

2025 Interconnects year in review
Three years writing every week about AI.
A lot has happened in AI this year, which is the new normal. Since I last wrote a year in review, before going on Lex’s Podcast and writing timely coverage of the DeepSeek models, the Interconnects audience was below 20K readers. It’s more than doubled this year in viewership (and influence), so it’s a good time to reintroduce how I see the value in Interconnects to everyone.
My main day job is being deep in the weeds of the research needed to train better Olmo models. Interconnects serves as an outlet for these ideas to help me stay on top of having an elite vision and plan for said research.
The best way to view my content is a raw expression of my worldview as a leading AI researcher reacting to the world of AI. A lot of my writing is raw, sometimes off the cuff, and often technical. I lean into this as it gives readers a very cutting-edge view of my thinking, which often can translate into the unique feeling of “getting it” at the cutting-edge of research.1
One of my favorite things while wrapping up the year is I’m regularly using three frontier models (ChatGPT, Claude, & Gemini) for slightly different things. The landscape is as competitive as it ever has been. These products I love are also facing serious pressure from open models close on their heels. In 2026 I want to use more open models directly.
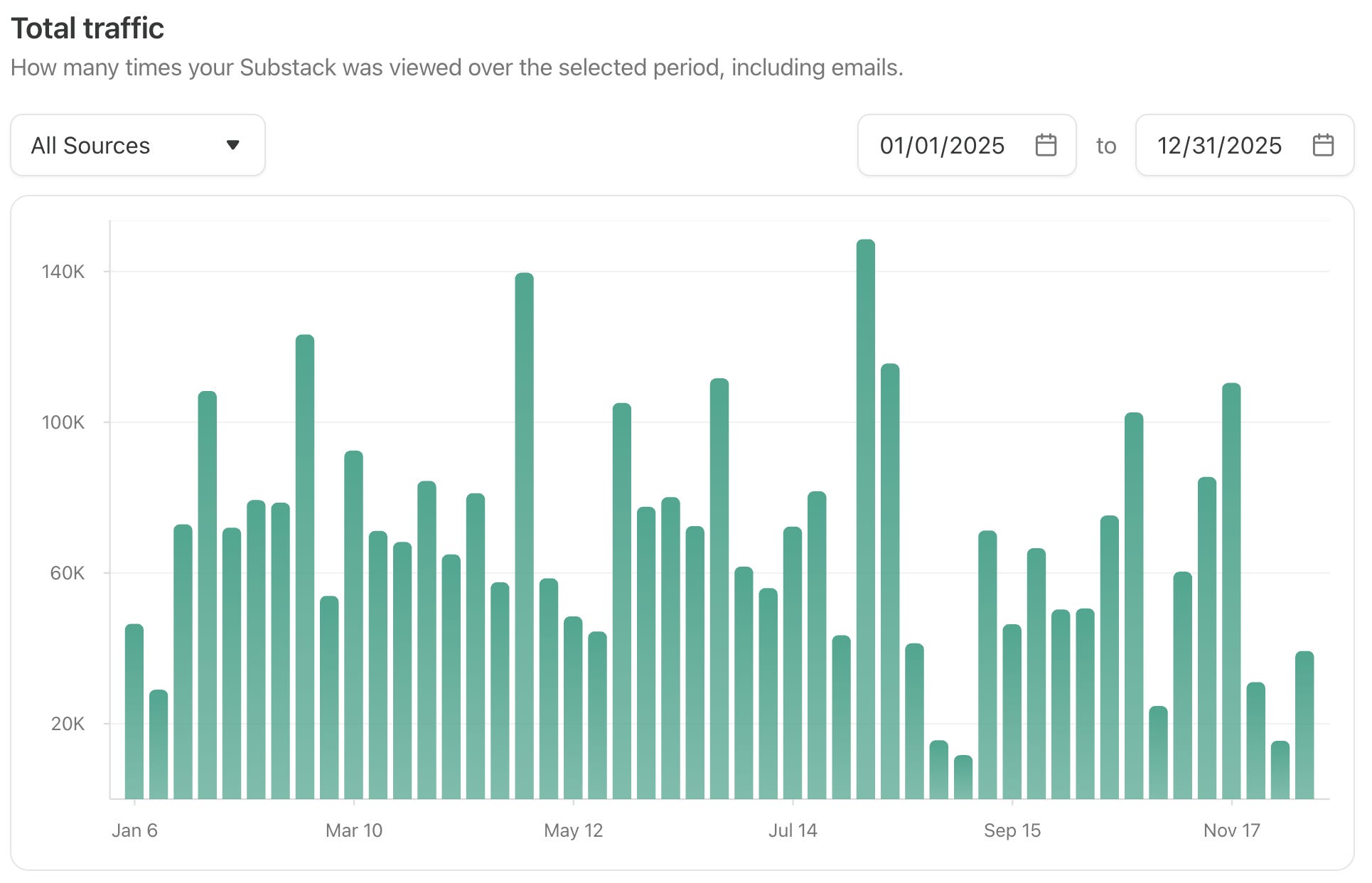
This year brought my long-term focuses of reinforcement learning and open models to the forefront of the entire AI ecosystem, so it makes sense that it was the busiest year on Interconnects yet. Through 2025, there were 80 total posts of which 19 were for prominent model releases, 11 were our roundups of open models (Artifacts Log), 4 interviews, 6 of my talks, and the remaining 40 spread across analysis of the world of AI. In total I earned about 3.5 million pageviews on Substack.
This is well over my goal of one per week and likely will be a local optimum over this few-year phase of AI where I’m working full-time on research, with a major side gig in the AI media and policy spheres. I don’t expect there to be another increase in year-over-year amount of content, but we should be able to make every piece of content even more valuable. We’re learning a lot.
It’s arguable that I’m burning out this year, but with how motivated and aligned I am to my work, it feels more like just hitting hard limits. I can’t do everything. I’m lucky to have a life where I can shape a lot of my time, energy, habits, and goals around shaping trends in AI. Working at the Allen Institute for AI has been great for this, but they should be because they obviously benefit a lot from my work too.
I’m tired but feeling very content with my contributions to the AI world. I still think this is the early years of my work and getting the right practice in is more important to me than perfection of every piece. If you can, upgrading a paid subscription helps me pay for AI tools or operational assistance and just helps me stay motivated in the project (plus, you get access to the excellent Discord Server too).
This year I launched two major projects that are closely intertwined with my goals for Interconnects: The ATOM Project, the case for immediate investment in centers building American open models, and the SAIL Bundle, a paid bundle of my favorite writers on Substack sold only to teams (we’ve started publishing a bunch of content on the SAIL YouTube channel). I intend to invest further in both of these in 2026, so you’ll keep hearing about these. It is a risk to invest so much time in these things, so it’s a relief when they land.
I’ll see you all in January. We have no planned content until then, but we’d chime in if DeepSeek V4 (or an equivalent) comes out and is causing international ripples. I’m off to finish up my RLHF book, which you should pre-order in print now!
Previous years in review: 2024 | 2023
You can see the weekly views this year below.
In this post I’ve organized all the posts of the year into sections. Throughout, I’ve marked my favorite posts with ★ if you’re looking to catch up on what I felt is the mostly lasting content from the year.
Comment below what your favorite posts were or any topic you wish I covered more. Contents:
Of all the sections I listed, the subsection of Analysis posts on Reasoning & RL is my highlight for the year. The average quality there is excellent, especially given how much uncertainty and confusion exists when new paradigms emerge.
Of all the posts, 26 of them directly cover or discuss the role of Chinese open models on the AI ecosystem, which will surely continue into 2026 (hint: We already have some great interviews lined up or recorded).
Top Posts (by pageviews)
Top 11 posts as of Friday Dec. 12th 2025, and the only ones to clear 50K pageviews are:
DeepSeek V3 and the actual cost of training frontier AI models — 62.6K: Why the cost of training models go well beyond the GPU hours for the final model.
DeepSeek R1’s recipe to replicate o1 and the future of reasoning LMs — 61.3K: How to train a frontier model to reason.
5 Thoughts on Kimi K2 Thinking — 59K: Reflections on the state of frontier open models at the end of the year.
Burning out — 57.8K: How the AI industry is pushing people too far to try and stay relevant.
Coding as the epicenter of AI progress — 56.3K: Why coding is the best place to feel current progress on models.
GPT-4.5: “Not a frontier model”? — 55.4K: Why a large, slow model was seen as a failure by OpenAI.
OpenAI’s o3: Over-optimization is back and weirder than ever — 54.7K: How large scale RL changed the nature of hallucinations in models.
GPT-5 and the arc of progress — 54.5K: How GPT-5 confirms my worldview of slow, consistent progress over the next few years.
xAI’s Grok 4: The tension of frontier performance with a side of Elon favoritism — 51.7K: Reflecting on xAI’s technical excellence while being baffled by their weird modeling decisions.
Qwen 3: The new open standard — 51.7K: Why Qwen’s models are great for research.
The American DeepSeek Project — 51.4K: My next set of goals for my career.

Model Releases & Reviews
Jan. 09: DeepSeek V3 and the actual cost of training frontier AI models
★ Jan. 21: DeepSeek R1’s recipe to replicate o1 and the future of reasoning LMs
Feb. 24: Claude 3.7 thonks and what’s next for inference-time scaling
Feb. 28: GPT-4.5: “Not a frontier model”?
Mar. 13: Gemma 3, OLMo 2 32B, and the growing potential of open-source AI
Mar. 30: GPT-4o’s images and lessons from native input-output multimodality
Apr. 14: OpenAI’s GPT-4.1 and separating the API from ChatGPT
★ Apr. 19: OpenAI’s o3: Over-optimization is back and weirder than ever
Apr. 28: Qwen 3: The new open standard
May. 27: Claude 4 and Anthropic’s bet on code
Jul. 12: xAI’s Grok 4: The tension of frontier performance with a side of Elon favoritism
Aug. 05: gpt-oss: OpenAI validates the open ecosystem (finally)
Aug. 07: GPT-5 and the arc of progress
Nov. 06: 5 Thoughts on Kimi K2 Thinking
Interconnects Interviews
Jan. 22: Interviewing OLMo 2 leads: Open secrets of training language models
Mar. 12: Interviewing Eugene Vinitsky on self-play for self-driving and what else people do with RL
My Talks
Jan. 02: Quick recap on the state of reasoning — now outdated for sure.
Jan. 08: The state of post-training in 2025
★ Feb. 13: An unexpected RL Renaissance
★ Jun. 18: Crafting a good (reasoning) model
★ Oct. 16: The State of Open Models
Dec. 10: New Talk: Building Olmo 3 Think

The Rest: Analysis
Reasoning & RL
★ Jan. 28: Why reasoning models will generalize
Mar. 05: Where inference-time scaling pushes the market for AI companies
Mar. 31: Recent reasoning research: GRPO tweaks, base model RL, and data curation
Apr. 05: RL backlog: OpenAI’s many RLs, clarifying distillation, and latent reasoning
★ May. 27: Reinforcement learning with random rewards actually works with Qwen 2.5
★ Jun. 04: A taxonomy for next-generation reasoning models — Skills, calibration, strategy, and abstraction.
Jun. 09: What comes next with reinforcement learning — On scaling and the challenges of sparser, long-horizon RL.
★ Jun. 12: The rise of reasoning machines — Contra the haters of language models who ground their arguments in human reasoning.
★ Sep. 22: Thinking, Searching, and Acting — The three primitives of reasoning models.
★ Oct. 20: How to scale RL — Reviewing the one substantive scaling RL paper of the year.
Life, Writing, & My Approach
★ May. 14: My path into AI
Jun. 06: How I Write
★ Oct. 25: Burning out
Nov. 16: Why AI writing is mid
Open-source AI
May. 06: What people get wrong about the leading Chinese open models: Adoption and censorship
★ Jul. 04: The American DeepSeek Project
Jul. 23: The White House’s plan for open models & AI research in the U.S.
Aug. 04: Towards American Truly Open Models: The ATOM Project — The rebranded and expanded American DeepSeek project.
★ Aug. 17: Ranking the Chinese Open Model Builders — Research on all the labs building good models in China.
Sep. 09: On China’s open source AI trajectory
Dec. 14: 2025 Open Models Year in Review

The Rest
★ Feb. 12: Deep Research, information vs. insight, and the nature of science
Feb. 26: Character training: Understanding and crafting a language model’s personality
Mar. 10: Elicitation, the simplest way to understand post-training
★ Mar. 19: Managing frontier model training organizations (or teams)
Apr. 30: State of play of AI progress (and related brakes on an intelligence explosion)
★ May. 04: Sycophancy and the art of the model
May. 21: People use AI more than you think
Jun. 21: What I’ve been reading (#1)
Jun. 23: Some ideas for what comes next
Jun. 28: Ilya on deep learning in 2015
★ Aug. 15: Contra Dwarkesh on Continual Learning
Sep. 18: Coding as the epicenter of AI progress and the path to general agents
Sep. 30: ChatGPT: The Agentic App
Oct. 07: Thoughts on The Curve
Artifacts Logs: Open Model Roundups
Jul. 22: Latest open artifacts (#12): Chinese models continue to dominate throughout the summer 🦦
Aug. 11: Latest open artifacts (#13): The abundance era of open models
Sep. 11: Latest open artifacts (#14): NVIDIA’s rise, “Swiss & UAE DeepSeek,” and a resurgence of open data

I shouldn’t have to explain why being a bit ahead in the trends of AI research should be valuable.
Congrats on a huge year Nathan. I've listened to the Lex podcast with you and Dylan at least 4 times, and I'm a paid subscriber of interconnects, and I've preordered the hard copy of your book (the international shipping cost more than the book FYI...).
I still have a big gap to close in my understanding of training models but your commitment to continually publishing in your own voice is lifting up the entire industry. Looking forward to a great year ahead, rest up.
Congrats on a strong year @Nathan!