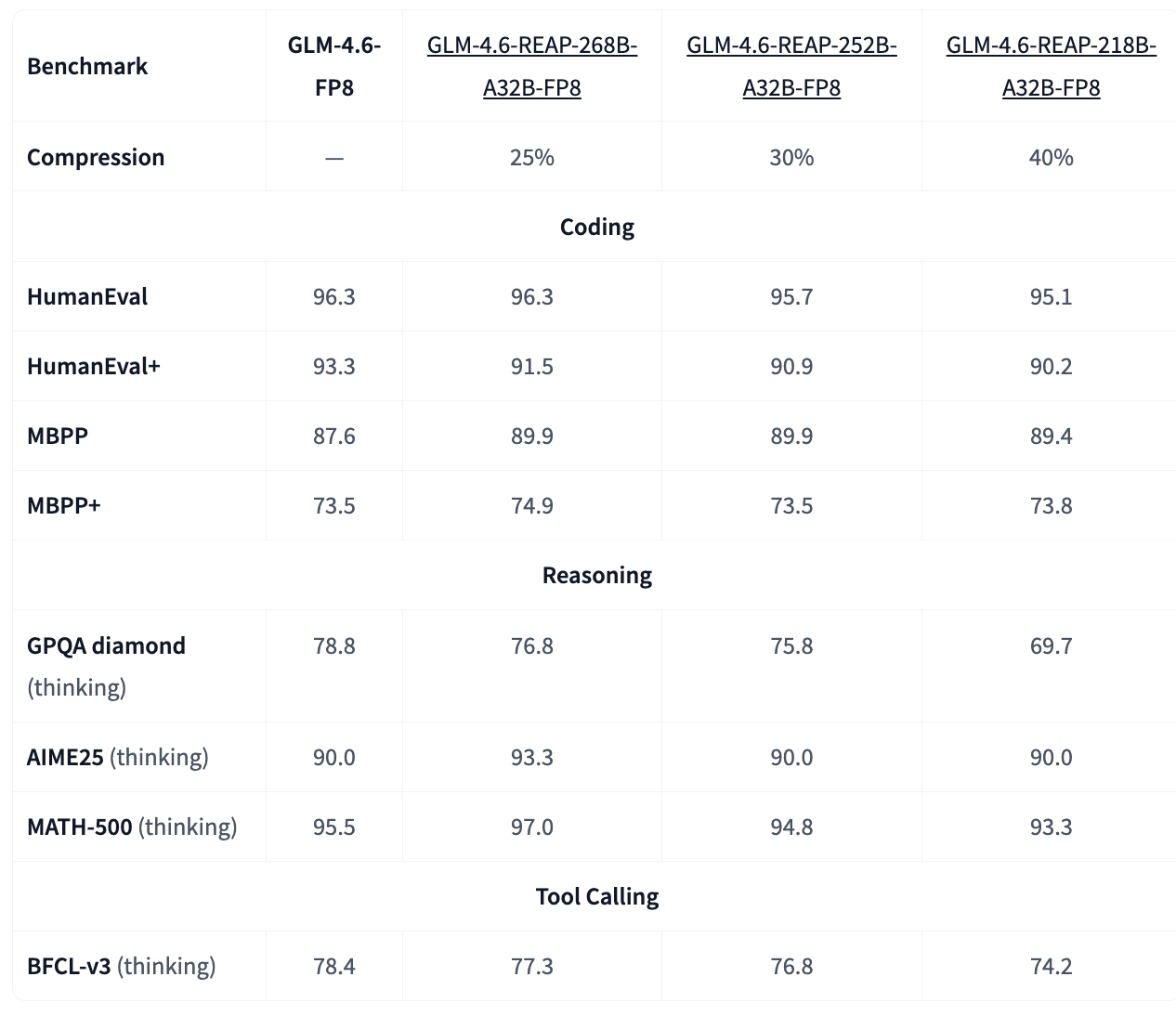
GLM-4.6-REAP-218B-A32B-FP8 by cerebras: While we wait for GLM-4.6-Air (and mini, as teased in this Interview from Chinatalk’s Jordan Schneider and Nathan with Zixuan Li from Zhipu), you can use pruned versions of the GLM-4.6 model.